1、Linux schedule框架(调度的时刻)
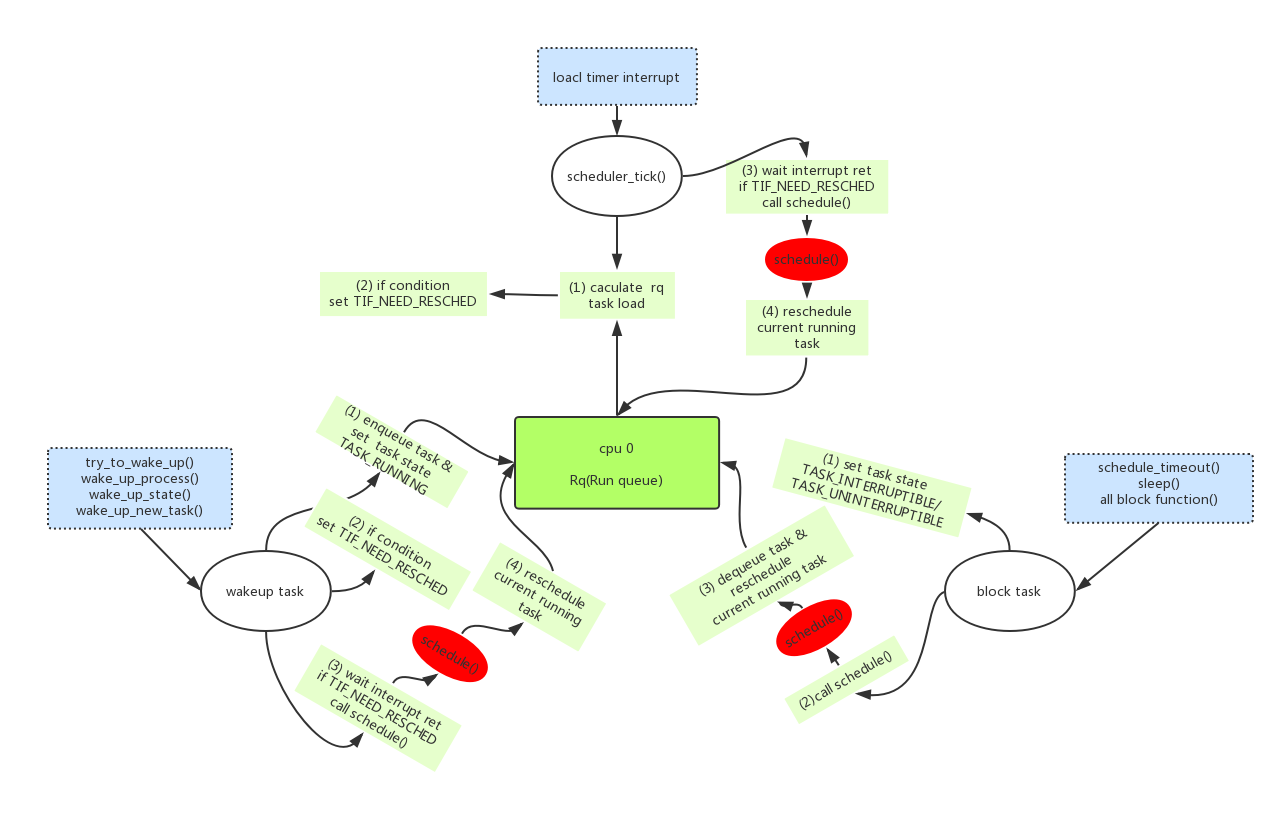
Linux进程调度(schedule)的框架如上图所示。
本文的代码分析基于linux kernel 4.4.22,最好的学习方法还是”RTFSC”
1.1、中心是rq(runqueue)
rq其实是runnable queue,即本cpu上所有可运行进程的队列集合。每个cpu每种类型的rq(cfs/rt)只有一个,一个rq包含多个runnable的task,但是rq当前正在运行的进程(current running task)只有一个。
既然rq是中心,那么以下几点就是关键路径:
- 1、什么时候task入rq?
- 2、什么时候task出rq?
- 3、rq怎么样从多个可运行的进程(runnable tasks)中选取一个进程作为当前的运行进程(current running task)?
我们下面就逐一解答这些疑问,理解了这些关键路径,你就对linux的进程调度框架有了一个清晰的认识。
1.2、入rq(enqueue)
只有task新创建/或者task从blocked状态被唤醒(wakeup),task才会被压入rq。涉及到进程调度相关的步骤如下:
1、把task压入rq(enqueue),且把task->state设置为TASK_RUNNING;
2、判断压入新task以后rq的负载情况,当前task需不需要被调度出去,如果需要把当前task的thread_info->flags其中TIF_NEED_RESCHED bit置位。
重点在这里:如果当前进程需要重新调度的条件成立,这里只是会设置TIF_NEED_RESCHED标志,并不会马上调用schedule()来进行调度。真正的调度时机发生在从中断/异常返回时,会判断当前进程有没有被设置TIF_NEED_RESCHED,如果设置则调用schedule()来进行调度。
为什么唤醒涉及到调度不会马上执行?而是只设置一个TIF_NEED_RESCHED,等到中断/异常返回的时候才执行?
