可以通过perf list命令来查看系统中的software event:
1 | # simpleperf list sw |
1、原理介绍:
software pmu的trace数据抓取分为两类:“cpu-clock”、“task-clock”为采样法,其他为插桩法。
1 | enum perf_sw_ids { |
1.1、插桩法
插桩法的software event和tracepoint event本质上是一样的,只是tracepoint event是复用trace_event,而software event是重新创建的插桩点。
- 1、“page-faults”的插桩点:
el0_sync() -> el0_da() -> do_mem_abort() -> do_mem_abort() -> do_page_fault():
1 | static int __kprobes do_page_fault(unsigned long addr, unsigned int esr, |
- 2、“context-switches”的插桩点:
context_switch() -> prepare_task_switch() -> perf_event_task_sched_out():
1 | static inline void perf_event_task_sched_out(struct task_struct *prev, |
- 3、“cpu-migrations”的插桩点:
context_switch() -> finish_task_switch() -> perf_event_task_sched_in():
1 | static inline void perf_event_task_sched_in(struct task_struct *prev, |
- 4、“minor-faults”&“major-faults”的插桩点:
el0_sync() -> el0_da() -> do_mem_abort() -> do_mem_abort() -> do_page_fault():
1 | static int __kprobes do_page_fault(unsigned long addr, unsigned int esr, |
- 5、“alignment-faults”的插桩点:
arm64没有插桩点
- 6、“emulation-faults”的插桩点:
cp15barrier_handler():
1 | static int cp15barrier_handler(struct pt_regs *regs, u32 instr) |
1.2、采样法
采样法是间隔多少事件去采样,事件可以是指令数、时间、cache miss次数等。一般使用专门的硬件pmu来采样,“cpu-clock”、“task-clock”使用软件的hrtimer来采样。
在硬件PMU不支持的情况下,也可以参考hrtimer的采样值。
2、event init
2.1、”software”
1 | static struct pmu perf_swevent = { |
对应初始化函数:
1 | static int perf_swevent_init(struct perf_event *event) |
这里的核心是一个默认256大小的hash链表,稍后会根据(type+config)的hash键值把event链接进去。
1 | #define SWEVENT_HLIST_BITS 8 |
2.2、“cpu-clock”
1 | static struct pmu perf_cpu_clock = { |
对应初始化函数:
1 | static int cpu_clock_event_init(struct perf_event *event) |
2.3、“task-clock”
1 | static struct pmu perf_task_clock = { |
对应初始化函数:
1 | static int task_clock_event_init(struct perf_event *event) |
3、event add/del
在上一章“perf_event内核框架”中已经阐明,task维度的perf_event需要和task一起调度,其回调函数最后控制的就是perf_event的启动和停止。
- start函数调用路径:context_switch() -> finish_task_switch() -> perf_event_task_sched_in() -> __perf_event_task_sched_in() -> perf_event_context_sched_in() -> perf_event_sched_in() -> ctx_sched_in() -> ctx_pinned_sched_in()/ctx_flexible_sched_in() -> group_sched_in() -> event_sched_in() -> pmu->add(event, PERF_EF_START) -> xxx_add():
