workqueue是内核里面很重要的一个机制,特别是内核驱动,一般的小型任务(work)都不会自己起一个线程来处理,而是扔到workqueu中处理。workqueue的主要工作就是用进程上下文来处理内核中大量的小任务。
所以workqueue的主要设计思想:一个是并行,多个work不要相互阻塞;另外一个是节省资源,多个work尽量共享资源(进程、调度、内存),不要造成系统过多的资源浪费。
为了实现的设计思想,workqueue的设计实现也更新了很多版本。最新的workqueue实现叫做CMWQ(Concurrency Managed Workqueue),也就是用更加智能的算法来实现“并行和节省”。新版本的workque创建函数改成alloc_workqueue(),旧版本的函数create_*workqueue()逐渐会被被废弃。
本文的代码分析基于linux kernel 3.18.22,最好的学习方法还是”read the fucking source code”
1.CMWQ的几个基本概念
关于workqueue中几个概念都是work相关的数据结构非常容易混淆,大概可以这样来理解:
- work :工作。
- workqueue :工作的集合。workqueue和work是一对多的关系。
- worker :工人。在代码中worker对应一个work_thread()内核线程。
- worker_pool:工人的集合。worker_pool和worker是一对多的关系。
- pwq(pool_workqueue):中间人/中介,负责建立起workqueue和worker_pool之间的关系。workqueue和pwq是一对多的关系,pwq和worker_pool是一对一的关系。
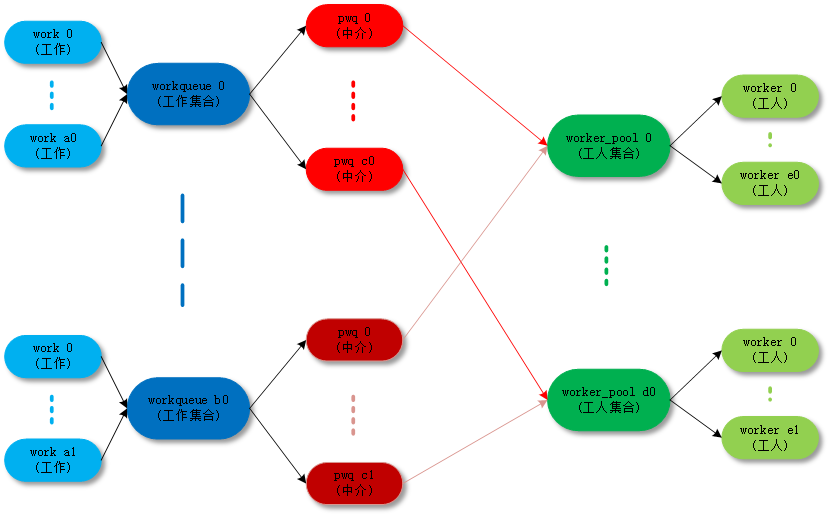
最终的目的还是把work(工作)传递给worker(工人)去执行,中间的数据结构和各种关系目的是把这件事组织的更加清晰高效。
1.1 worker_pool
每个执行work的线程叫做worker,一组worker的集合叫做worker_pool。CMWQ的精髓就在worker_pool里面worker的动态增减管理上manage_workers()。
CMWQ对worker_pool分成两类:
- normal worker_pool,给通用的workqueue使用;
- unbound worker_pool,给WQ_UNBOUND类型的的workqueue使用;
1.1.1 normal worker_pool
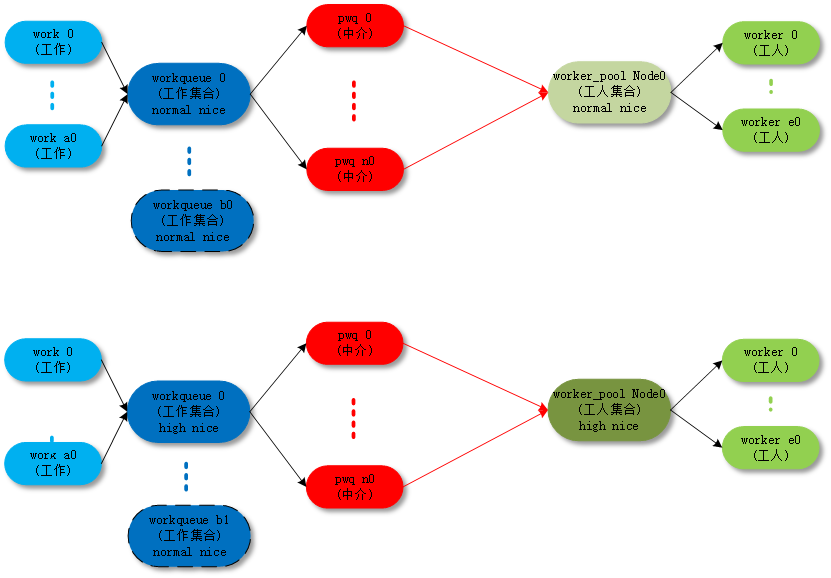
默认work是在normal worker_pool中处理的。系统的规划是每个cpu创建两个normal worker_pool:一个normal优先级(nice=0)、一个高优先级(nice=HIGHPRI_NICE_LEVEL),对应创建出来的worker的进程nice不一样。
每个worker对应一个worker_thread()内核线程,一个worker_pool包含一个或者多个worker,worker_pool中worker的数量是根据worker_pool中work的负载来动态增减的。