我理解有几点:(1)唤醒操作经常在中断上下文中执行,在这个环境中直接调用schedule()进行调度是不行的;(2)为了维护非抢占内核以来的一些传统,不要轻易中断进程的处理逻辑除非他主动放弃;(3)在普通上下文中,唤醒后接着调用schedule()也是可以的,我们看到一些特殊函数就是这么干的(调用smp_send_reschedule()、resched_curr()的函数)。
- 3、等待中断/异常的发生、返回,在返回时判读有TIF_NEED_RESCHED,则调用schedule()进行调度;
1.3、出rq(dequeue)
在当前进程调用系统函数进入blocked状态是,task会出rq(dequeue)。具体的步骤如下:
1、当前进程把task->state设置为TASK_INTERRUPTIBLE/TASK_UNINTERRUPTIBLE;
2、立即调用schedule()进行调度;
这里block是和wakeup、scheduler_tick最大的不同,block是马上调用schedule()进行调度,而wakeup、scheduler_tick是设置TIF_NEED_RESCHED标志,等待中断/异常返回时才执行真正的schedule()操作;
- 3、调用schedule()后,判断当前进程task->state已经非TASK_RUNNING,则进行dequeue操作,并且调度其他进程到rq->curr。
1.4、定时调度rq(scheduler_tick)
前面说了在rq的enqueue、dequeue时刻会计算rq负载,来决定把哪个runnable task放到current running task。除了enqueue/dequeue时候,系统还会周期性的计算rq负载来进行调度,确保多进程在1个cpu上都能得到服务。具体的步骤如下:
- 1、每1 tick,local timer产生一次中断。中断中调用scheduler_tick(),计算rq的负载重新调度;
- 2、如果当前进程需要被调度,则设置TIF_NEED_RESCHED标志;
- 3、在local timer中断返回的时候,时判读有TIF_NEED_RESCHED,则调用schedule()进行调度;
1.5、中断/异常返回(Interrupt/Exception)
在前面几节中有一个重要的概念,wakeup、scheduler_tick操作后,如果需要调度只会设置TIF_NEED_RESCHED,在中断/异常返回时才执行真正的调度schedule()操作;
那么在哪些中断/异常返回时会执行schedule()呢?
我们分析”arch/arm64/kernel/entry.S”,在ArmV8架构下用户态跑在el0、内核态跑在el1。
- 1、内核态异常的返回el1_sync():
1 | .align 6 |
大部分的内核态异常都是不可恢复的,内核最终会调用panic()复位,所以根本不会再返回去判断TIF_NEED_RESCHED标志;另外一部分可以返回的也只是简单调用kernel_exit恢复,不会去判断TIF_NEED_RESCHED标志。
- 2、内核态中断的返回el1_sync():
1 | .align 6 |
可以看到在内核态中断返回时:会首先判断当前进程的thread_info->preempt_count的值,如果大于0说明禁止抢占不做处理直接返回;如果等于0且thread_info->flags被置位TIF_NEED_RESCHED,调用preempt_schedule_irq()重新进行调度。
- 3、用户态系统调用类异常的返回el0_svc():
1 | .align 6 |
用户态的异常其中一个大类就是系统调用,这是用户主动调用svc命令陷入到内核态中执行系统调用。
在返回用户态的时候会判断thread_info->flags中的TIF_NEED_RESCHED bit有没有被置位,有置位则会调用schedule();还会判断_TIF_SIGPENDING,有置位会进行信号处理do_signal()。
- 4、用户态其他异常的返回el0_sync():
1 | .align 6 |
用户态的异常除了系统调用,剩下就是错误类型的异常,比如:data abort、instruction abort、其他错误等。
在返回用户态的时候会判断thread_info->flags中的TIF_NEED_RESCHED bit有没有被置位,有置位则会调用schedule();还会判断_TIF_SIGPENDING,有置位会进行信号处理do_signal()。
- 5、用户态中断的返回el0_irq();
1 | .align 6 |
用户态的中断处理和其他异常处理一样,最后都是调用ret_to_user返回用户态。
在返回用户态的时候会判断thread_info->flags中的TIF_NEED_RESCHED bit有没有被置位,有置位则会调用schedule();还会判断_TIF_SIGPENDING,有置位会进行信号处理do_signal()。
1.6、什么叫抢占(preempt)?
