可以通过perf list命令来查看系统中的hardware event:
1 | # simpleperf list hw |
还有hardware-cache event:
1 | # simpleperf list cache |
1、原理介绍:
1.1、hardware pmu
PMU(Performance Monitor Unit)本来指的就是硬件上的性能监控计数器(counter)。因为软件trace方法存在制约制约:1、软件大部分是插桩法,对于没有插桩的地方缺乏监控;2、软件使用hrtimer的采样法开销较大,而且不精确。所以使用硬件采样来trace是一个很好的补充。
可以看到arm64的hardware pmu可以监控:cpu-cycles、instructions、cache-references、cache-misses、branch-misses、cache相关事件等等。它的监控原理比较简单:每个cpu有几个counter,counter 0固定只能配置成cpu-cycles,其他counter可以配置成支持的任意类型。当counter的计数达到我们配置的值后,产生中断,在中断中记录当前的pc等现场信息(sample数据)和累加counter计数(count数据)。
我们可以利用pmu来做以下分析,例如:
- 使用“instructions”每1000 instr采样一次,统计采样pc出现概率最大的函数,这样能找到当前的计算热点;
- 使用“cache-misses”每10 miss采样一次,统计排序,找出“cache-misses”的热点;
arm64v3每个cpu支持7个counter,counter可配置的类型如下:
- hw event。arm64支持的类型:
1 | /* PMUv3 HW events mapping. */ |
arm hw event的全集:
1 | /* |
- hw-cache event。三维数组,arm64支持的类型:
1 | const unsigned armv8_pmuv3_perf_cache_map[PERF_COUNT_HW_CACHE_MAX] |
arm hw-cache event的全集三维数组:
1 | /* |
x86系列pmu支持的监控类型更加丰富。
1.2、pmu init
在dts文件中定义了pmu的类型:
1 | cpu_pmu: cpu-pmu { |
对应的驱动在drivers/perf/perf_event_armv8.c:
1 | static const struct of_device_id armv8_pmu_of_device_ids[] = { |
