perf复用了ftrace中trace_event的所有插桩点(即tracepoint),trace数据即可以通过ftrace的通道提供,也可以被包装成perf_event供perf工具使用。
可以通过perf list命令来查看系统中的tracpoint event,可以看到和/sys/kernel/debug/tracing/events/路径下的trace_event一致:
1 | # simpleperf list tracepoint | more |
1、原理介绍:
trace_event在定义的时候,已经把trace_point、trace_event的callback函数、perf_event的callback函数全都给定义好了。只需要使用现成的架构把perf_event的callback函数给注册到trace_point上去就行了。
include/trace/trace_event.h:
1 | /* (1) trace_event_class的定义 */ |
_TRACE_PERF_INIT()宏的展开:
1 | #ifdef CONFIG_PERF_EVENTS |
继续追踪perf_event的回调函数,include/trace/perf.h:
1 | #undef DECLARE_EVENT_CLASS |
我们接下来看一下详细的过程和数据格式。
2、event init
tracepoint pmu的定义如下:
1 | static struct pmu perf_tracepoint = { |
在调用perf_event_open()系统调用创建新的perf_event的时候,会调用到pmu->event_init()函数。
perf_event_open() -> perf_event_alloc() -> perf_init_event() -> perf_try_init_event() -> pmu->event_init(event) -> perf_tp_event_init():
1 | static int perf_tp_event_init(struct perf_event *event) |
tp_event->class->reg()函数在trace_event_class定义时,已经确定为trace_event_reg()函数:
1 | int trace_event_reg(struct trace_event_call *call, |
经过上述初始化注册以后,perf_event的callback函数已经插入到tracepoint中。此时如果tracepoint被命中,perf_event的callback函数会被调用,但是trace数据无人接收,因为tp_event->perf_events链表中还没有接收的perf_event。