从上一节的分析中断/异常返回一共有5类路径:
- 内核态异常的返回el1_sync(),不支持调度检测;
- 内核态中断的返回el1_sync(),支持对preempt_count和TIF_NEED_RESCHED的检测;
- 用户态系统调用类异常的返回el0_svc(),支持对TIF_NEED_RESCHED和_TIF_SIGPENDING的检测;
- 用户态其他异常的返回el0_sync(),支持对TIF_NEED_RESCHED和_TIF_SIGPENDING的检测;
- 用户态中断的返回el0_irq(),支持对TIF_NEED_RESCHED和_TIF_SIGPENDING的检测;
我们可以看到是否支持抢占,只会影响”内核态中断的返回”这一条路径。
- “抢占(preempt)”,如果抢占使能在内核态中断的返回时会检测是否需要进行进程调度schedule(),如果抢占不使能则在该路径下会直接返回原进程什么也不会做。
1.6.1、PREEMPT_ACTIVE标志
在之前的内核中会存在PREEMPT_ACTIVE这样一个标志,他是为了避免在如下代码被抢占会出现问题:
1 | for (; ;) { |
假设如下场景:
- 1、进程首先执行步骤1 prepare_to_wait()把自己设置为TASK_UNINTERRUPTIBLE,但是在执行步骤2时发现条件(condition)成立准备退出循环,调用finish_wait()恢复TASK_RUNNING状态,这时发生了抢占。
- 2、发生抢占以后调用schedule()的过程中会判断当前需要调度的进程是否为TASK_UNINTERRUPTIBLE/TASK_INTERRUPTIBLE睡眠状态,如果是的话schedule()认为进程是从主动blocked路径中进来的,会把当前进程退出runqueue(deactivate_task)。
- 3、正常的用户逻辑主动调用blocked操作进入睡眠状态是没有关系的,因为用户会设计其他的唤醒操作;但是上述场景违反了用户的正常逻辑,在条件(condition)成立的情况下把进程dequeue出运行队列,可能会造成进程无人唤醒永远不会被执行。
为了避免以上的错误发生,在以前版本的内核中设计了PREEMPT_ACTIVE标志,如果是抢占发生首先设置PREEMPT_ACTIVE标志再调用schedule(),schedule()判断PREEMPT_ACTIVE的存在则不会进行dequeue/deactive操作。
1 | asmlinkage void __sched preempt_schedule_irq(void) |
最新的4.4内核中,已经取消PREEMPT_ACTIVE标志而改为使用__schedule(bool preempt)的函数参数传入:
1 | asmlinkage __visible void __sched preempt_schedule_irq(void) |
1.7、代码分析
上述几节的内容讲述了调度相关的几个关键节点,所以理解调度你可以从以下的几个函数入手:
- try_to_wake_up() // wakeup task
- block task // 类如:mutex_lock()、down()、schedule_timeout()、msleep()
- scheduler_tick()
- schedule()
2、调度算法
linux进程一般分成了实时进程(RT)和普通进程,linux使用sched_class结构来管理不同类型进程的调度算法:rt_sched_class负责实时类进程(SCHED_FIFO/SCHED_RR)的调度,fair_sched_class负责普通进程(SCHED_NORMAL)的调度,还有idle_sched_class(SCHED_IDLE)、dl_sched_class(SCHED_DEADLINE)都比较简单和少见;
实时进程的调度算法移植都没什么变化,SCHED_FIFO类型的谁优先级高就一直抢占/SCHED_RR相同优先级的进行时间片轮转。
所以我们常说的调度算法一般指普通进程(SCHED_NORMAL)的调度算法,这类进程也在系统中占大多数。在2.6.24以后内核引入的是CFS算法,这个也是现在的主流;在这之前2.6内核使用的是一种O(1)算法;
2.1、linux2.6的O(1)调度算法
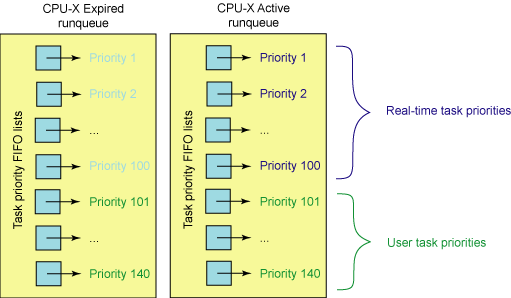
linux进程的优先级有140种,其中优先级(0-99)对应实时进程,优先级(100-139)对应普通进程,nice(0)对应优先级120,nice(-10)对应优先级100,nice(19)对应优先级139。
