在调试内核的时候,经常会碰到几个相近的概念:进程stop、进程park、进程freeze。这几个名词看起来都是停止进程,那么他们之间的区别和应用场景在分别是什么呢?下面就来分析一番。
本文的代码分析基于linux kernel 3.18.22,最好的学习方法还是”RTFSC”
1.进程stop
进程stop分成两种:用户进程stop和内核进程stop。
用户进程stop可以通过给进程发送STOP信号来实现,可以参考“Linux Signal”这一篇的描述。但是对内核进程来说不会响应信号,如果碰到需要stop内核进程的场景怎么处理?比如:我们在设备打开的时候创建了内核处理进程,在设备关闭的时候需要stop内核进程。
linux实现了一套kthread_stop()的机制来实现内核进程stop。
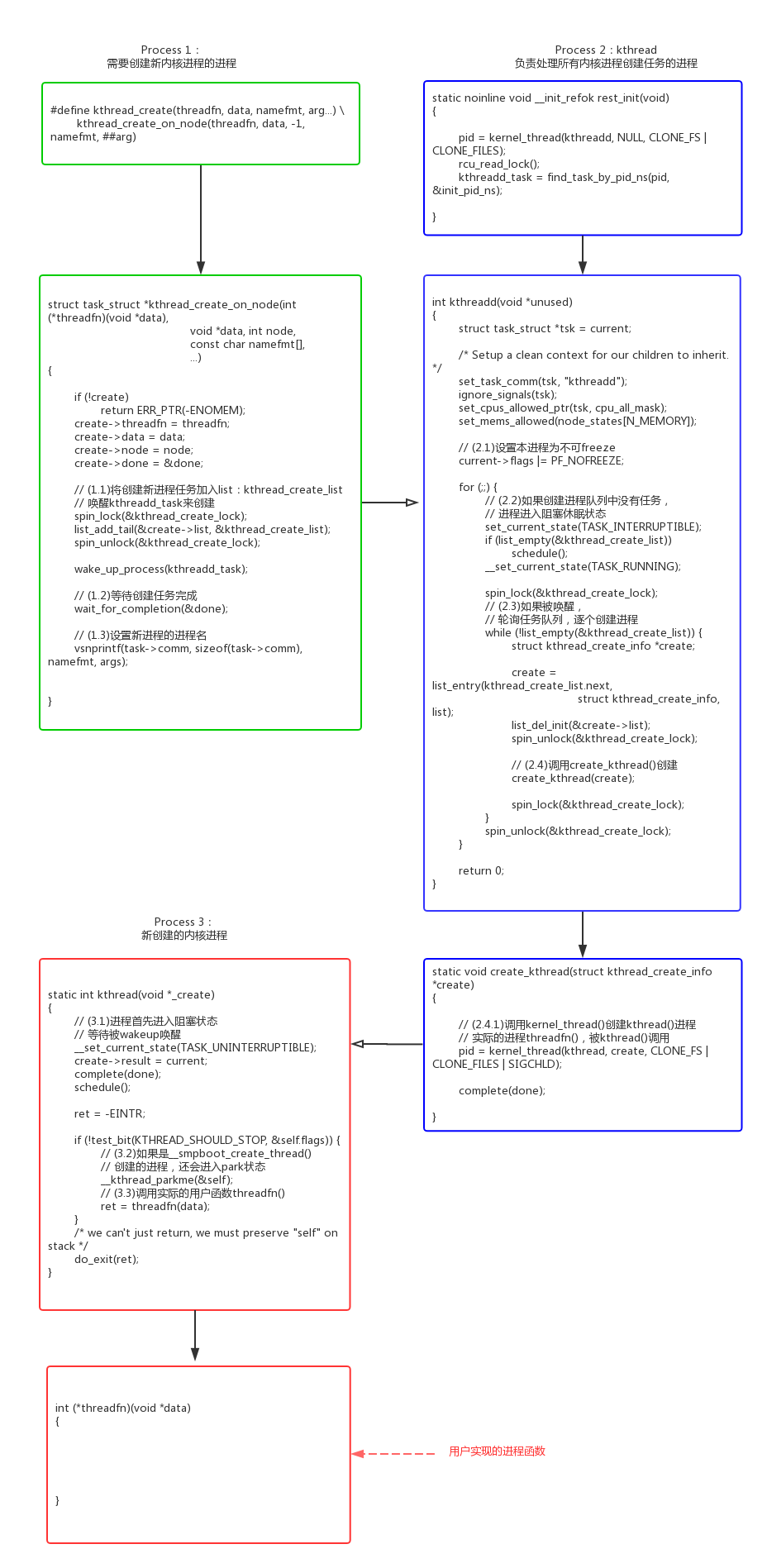
1.1内核进程的创建
内核进程创建过程,是理解本篇的基础。
可以看到kthread_create()并不是自己去创建内核进程,而是把创建任务推送给kthreadd()进程执行。
kthreadd() -> create_kthread() -> kernel_thread()创建的新进程也不是直接使用用户的函数threadfn(),而是创建通用函数kthread(),kthread()再来调用threadfn()。
- kernel/kthread.c:
1.2内核进程的stop