我们分析它的初始化函数armv8_pmu_device_probe():
1 | static int armv8_pmu_device_probe(struct platform_device *pdev) |
armpmu_init()初始化标准pmu结构:
1 | static void armpmu_init(struct arm_pmu *armpmu) |
cpu_pmu_init()初始化arm_pmu结构的通用部分:
1 | static int cpu_pmu_init(struct arm_pmu *cpu_pmu) |
armv8_pmuv3_init()初始化arm_pmu结构的架构(arm64)相关部分:
1 | static int armv8_pmuv3_init(struct arm_pmu *cpu_pmu) |
2、event init
我们深入来看看标准pmu的event init函数:
1 | static void armpmu_init(struct arm_pmu *armpmu) |
3、event add/del
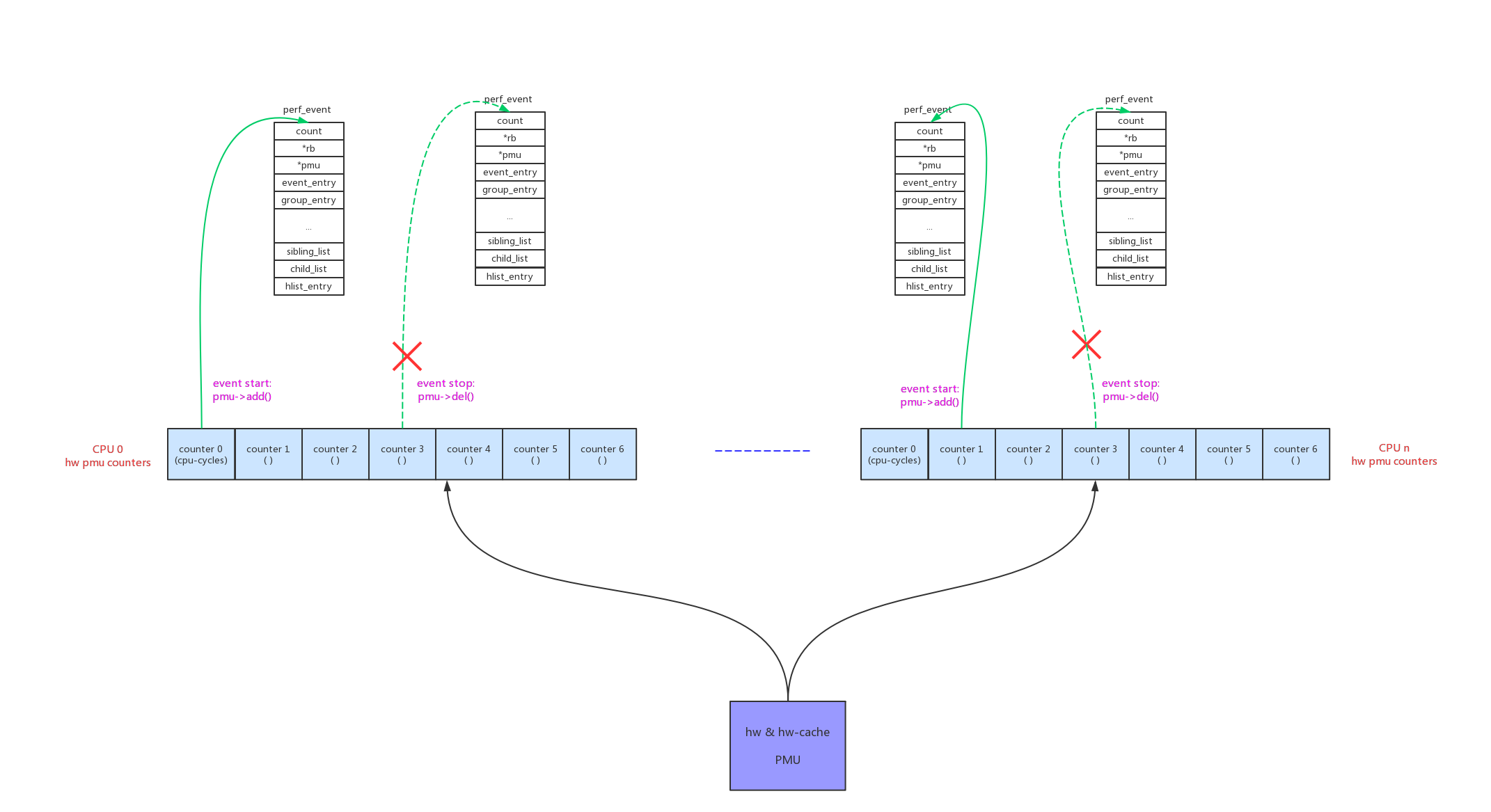
在“perf_event内核框架”一章中已经阐明,task维度的perf_event需要和task一起调度,其回调函数最后控制的就是perf_event的启动和停止。
- start函数调用路径:context_switch() -> finish_task_switch() -> perf_event_task_sched_in() -> __perf_event_task_sched_in() -> perf_event_context_sched_in() -> perf_event_sched_in() -> ctx_sched_in() -> ctx_pinned_sched_in()/ctx_flexible_sched_in() -> group_sched_in() -> event_sched_in() -> pmu->add(event, PERF_EF_START) -> xxx_add():
- stop函数调用路径:context_switch() -> prepare_task_switch() -> perf_event_task_sched_out() -> __perf_event_task_sched_out() -> perf_event_context_sched_out() -> ctx_sched_out() -> group_sched_out() -> event_sched_out() -> pmu->del() -> xxx_del():