1 | #define MAX_USER_RT_PRIO 100 |
O(1)调度算法主要包含以下内容:
- (1)、每个cpu的rq包含两个140个成员的链表数组rq->active、rq->expired;
任务根据优先级挂载到不同的数组当中,时间片没有用完放在rq->active,时间片用完后放到rq->expired,在rq->active所有任务时间片用完为空后rq->active和rq->expired相互反转。
在schedule()中pcik next task时,首先会根据array->bitmap找出哪个最先优先级还有任务需要调度,然后根据index找到 对应的优先级任务链表。因为查找bitmap的在IA处理器上可以通过bsfl等一条指令来实现,所以他的复杂度为O(1)。
1 | asmlinkage void __sched schedule(void) |
- (2)、进程优先级分为静态优先级(p->static_prio)、动态优先级(p->prio);
静态优先级(p->static_prio)决定进程时间片的大小:
1 | /* |
动态优先级决定进程在rq->active、rq->expired进程链表中的index:
1 | static void enqueue_task(struct task_struct *p, prio_array_t *array) |
动态优先级和静态优先级之间的转换函数:动态优先级=max(100 , min(静态优先级 – bonus + 5) , 139)
1 | /* |
从上面看出动态优先级是以静态优先级为基础,再加上相应的惩罚或奖励(bonus)。这个bonus并不是随机的产生,而是根据进程过去的平均睡眠时间做相应的惩罚或奖励。所谓平均睡眠时间(sleep_avg,位于task_struct结构中)就是进程在睡眠状态所消耗的总时间数,这里的平均并不是直接对时间求平均数。
- (3)、根据平均睡眠时间判断进程是否是交互式进程(INTERACTIVE);
交互式进程的好处?交互式进程时间片用完会重新进入active队列;
1 | void scheduler_tick(void) |
判断进程是否是交互式进程(INTERACTIVE)的公式:动态优先级≤3*静态优先级/4 + 28
1 | #define TASK_INTERACTIVE(p) \ |
平均睡眠时间的算法和交互进程的思想,我没有详细去看大家可以参考一下的一些描述:
所谓平均睡眠时间(sleep_avg,位于task_struct结构中)就是进程在睡眠状态所消耗的总时间数,这里的平均并不是直接对时间求平均数。平均睡眠时间随着进程的睡眠而增长,随着进程的运行而减少。因此,平均睡眠时间记录了进程睡眠和执行的时间,它是用来判断进程交互性强弱的关键数据。如果一个进程的平均睡眠时间很大,那么它很可能是一个交互性很强的进程。反之,如果一个进程的平均睡眠时间很小,那么它很可能一直在执行。另外,平均睡眠时间也记录着进程当前的交互状态,有很快的反应速度。比如一个进程在某一小段时间交互性很强,那么sleep_avg就有可能暴涨(当然它不能超过 MAX_SLEEP_AVG),但如果之后都一直处于执行状态,那么sleep_avg就又可能一直递减。理解了平均睡眠时间,那么bonus的含义也就显而易见了。交互性强的进程会得到调度程序的奖励(bonus为正),而那些一直霸占CPU的进程会得到相应的惩罚(bonus为负)。其实bonus相当于平均睡眠时间的缩影,此时只是将sleep_avg调整成bonus数值范围内的大小。
O(1)调度器区分交互式进程和批处理进程的算法与以前虽大有改进,但仍然在很多情况下会失效。有一些著名的程序总能让该调度器性能下降,导致交互式进程反应缓慢。例如fiftyp.c, thud.c, chew.c, ring-test.c, massive_intr.c等。而且O(1)调度器对NUMA支持也不完善。
2.2、CFS调度算法
针对O(1)算法出现的问题(具体是哪些问题我也理解不深说不上来),linux推出了CFS(Completely Fair Scheduler)完全公平调度算法。该算法从楼梯调度算法(staircase scheduler)和RSDL(Rotating Staircase Deadline Scheduler)发展而来,抛弃了复杂的active/expire数组和交互进程计算,把所有进程一视同仁都放到一个执行时间的红黑树中,实现了完全公平的思想。
CFS的主要思想如下:
- 根据普通进程的优先级nice值来定一个比重(weight),该比重用来计算进程的实际运行时间到虚拟运行时间(vruntime)的换算;不言而喻优先级高的进程运行更多的时间和优先级低的进程运行更少的时间在vruntime上市等价的;