我们可以通过“ps|grep kworker”命令来查看所有worker对应的内核线程,normal worker_pool对应内核线程(worker_thread())的命名规则是这样的:
1 | snprintf(id_buf, sizeof(id_buf), "%d:%d%s", pool->cpu, id, |
so类似名字是normal worker_pool:
1 | shell@PRO5:/ $ ps | grep "kworker" |
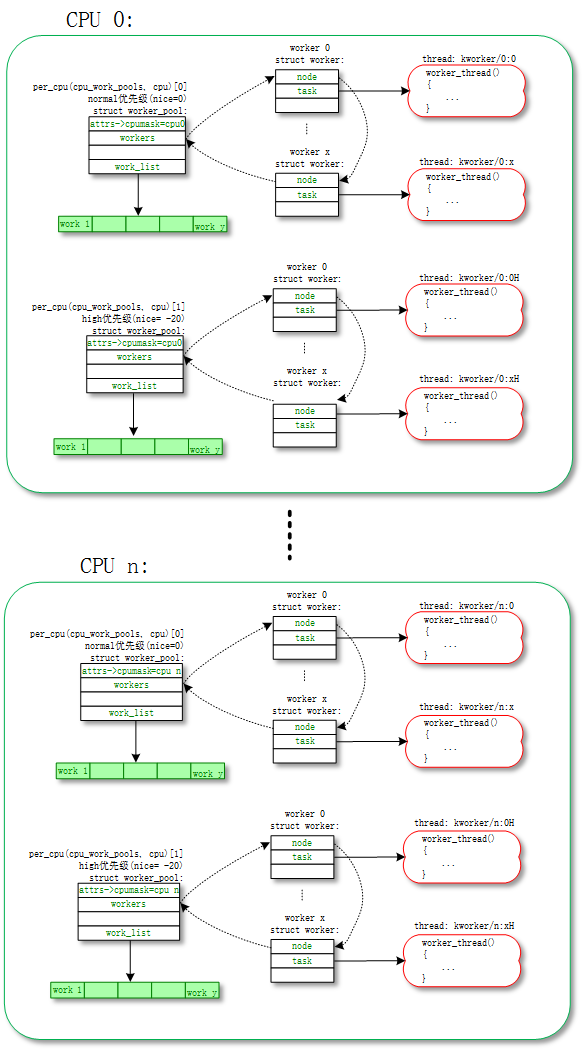
对应的拓扑图如下:
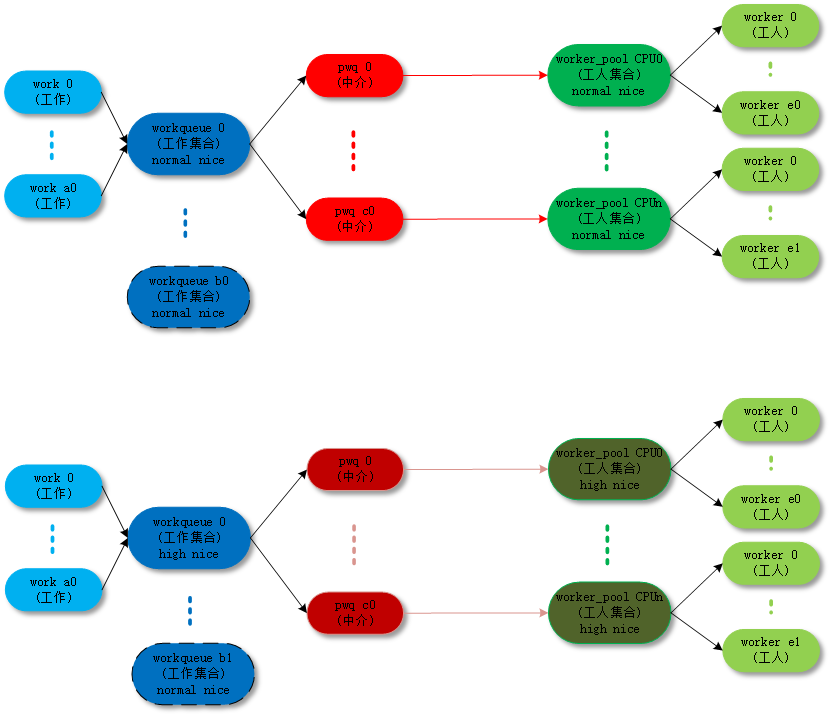
以下是normal worker_pool详细的创建过程代码分析:
- kernel/workqueue.c:
- init_workqueues() -> init_worker_pool()/create_worker()
1 | static int __init init_workqueues(void) |
1.1.2 unbound worker_pool
大部分的work都是通过normal worker_pool来执行的(例如通过schedule_work()、schedule_work_on()压入到系统workqueue(system_wq)中的work),最后都是通过normal worker_pool中的worker来执行的。这些worker是和某个cpu绑定的,work一旦被worker开始执行,都是一直运行到某个cpu上的不会切换cpu。
unbound worker_pool相对应的意思,就是worker可以在多个cpu上调度的。但是他其实也是绑定的,只不过它绑定的单位不是cpu而是node。所谓的node是对NUMA(Non Uniform Memory Access Architecture)系统来说的,NUMA可能存在多个node,每个node可能包含一个或者多个cpu。
unbound worker_pool对应内核线程(worker_thread())的命名规则是这样的:
1 | snprintf(id_buf, sizeof(id_buf), "u%d:%d", pool->id, id); |
so类似名字是unbound worker_pool:
1 | shell@PRO5:/ $ ps | grep "kworker" |
unbound worker_pool也分成两类:
- unbound_std_wq。每个node对应一个worker_pool,多个node就对应多个worker_pool;
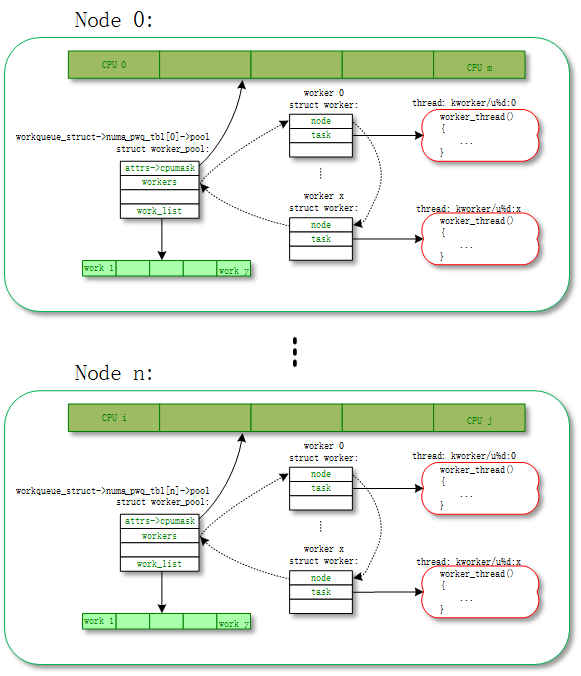
对应的拓扑图如下:
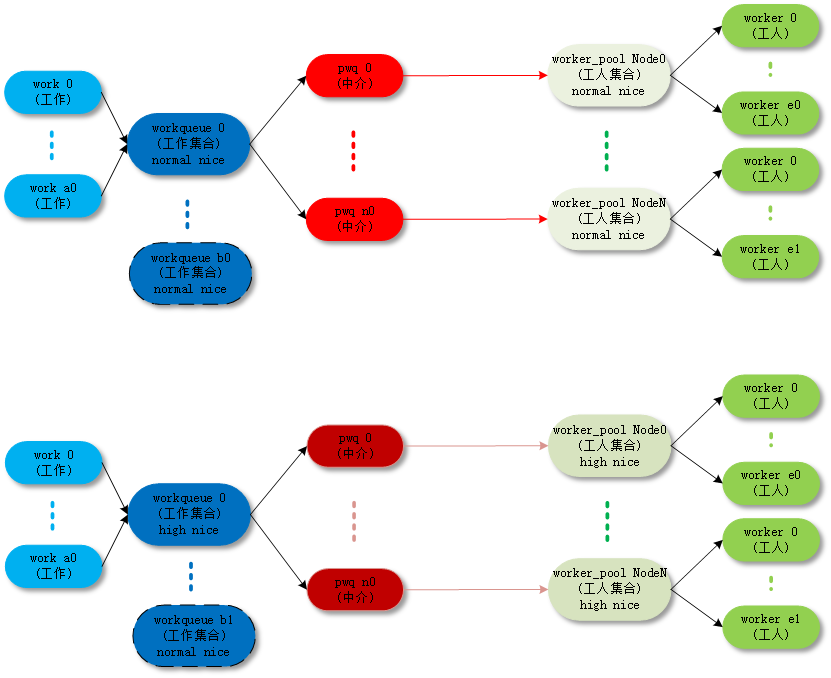
- ordered_wq。所有node对应一个default worker_pool;
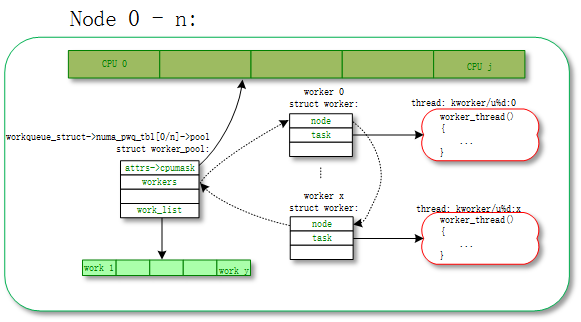
对应的拓扑图如下:
以下是unbound worker_pool详细的创建过程代码分析:
- kernel/workqueue.c:
- init_workqueues() -> unbound_std_wq_attrs/ordered_wq_attrs
1 | static int __init init_workqueues(void) |
- kernel/workqueue.c:
- __alloc_workqueue_key() -> alloc_and_link_pwqs() -> apply_workqueue_attrs() -> alloc_unbound_pwq()/numa_pwq_tbl_install()
1 | struct workqueue_struct *__alloc_workqueue_key(const char *fmt, |
1.2 worker
每个worker对应一个worker_thread()内核线程,一个worker_pool对应一个或者多个worker。多个worker从同一个链表中worker_pool->worklist获取work进行处理。
所以这其中有几个重点:
- worker怎么处理work;
- worker_pool怎么动态管理worker的数量;
1.2.1 worker处理work
处理work的过程主要在worker_thread() -> process_one_work()中处理,我们具体看看代码的实现过程。
- kernel/workqueue.c:
- worker_thread() -> process_one_work()
1 |
|
1.2.2 worker_pool动态管理worker
worker_pool怎么来动态增减worker,这部分的算法是CMWQ的核心。其思想如下:
- worker_pool中的worker有3种状态:idle、running、suspend;
- 如果worker_pool中有work需要处理,保持至少一个runn- kernel/workqueue.c:
- worker_thread() -> process_one_work()
ing worker来处理; - running worker在处理work的过程中进入了阻塞suspend状态,为了保持其他work的执行,需要唤醒新的idle worker来处理work;
- 如果有work需要执行且running worker大于1个,会让多余的running worker进入idle状态;
- 如果没有work需要执行,会让所有worker进入idle状态;
- 如果创建的worker过多,destroy_worker在300s(IDLE_WORKER_TIMEOUT)时间内没有再次运行的idle worker。
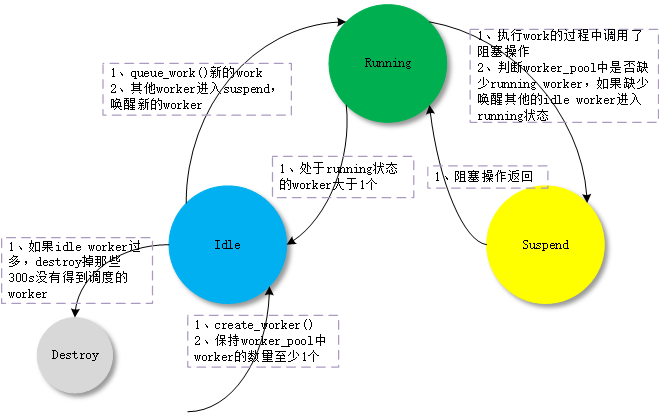
详细代码可以参考上节worker_thread() -> process_one_work()的分析。
为了追踪worker的running和suspend状态,用来动态调整worker的数量。wq使用在进程调度中加钩子函数的技巧:
- 追踪worker从suspend进入running状态:ttwu_activate() -> wq_worker_waking_up()