3、event add/del
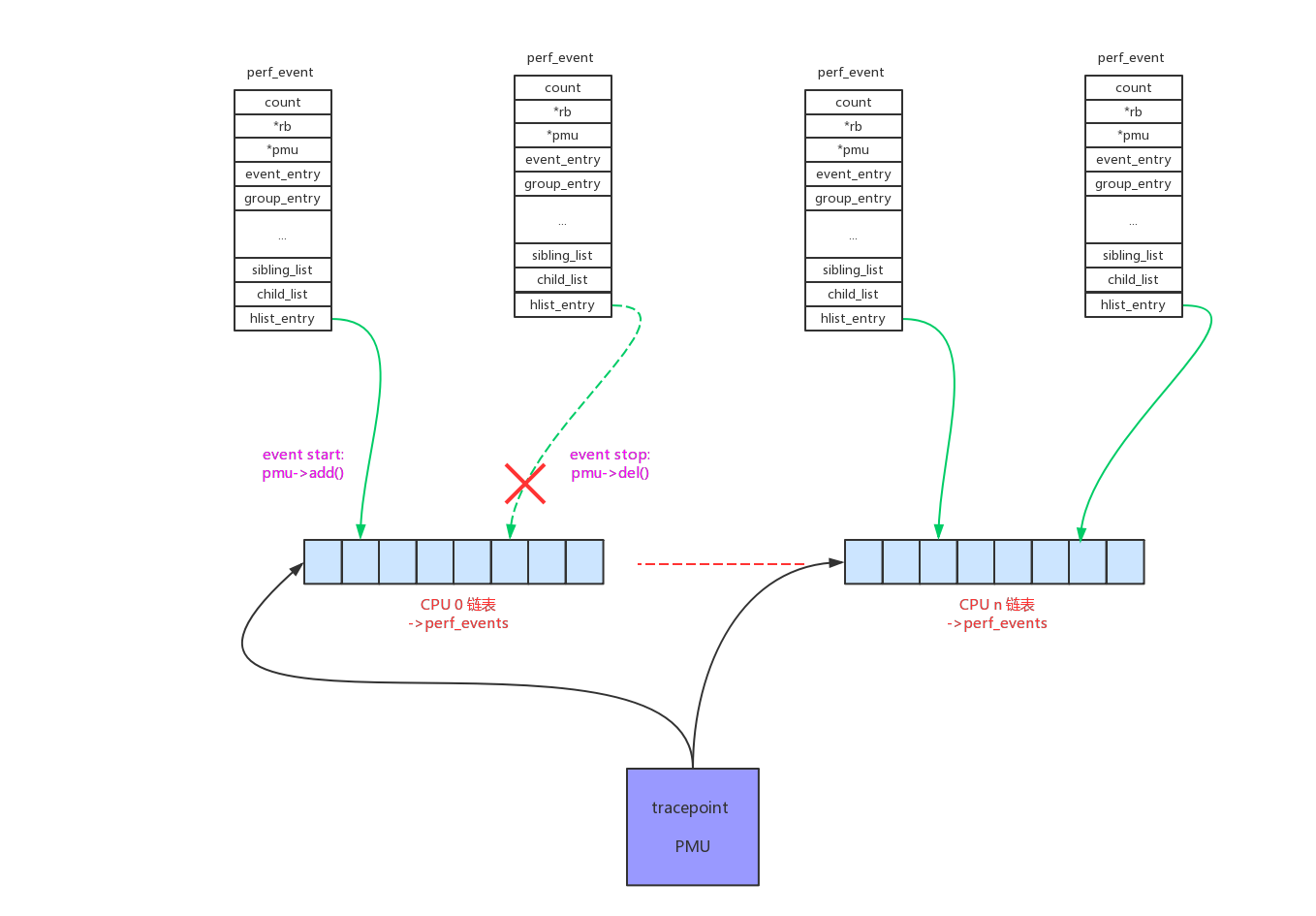
承接上一步perf_event注册以后,perf_event的回调函数已经可以被tracepoint调用,但是perf_event仍然收不到数据。因为这个时候perf_event还处于enable/inactive状态,需要处于active状态才能收到数据。
一个tracepoint会给多个perf_event提供数据,只有将perf_event加入到tp_event->perf_events per_cpu链表中才能收到数据。所以对tracepoint perf_event的start/stop就是操作tp_event->perf_events per_cpu链表。
在上一章“perf_event内核框架”中已经阐明,task维度的perf_event需要和task一起调度,其回调函数最后控制的就是perf_event的启动和停止。
context_switch() -> finish_task_switch() -> perf_event_task_sched_in() -> __perf_event_task_sched_in() -> perf_event_context_sched_in() -> perf_event_sched_in() -> ctx_sched_in() -> ctx_pinned_sched_in()/ctx_flexible_sched_in() -> group_sched_in() -> event_sched_in() -> pmu->add(event, PERF_EF_START) -> perf_trace_add():
1 | int perf_trace_add(struct perf_event *p_event, int flags) |
context_switch() -> prepare_task_switch() -> perf_event_task_sched_out() -> __perf_event_task_sched_out() -> perf_event_context_sched_out() -> ctx_sched_out() -> group_sched_out() -> event_sched_out() -> pmu->del() -> perf_trace_del():
1 | void perf_trace_del(struct perf_event *p_event, int flags) |
4、event 数据采集
perf_event的主要功能就是提供count类型或者sample类型的trace数据。