如果内核进程需要支持kthread_stop(),需要根据以下框架来写代码。用户在主循环中调用kthread_should_stop()来判断当前kthread是否需要stop,如果被stop则退出循环退出进程。
这种代码为什么不做到通用代码kthread()中?这应该是和linux的设计思想相关的。linux运行内核态的策略比较灵活,而对用户态的策略更加严格统一。

kthread_should_stop()和kthread_stop()的代码实现:
- kernel/kthread.c:
- kthread_should_stop()/kthread_stop()
1 |
|
2.进程park
smpboot_register_percpu_thread()用来创建per_cpu内核进程,所谓的per_cpu进程是指需要在每个online cpu上创建的线程。比如执行stop_machine()多cpu同步操作的migration进程:
1 | shell@:/ $ ps | grep migration |
问题来了,既然per_cpu进程是和cpu绑定的,那么在cpu hotplug的时候,进程需要相应的disable和enable。实现的方法可以有多种:
- 动态的销毁和创建线程。缺点是开销比较大。
- 设置进程的cpu亲和力set_cpus_allowed_ptr()。缺点是进程绑定的cpu如果被down掉,进程会迁移到其他cpu继续执行。
为了克服上述方案的缺点,适配per_cpu进程的cpu hotplug操作,设计了kthread_park()/kthread_unpark()机制。