- 根据rq->cfs_rq中进程的数量计算一个总的period周期,每个进程再根据自己的weight占整个的比重来计算自己的理想运行时间(ideal_runtime),在scheduler_tick()中判断如果进程的实际运行时间(exec_runtime)已经达到理想运行时间(ideal_runtime),则进程需要被调度test_tsk_need_resched(curr)。有了period,那么cfs_rq中所有进程在period以内必会得到调度;
- 根据进程的虚拟运行时间(vruntime),把rq->cfs_rq中的进程组织成一个红黑树(平衡二叉树),那么在pick_next_entity时树的最左节点就是运行时间最少的进程,是最好的需要调度的候选人;
2.2.1、vruntime
每个进程的vruntime = runtime * (NICE_0_LOAD/nice_n_weight)
1 | /* 该表的主要思想是,高一个等级的weight是低一个等级的 1.25 倍 */ |
nice(0)对应的weight是NICE_0_LOAD(1024),nice(-1)对应的weight是NICE_0_LOAD*1.25,nice(1)对应的weight是NICE_0_LOAD/1.25。
NICE_0_LOAD(1024)在schedule计算中是一个非常神奇的数字,他的含义就是基准”1”。因为kernel不能表示小数,所以把1放大称为1024。
1 | scheduler_tick() -> task_tick_fair() -> update_curr(): |
2.2.2、period和ideal_runtime
scheduler_tick()中根据cfs_rq中的se数量计算period和ideal_time,判断当前进程时间是否用完需要调度:
1 | scheduler_tick() -> task_tick_fair() -> entity_tick() -> check_preempt_tick(): |
2.2.3、红黑树(Red Black Tree)

红黑树又称为平衡二叉树,它的特点:
- 1、平衡。从根节点到叶子节点之间的任何路径,差值不会超过1。所以pick_next_task()复杂度为O(log n)。可以看到pick_next_task()复杂度是大于o(1)算法的,但是最大路径不会超过log2(n) - 1,复杂度是可控的。
- 2、排序。左边的节点一定小于右边的节点,所以最左边节点是最小值。
按照进程的vruntime组成了红黑树:
1 | enqueue_task_fair() -> enqueue_entity() -> __enqueue_entity(): |
2.2.4、sched_entity和task_group
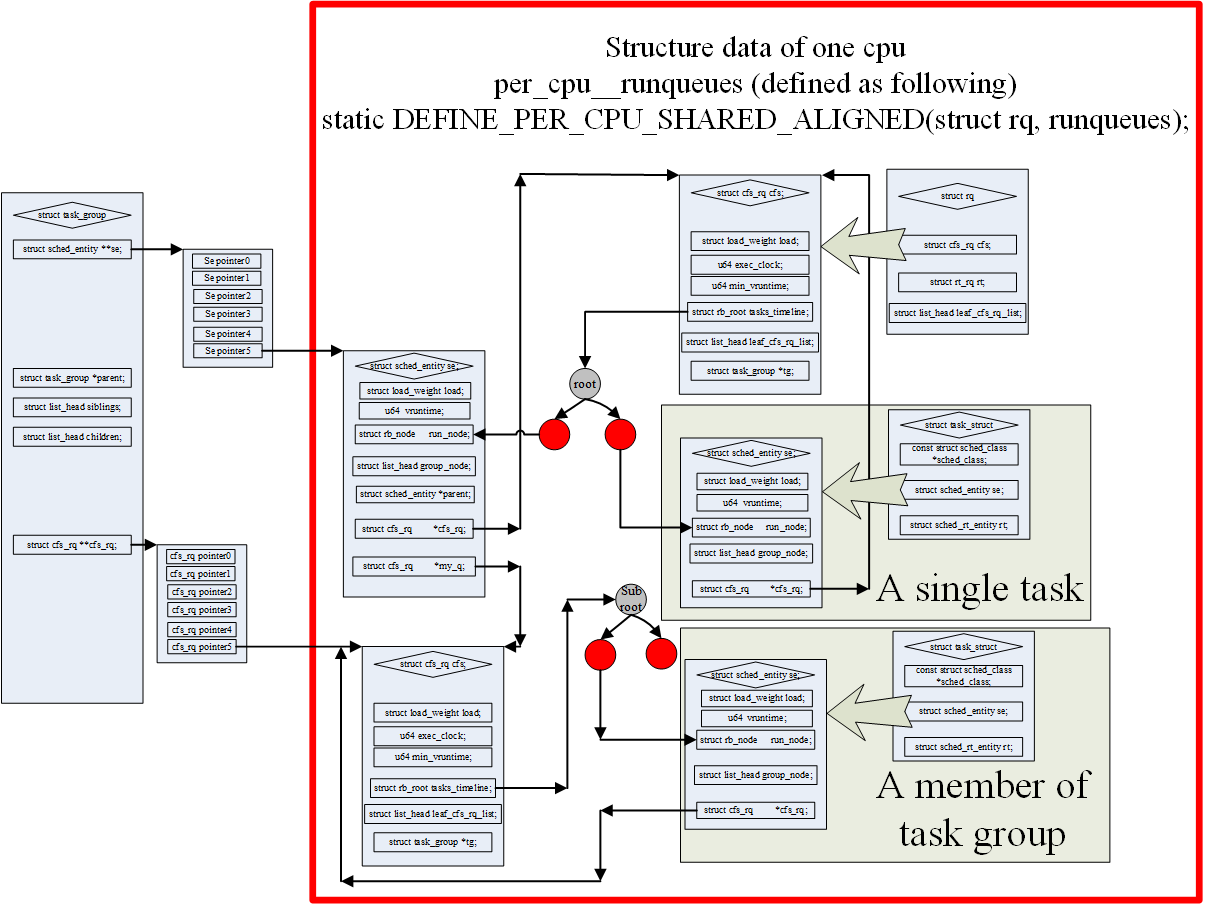
因为新的内核加入了task_group的概念,所以现在不是使用task_struct结构直接参与到schedule计算当中,而是使用sched_entity结构。一个sched_entity结构可能是一个task也可能是一个task_group->se[cpu]。上图非常好的描述了这些结构之间的关系。
其中主要的层次关系如下:
- 1、一个cpu只对应一个rq;
- 2、一个rq有一个cfs_rq;
- 3、cfs_rq使用红黑树组织多个同一层级的sched_entity;
- 4、如果sched_entity对应的是一个task_struct,那sched_entity和task是一对一的关系;
- 5、如果sched_entity对应的是task_group,那么他是一个task_group多个sched_entity中的一个。task_group有一个数组se[cpu],在每个cpu上都有一个sched_entity。这种类型的sched_entity有自己的cfs_rq,一个sched_entity对应一个cfs_rq(se->my_q),cfs_rq再继续使用红黑树组织多个同一层级的sched_entity;3-5的层次关系可以继续递归下去。
2.2.5、scheduler_tick()
关于算法,最核心的部分都在scheduler_tick()函数当中,所以我们来详细的解析这部分代码。
1 | void scheduler_tick(void) |
2.2.6、几个特殊时刻vruntime的变化
关于cfs调度和vruntime,除了正常的scheduler_tick()的计算,还有些特殊时刻需要特殊处理。这些细节用一些疑问来牵引出来:
- 1、新进程的vruntime是多少?