tracepoint pmu提供trace数据的方式是被动的:tracepoint被命中后,perf callback函数被调用后,累加perf_event的count值,如果perf_event分配了ringbuffer记录sample数据。
4.1、count数据
我们在定义用户trace_event时使用__perf_count()宏指定每次tracepoint命中count的累加值。例如:
1 | DECLARE_EVENT_CLASS(sched_stat_runtime, |
如果没有使用__perf_count()宏定义,默认每次tracepoint命中count加1。
看看具体的代码:
1 | /* (1.1) __perf_addr()宏,指定sample时PERF_SAMPLE_ADDR的值 */ |
perf_trace_buf_prepare()函数的作用是获取一块tmp buffer,为了避免互斥根据当前的context(task, softirq, hardirq, nmi)和当前cpu,从per_cpu变量中分配到一块对应的buffer:
1 | void *perf_trace_buf_prepare(int size, unsigned short type, |
perf_trace_buf_submit()负责提交数据给this_cpu_ptr(event_call->perf_events)链表上等待的perf_event:
1 | static inline void |
4.2、sample数据
我们来继续分析sample类型数据的上报。有两种上报方式:period、freq。
period上报方式:以每period间隔的方式上报。有3个相关的参数:
event->hw.last_period // 当前的period值
event->hw.period_left // 到period一个周期还剩多久,这是一个负值,取值范围(-last_period, 0)
event->hw.sample_period // 最新的period值,只有当上一周期执行完后,才能更新:last_period = sample_period
1 | static void perf_swevent_event(struct perf_event *event, u64 nr, |
perf_event_output()是默认的上报sample数据函数:
1 | void perf_event_output(struct perf_event *event, |
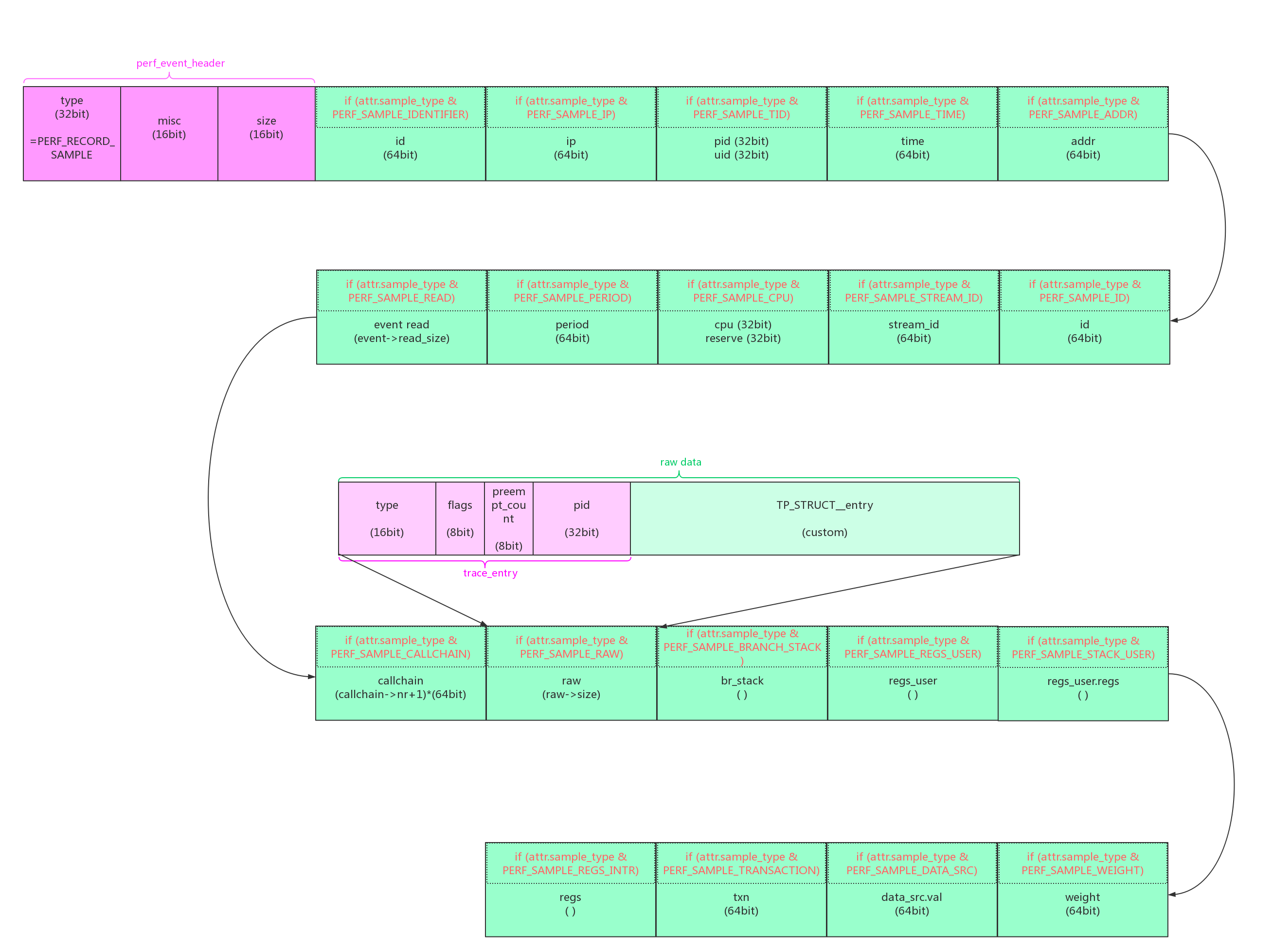
perf_event_type中详细描述了各种type类型的sample数据排列模式:
1 | enum perf_event_type { |