2.1 smpboot_register_percpu_thread()
per_cpu进程从代码上看,实际也是调用kthread_create()来创建的。
- kernel/smpboot.c:
- kernel/kthread.c:
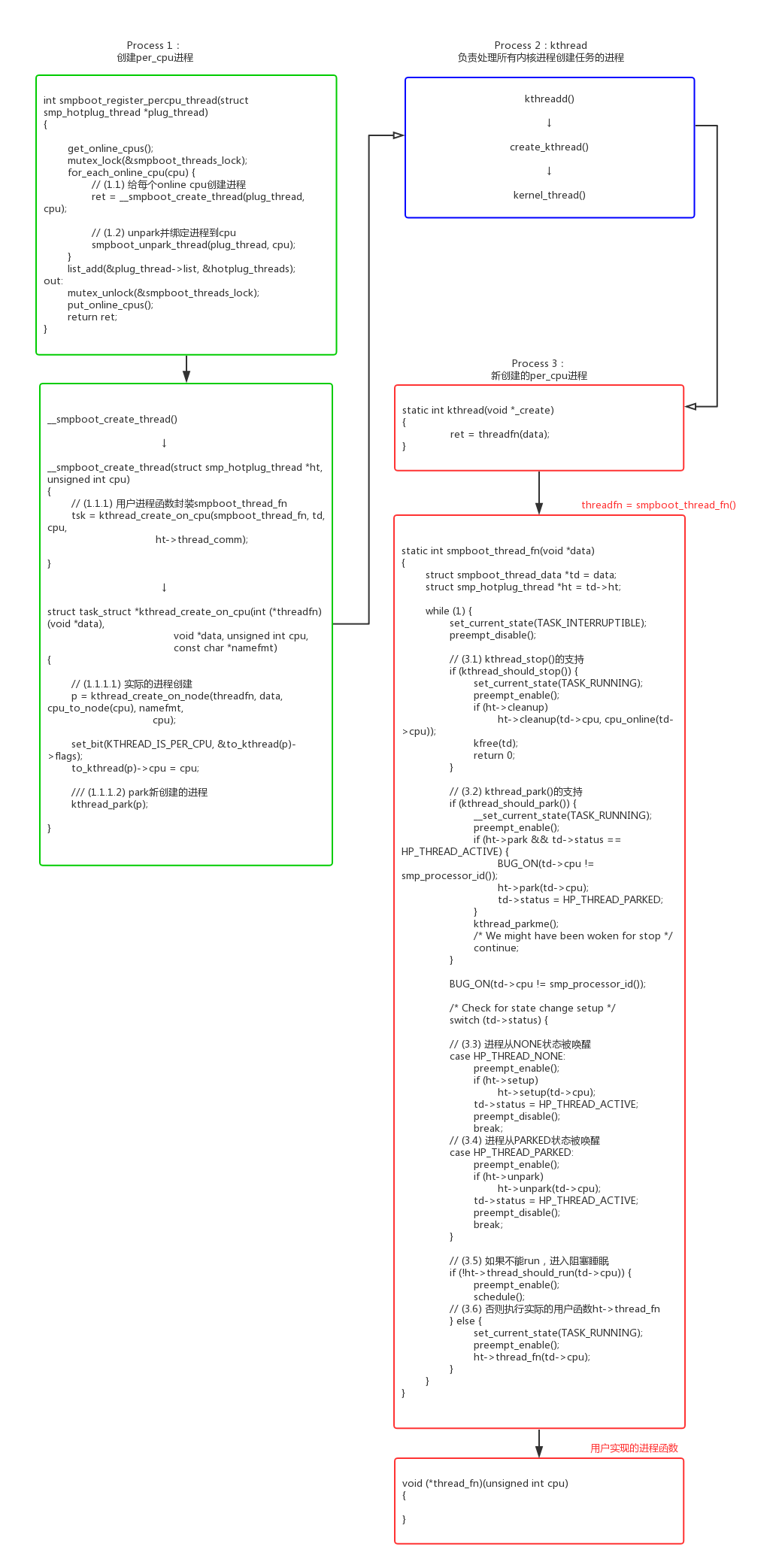
我们可以看到smpboot_register又增加了一层封装:kthread() -> smpboot_thread_fn() -> ht->thread_fn(),这种封装的使用可以参考cpu_stop_threads。
- kernel/stop_machine.c:
1 | static struct smp_hotplug_thread cpu_stop_threads = { |
我们可以看到smpboot_thread_fn()循环中实现了对park的支持,具体实现kthread_should_park()、kthread_parkme()、kthread_park()、kthread_unpark()的代码分析:
- kernel/kthread.c:
1 | bool kthread_should_park(void) |
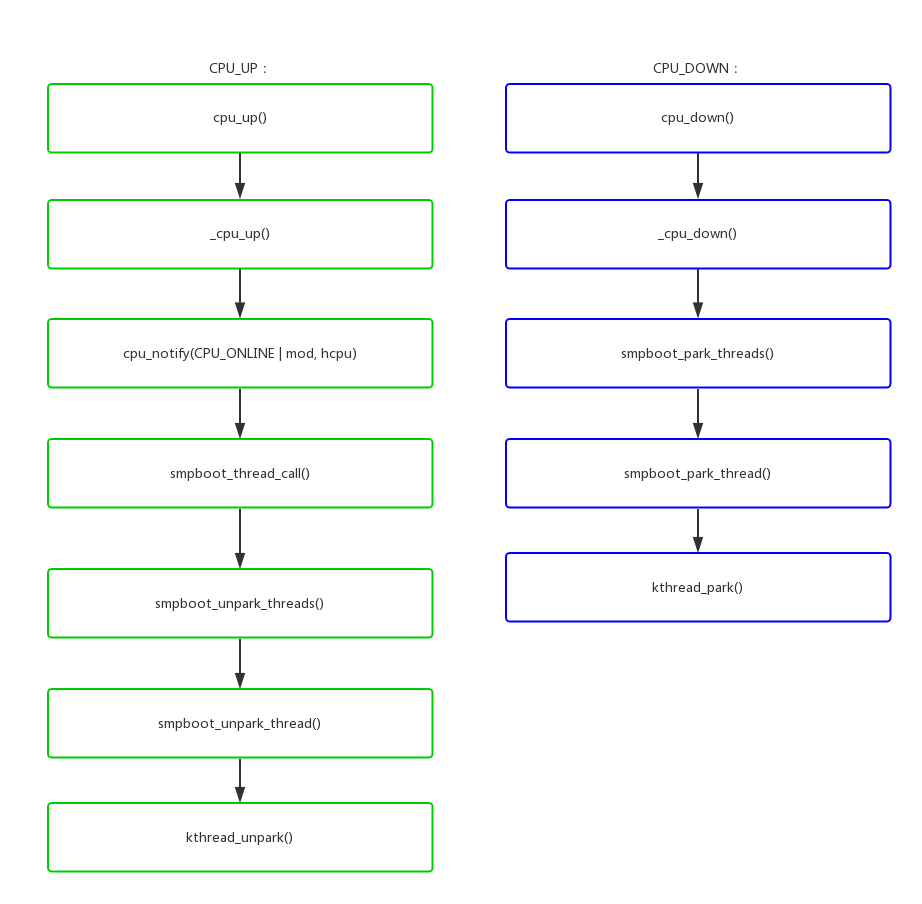
2.2 cpu hotplug支持
我们前面说到park机制的主要目的是为了per_cpu进程支持cpu hotplug,具体怎么响应热插拔事件呢?