假如新进程的vruntime初值为0的话,比老进程的值小很多,那么它在相当长的时间内都会保持抢占CPU的优势,老进程就要饿死了,这显然是不公平的。
CFS的做法是:取父进程vruntime(curr->vruntime) 和 (cfs_rq->min_vruntime + 假设se运行过一轮的值)之间的最大值,赋给新创建进程。把新进程对现有进程的调度影响降到最小。
1 | _do_fork() -> copy_process() -> sched_fork() -> task_fork_fair(): |
- 2、休眠进程的vruntime一直保持不变吗、
如果休眠进程的 vruntime 保持不变,而其他运行进程的 vruntime 一直在推进,那么等到休眠进程终于唤醒的时候,它的vruntime比别人小很多,会使它获得长时间抢占CPU的优势,其他进程就要饿死了。这显然是另一种形式的不公平。
CFS是这样做的:在休眠进程被唤醒时重新设置vruntime值,以min_vruntime值为基础,给予一定的补偿,但不能补偿太多。
1 | static void |
- 3、休眠进程在唤醒时会立刻抢占CPU吗?
进程被唤醒默认是会马上检查是否库抢占,因为唤醒的vruntime在cfs_rq的最小值min_vruntime基础上进行了补偿,所以他肯定会抢占当前的进程。
CFS可以通过禁止WAKEUP_PREEMPTION来禁止唤醒抢占,不过这也就失去了抢占特性。
1 | try_to_wake_up() -> ttwu_queue() -> ttwu_do_activate() -> ttwu_do_wakeup() -> check_preempt_curr() -> check_preempt_wakeup() |
- 4、进程从一个CPU迁移到另一个CPU上的时候vruntime会不会变?
不同cpu的负载时不一样的,所以不同cfs_rq里se的vruntime水平是不一样的。如果进程迁移vruntime不变也是非常不公平的。
CFS使用了一个很聪明的做法:在退出旧的cfs_rq时减去旧cfs_rq的min_vruntime,在加入新的cfq_rq时重新加上新cfs_rq的min_vruntime。
1 | static void |
2.2.7、cfs bandwidth
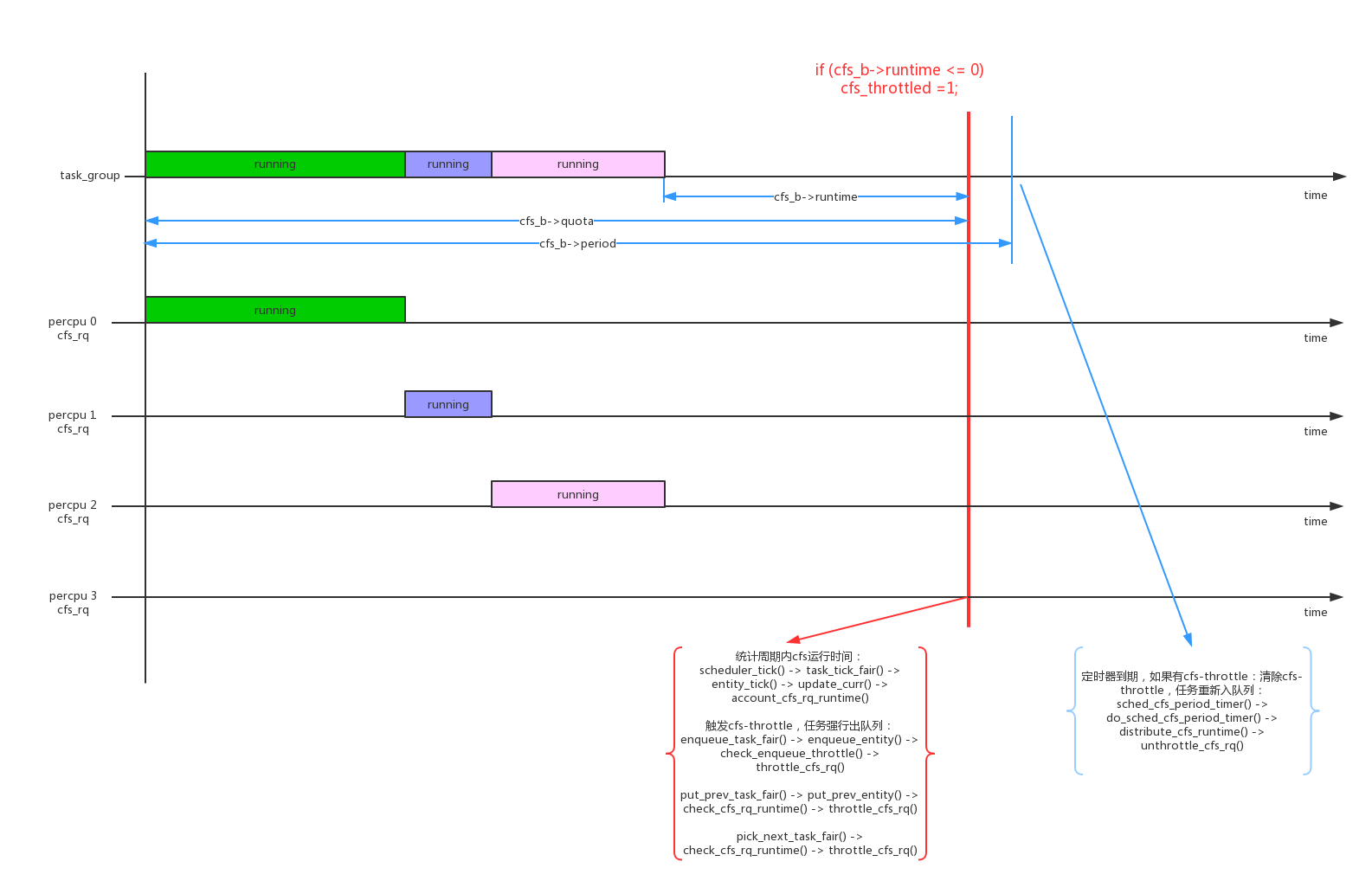
- 1、cfs bandwidth是针对task_group的配置,一个task_group的bandwidth使用一个struct cfs_bandwidth *cfs_b数据结构来控制。
1 | struct cfs_bandwidth { |
其中几个关键的数据结构:cfs_b->period是监控周期,cfs_b->quota是tg的运行配额,cfs_b->runtime是tg剩余可运行的时间。cfs_b->runtime在监控周期开始的时候等于cfs_b->quota,随着tg不断运行不断减少,如果cfs_b->runtime < 0说明tg已经超过bandwidth,触发流量控制;
cfs bandwidth是提供给CGROUP_SCHED使用的,所以cfs_b->quota的初始值都是RUNTIME_INF无限大,所以在使能CGROUP_SCHED以后需要自己配置这些参数。
- 2、因为一个task_group是在percpu上都创建了一个cfs_rq,所以cfs_b->quota的值是这些percpu cfs_rq中的进程共享的,每个percpu cfs_rq在运行时需要向tg->cfs_bandwidth->runtime来申请;
1 | scheduler_tick() -> task_tick_fair() -> entity_tick() -> update_curr() -> account_cfs_rq_runtime() |