1 | void wq_worker_waking_up(struct task_struct *task, int cpu) |
- 追踪worker从running进入suspend状态:__schedule() -> wq_worker_sleeping()
1 | struct task_struct *wq_worker_sleeping(struct task_struct *task, int cpu) |
这里worker_pool的调度思想是:如果有work需要处理,保持一个running状态的worker处理,不多也不少。
但是这里有一个问题如果work是cpu密集型的,它虽然也没有进入suspend状态,但是会长时间的占用cpu,让后续的work阻塞太长时间。
为了解决这个问题,CMWQ设计了WQ_CPU_INTENSIVE,如果一个wq声明自己是CPU_INTENSIVE,则让当前worker脱离动态调度,像是进入了suspend状态,那么CMWQ会创建新的worker,后续的work会得到执行。
- kernel/workqueue.c:
- worker_thread() -> process_one_work()
1 |
|
1.2.3 cpu hotplug处理
从上几节可以看到,系统会创建和cpu绑定的normal worker_pool和不绑定cpu的unbound worker_pool,worker_pool又会动态的创建worker。
那么在cpu hotplug的时候,会怎么样动态的处理worker_pool和worker呢?来看具体的代码分析:
- kernel/workqueue.c:
- workqueue_cpu_up_callback()/workqueue_cpu_down_callback()
1 | static int __init init_workqueues(void) |
1.3 workqueue
workqueue就是存放一组work的集合,基本可以分为两类:一类系统创建的workqueue,一类是用户自己创建的workqueue。
不论是系统还是用户workqueue,如果没有指定WQ_UNBOUND,默认都是和normal worker_pool绑定。
1.3.1 系统workqueue
系统在初始化时创建了一批默认的workqueue:system_wq、system_highpri_wq、system_long_wq、system_unbound_wq、system_freezable_wq、system_power_efficient_wq、system_freezable_power_efficient_wq。
像system_wq,就是schedule_work()默认使用的。
- kernel/workqueue.c:
- init_workqueues()
1 | static int __init init_workqueues(void) |
1.3.2 workqueue创建
详细过程见上几节的代码分析:alloc_workqueue() -> __alloc_workqueue_key() -> alloc_and_link_pwqs()。
1.3.3 flush_workqueue()