- kernel/smpboot.c:
3.进程freeze
在系统进入suspend的时候,会尝试冻住一些进程,以避免一些进程无关操作影响系统的suspend状态。主要的流程如下:
- kernel/power/suspend.c:
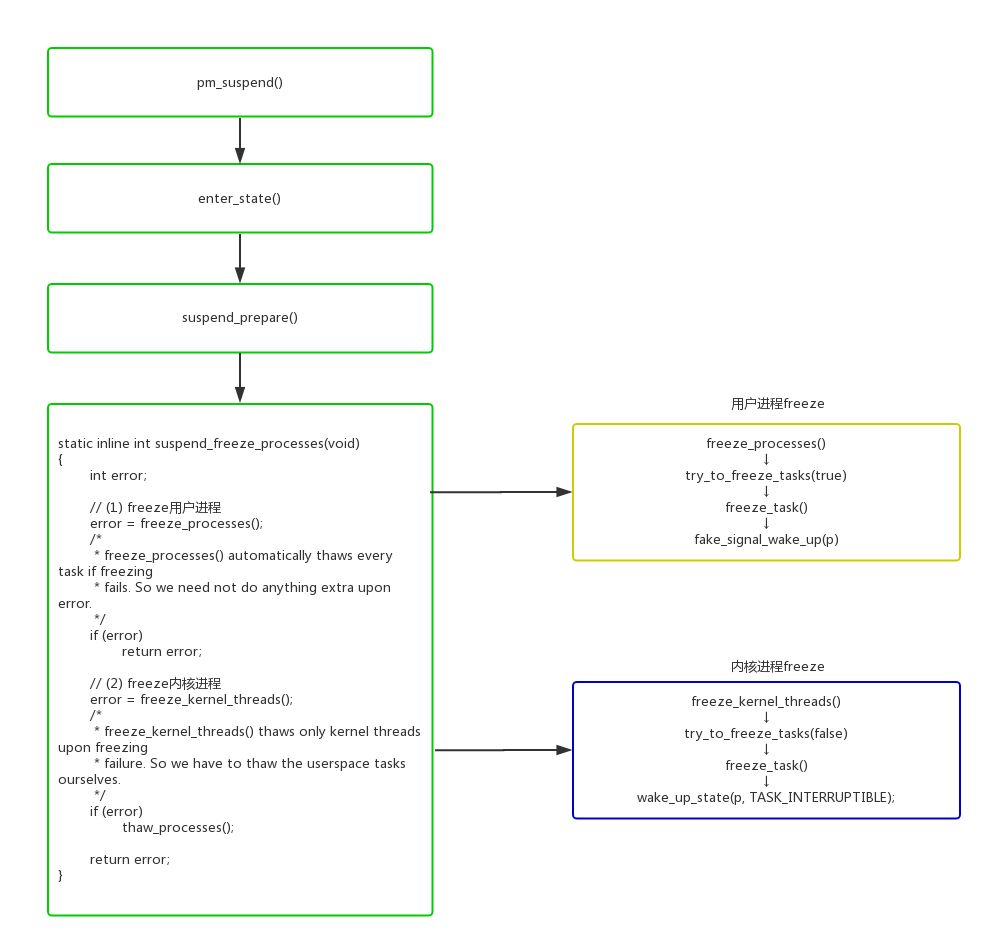
这suspend_freeze里面判断当前在那个阶段,有3个重要的变量:
1 | - system_freezing_cnt。>0表示系统全局的freeze开始; |
具体代码分析如下:
- kernel/power/process.c:
- kernel/freezer.c:
- suspend_freeze_processes() -> freeze_processes() -> try_to_freeze_tasks() -> freeze_task()
1 |
|
3.1 用户进程freeze
freeze用户态的进程利用了signal机制,系统suspend使能了suspend以后,调用fake_signal_wake_up()伪造一个信号唤醒进程,进程在ret_to_user() -> do_notify_resume() -> do_signal() -> get_signal() -> try_to_freeze()中freeze自己。
具体代码分析如下:
- kernel/freezer.c:
1 | static inline bool try_to_freeze(void) |
3.2 内核进程freeze
内核进程对freeze的响应,有两个问题:
- wake_up_state(p, TASK_INTERRUPTIBLE)能唤醒哪些内核进程。
- 内核进程怎么样来响应freeze状态,怎么样来freeze自己。
如果进程阻塞在信号量、mutex等内核同步机制上,wake_up_state并不能解除阻塞。因为这些机制都有while(1)循环来判断条件,是否成立,不成立只是简单的唤醒随即又会进入阻塞睡眠状态。
- kernel/locking/mutex.c:
- mutex_lock() -> __mutex_lock_common()
1 | __mutex_lock_common(struct mutex *lock, long state, unsigned int subclass, |
所以wake_up_state()只能唤醒这种简单阻塞的内核进程,而对于阻塞在内核同步机制上是无能无力的:
1 | void user_thread() |
内核进程响应freeze操作,也必须显式的调用try_to_freeze()或者kthread_freezable_should_stop()来freeze自己:
1 | void user_thread() |
所以从代码逻辑上看内核进程freeze,并不会freeze所有内核进程,只freeze了2部分:一部分是设置了WQ_FREEZABLE标志的workqueue,另一部分是内核进程主动调用try_to_freeze()并且在架构上设计的可以响应freeze。