可以看到hw counter是非常珍贵的,arm64一个cpu上只有7个counter,而一个perf_event在一个cpu上运行时就需要消耗一个独立的hw counter。不像软件的pmu,多个perf_event可以以链表的形式无限的链接到同一个pmu数据源的per_cpu链表上。
我们具体看看hardware pmu的add和del函数的实现:
- armpmu_add()。从本cpu的counters中分配空闲的counter,配置成perf_event指定的type,并且配置count指定多少count后中断,最后使能counter。
1 | static int |
- armpmu_del()。将event对应的counter停工,并且将counter归还给本cpu的空闲counter。
1 | static void |
4、event 数据采集
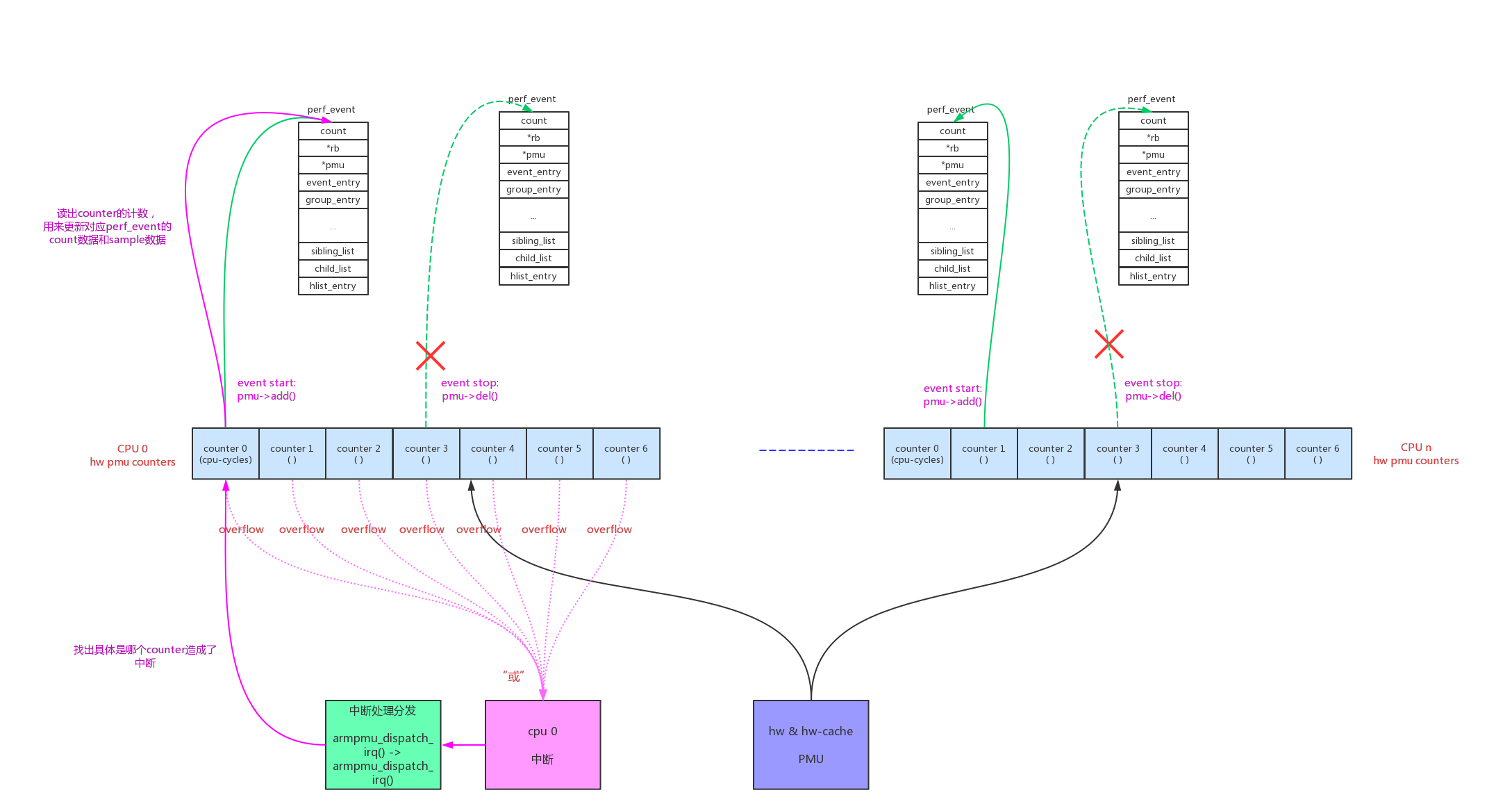
hardware event是采样法,采样法都是依赖于中断实现的:
- 配置counter的count,当count累加到0后,产生中断
- arm64每个cpu上多个counter共享一个中断,所以中断处理函数中需要分发中断,查看到底是哪一个counter发生了overflow
- 如果是某个counter发出的中断,给其对应的perf_event上报count数据和sample数据
- 处理完所以事务后,重新配置counter的count,这样就会重复的产生周期性的采样
具体的中断处理函数如下:
1 | static irqreturn_t armpmu_dispatch_irq(int irq, void *dev) |
4.1、count数据
perf_event的count数据,除了在上一节的中断中更新,在read操作读取时也会更新最新的count。
perf_read() -> perf_read() -> perf_read_one() -> perf_event_read_value() -> perf_event_read() -> perf_event_read():
1 | static void __perf_event_read(void *info) |
4.2、sample数据
在中断中定期的上报sample数据:
1 | static irqreturn_t armv8pmu_handle_irq(int irq_num, void *dev) |