- stop函数调用路径:context_switch() -> prepare_task_switch() -> perf_event_task_sched_out() -> __perf_event_task_sched_out() -> perf_event_context_sched_out() -> ctx_sched_out() -> group_sched_out() -> event_sched_out() -> pmu->del() -> xxx_del():
3.1、”software”
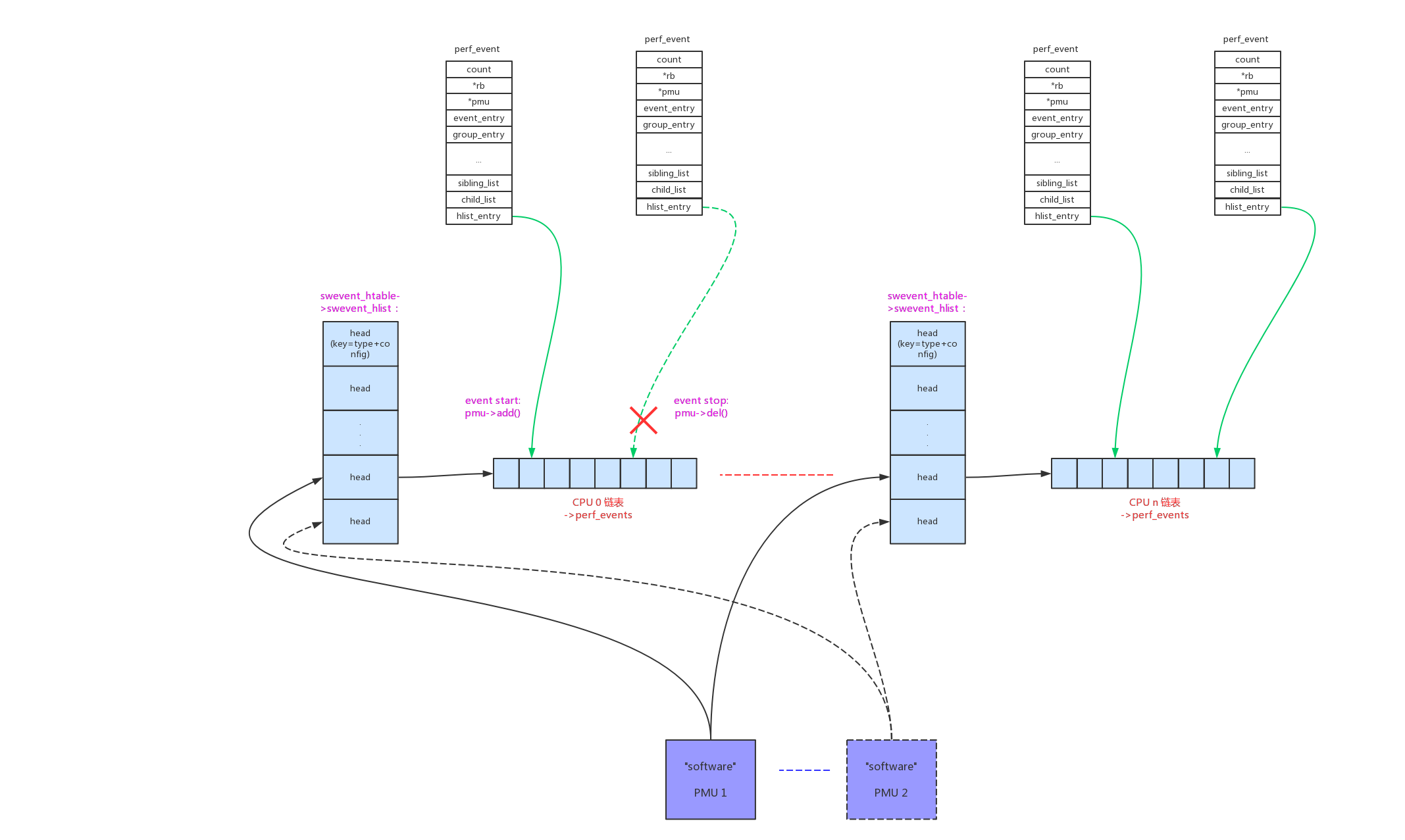
这种模式下,控制”software”event的启动和停止,实际上就是把event加入/移除到hash链表上。
- perf_swevent_add():
1 | static int perf_swevent_add(struct perf_event *event, int flags) |
- perf_swevent_del():
1 | static void perf_swevent_del(struct perf_event *event, int flags) |
3.2、“cpu-clock”
每个event一个独立的hrtimer,所有就没有什么链表之类的了。
- cpu_clock_event_add():
1 | static int cpu_clock_event_add(struct perf_event *event, int flags) |
hrtimer到期后的执行函数为perf_swevent_hrtimer(),它会定期的上报sample数据。
1 | static enum hrtimer_restart perf_swevent_hrtimer(struct hrtimer *hrtimer) |
- cpu_clock_event_del():
1 | static void cpu_clock_event_del(struct perf_event *event, int flags) |
3.3、“task-clock”
“task-clock”和“cpu-clock”基本一致,只是它计算的count值是event所在context time的差值。
- task_clock_event_add():
1 | static int task_clock_event_add(struct perf_event *event, int flags) |
- task_clock_event_del():
1 | static void task_clock_event_del(struct perf_event *event, int flags) |
4、event 数据采集
4.1、”software”
在插桩点被触发后,累加count数据,并且上报sample数据。以“context-switches”为例:
context_switch() -> prepare_task_switch() -> perf_event_task_sched_out():
1 | static inline void perf_event_task_sched_out(struct task_struct *prev, |
4.2、“cpu-clock”
- 在del()操作时,计算count差值:
cpu_clock_event_del() -> cpu_clock_event_stop() -> cpu_clock_event_update():
1 | static void cpu_clock_event_update(struct perf_event *event) |
- 在hrtimer中,定时上报sample数据:
1 | static enum hrtimer_restart perf_swevent_hrtimer(struct hrtimer *hrtimer) |
4.3、“task-clock”
在del()操作时,计算count差值:
task_clock_event_del() -> task_clock_event_stop() -> task_clock_event_update():
1 | static void task_clock_event_update(struct perf_event *event, u64 now) |
在hrtimer中,定时上报sample数据:
1 | static enum hrtimer_restart perf_swevent_hrtimer(struct hrtimer *hrtimer) |