- 3、在enqueue_task_fair()、put_prev_task_fair()、pick_next_task_fair()这几个时刻,会check cfs_rq是否已经达到throttle,如果达到cfs throttle会把cfs_rq dequeue停止运行;
1 | enqueue_task_fair() -> enqueue_entity() -> check_enqueue_throttle() -> throttle_cfs_rq() |
- 4、对每一个tg的cfs_b,系统会启动一个周期性定时器cfs_b->period_timer,运行周期为cfs_b->period。主要作用是period到期后检查是否有cfs_rq被throttle,如果被throttle恢复它,并进行新一轮的监控;
1 | sched_cfs_period_timer() -> do_sched_cfs_period_timer() |
2.2.8、sched sysctl参数
系统在sysctl中注册了很多sysctl参数供我们调优使用,在”/proc/sys/kernel/“目录下可以看到:
1 | # ls /proc/sys/kernel/sched_* |
kern_table[]中也有相关的定义:
1 | static struct ctl_table kern_table[] = { |
2.2.9、”/proc/sched_debug”
在/proc/sched_debug中会打印出详细的schedule相关的信息,对应的代码在”kernel/sched/debug.c”中实现:
1 | # cat /proc/sched_debug |
2.2.10、”/proc/schedstat” & “/proc/pid/schedstat”
我们可以通过”/proc/schedstat”读出cpu级别的一些调度统计,具体的代码实现在kernel/sched/stats.c show_schedstat()中:
1 | # cat /proc/schedstat |
可以通过”/proc/pid/schedstat”读出进程级别的调度统计,具体的代码在fs/proc/base.c proc_pid_schedstat()中:
1 | # cat /proc/824/schedstat |
2.3、RT调度算法
分析完normal进程的cfs调度算法,我们再来看看rt进程(SCHED_RR/SCHED_FIFO)的调度算法。RT的调度算法改动很小,组织形式还是以前的链表数组,rq->rt_rq.active.queue[MAX_RT_PRIO]包含100个(0-99)个数组链表用来存储runnable的rt线程。rt进程的调度通过rt_sched_class系列函数来实现。
SCHED_FIFO类型的rt进程调度比较简单,优先级最高的一直运行,直到主动放弃运行。
SCHED_RR类型的rt进程在相同优先级下进行时间片调度,每个时间片的时间长短可以通过sched_rr_timeslice变量来控制:
1 | # cat /proc/sys/kernel/sched_rr_timeslice_ms // SCHED_RR的时间片为25ms |
2.3.1、task_tick_rt()
1 | scheduler_tick() -> task_tick_rt() |
2.3.2、rq->rt_avg
我们计算rq->rt_avg(累加时间*freq_capacity),主要目的是给CPU_FREQ_GOV_SCHED使用。
CONFIG_CPU_FREQ_GOV_SCHED的主要思想是cfs和rt分别计算cpu_sched_capacity_reqs中的rt、cfs部分,在update_cpu_capacity_request()中综合cfs和rt的freq_capacity request,调用cpufreq框架调整一个合适的cpu频率。CPU_FREQ_GOV_SCHED是用来取代interactive governor的。