这一部分的逻辑,wq->work_color、wq->flush_color换来换去的逻辑实在看的头晕。看不懂暂时不想看,放着以后看吧,或者有谁看懂了教我一下。:)
1.4 pool_workqueue
pool_workqueue只是一个中介角色。
详细过程见上几节的代码分析:alloc_workqueue() -> __alloc_workqueue_key() -> alloc_and_link_pwqs()。
1.5 work
描述一份待执行的工作。
1.5.1 queue_work()
将work压入到workqueue当中。
- kernel/workqueue.c:
- queue_work() -> queue_work_on() -> __queue_work()
1 | static void __queue_work(int cpu, struct workqueue_struct *wq, |
1.5.2 flush_work()
flush某个work,确保work执行完成。
怎么判断异步的work已经执行完成?这里面使用了一个技巧:在目标work的后面插入一个新的work wq_barrier,如果wq_barrier执行完成,那么目标work肯定已经执行完成。
- kernel/workqueue.c:
- queue_work() -> queue_work_on() -> __queue_work()
1 | /** |
2.Workqueue对外接口函数
CMWQ实现的workqueue机制,被包装成相应的对外接口函数。
2.1 schedule_work()
把work压入系统默认wq system_wq,WORK_CPU_UNBOUND指定worker为当前cpu绑定的normal worker_pool创建的worker。
- kernel/workqueue.c:
- schedule_work() -> queue_work_on() -> __queue_work()
1 | static inline bool schedule_work(struct work_struct *work) |
2.2 sschedule_work_on()
在schedule_work()基础上,可以指定work运行的cpu。
- kernel/workqueue.c:
- schedule_work_on() -> queue_work_on() -> __queue_work()
1 | static inline bool schedule_work_on(int cpu, struct work_struct *work) |
2.3 schedule_delayed_work()
启动一个timer,在timer定时到了以后调用delayed_work_timer_fn()把work压入系统默认wq system_wq。
- kernel/workqueue.c:
- schedule_work_on() -> queue_work_on() -> __queue_work()
1 | static inline bool schedule_delayed_work(struct delayed_work *dwork, |