1 | /* (1) cfs对cpu freq capcity的request, |
针对CONFIG_CPU_FREQ_GOV_SCHED,rt有3条关键计算路径:
- 1、rt负载的(rq->rt_avg)的累加:scheduler_tick() -> task_tick_rt() -> update_curr_rt() -> sched_rt_avg_update()
2、rt负载的老化:scheduler_tick() -> update_cpu_load() -> update_cpu_load() -> sched_avg_update()
或者scheduler_tick() -> task_tick_rt() -> sched_rt_update_capacity_req() -> sched_avg_update()3、rt request的更新:scheduler_tick() -> task_tick_rt() -> sched_rt_update_capacity_req() -> set_rt_cpu_capacity()
同样,cfs也有3条关键计算路径:
- 1、cfs负载的(rq->rt_avg)的累加:
- 2、cfs负载的老化:
- 3、cfs request的更新:scheduler_tick() -> sched_freq_tick() -> set_cfs_cpu_capacity()
在进行smp的loadbalance时也有相关计算:run_rebalance_domains() -> rebalance_domains() -> load_balance() -> find_busiest_group() -> update_sd_lb_stats() -> update_group_capacity() -> update_cpu_capacity() -> scale_rt_capacity()
我们首先对rt部分的路径进行分析:
- rt负载老化sched_avg_update():
1 | void sched_avg_update(struct rq *rq) |
- rt frq_capability request的更新:scheduler_tick() -> task_tick_rt() -> sched_rt_update_capacity_req() -> set_rt_cpu_capacity()
1 | static void sched_rt_update_capacity_req(struct rq *rq) |
2.3.3、rt bandwidth(rt-throttle)
基于时间我们还可以对的rt进程进行带宽控制(bandwidth),超过流控禁止进程运行。这也叫rt-throttle。
- rt-throttle的原理是:规定一个监控周期,在这个周期里rt进程的运行时间不能超过一定时间,如果超过则进入rt-throttle状态,进程被强行停止运行退出rt_rq,且rt_rq也不能接受新的进程来运行,直到下一个周期开始才能退出rt-throttle状态,同时开始下一个周期的bandwidth计算。这样就达到了带宽控制的目的。
1 | # cat /proc/sys/kernel/sched_rt_period_us // rt-throttle的周期是1s |
上面这个实例的意思就是rt-throttle的周期是1s,1s周期内可以运行的时间为950ms。rt进程在1s以内如果运行时间达到950ms则会被强行停止,1s时间到了以后才会被恢复,这样进程就被强行停止了50ms。
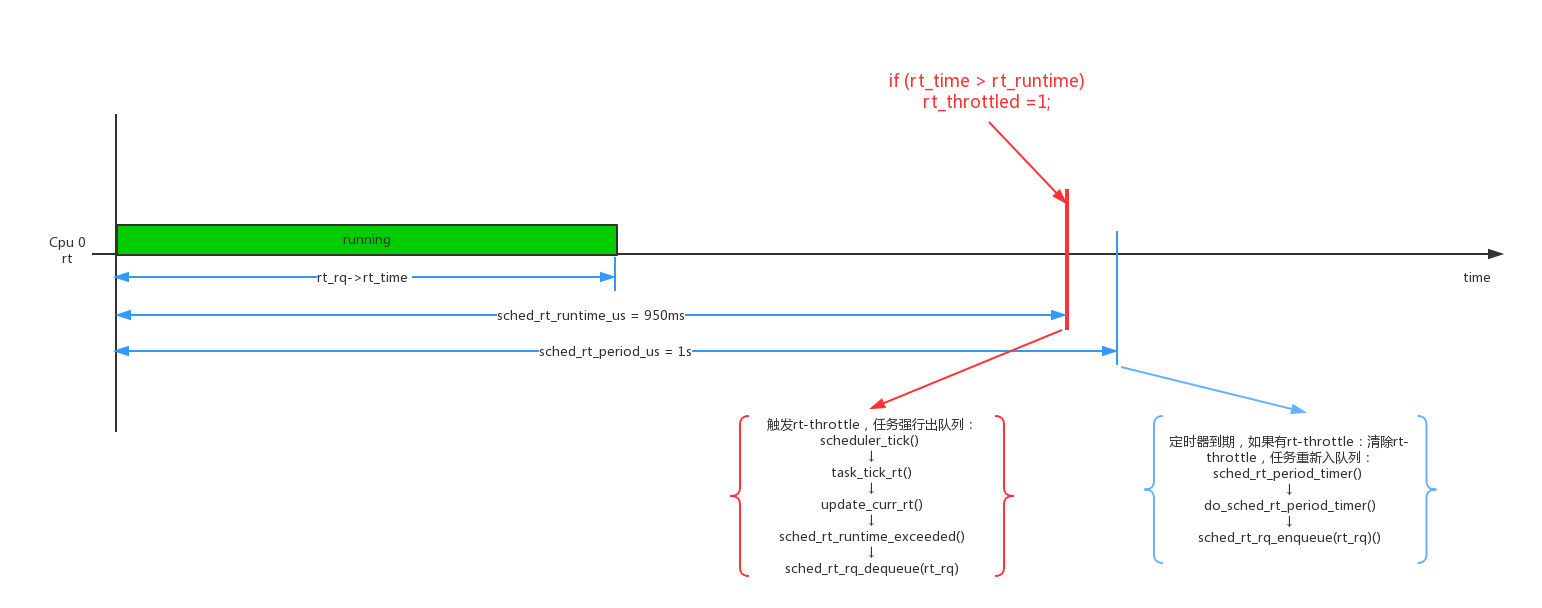
下面我们来具体分析一下具体代码:
1 | scheduler_tick() -> task_tick_rt() |
从上面的代码中可以看到rt-throttle的计算方法大概如下:每个tick累加运行时间rt_rq->rt_time,周期内可运行的额度时间为rt_rq->rt_runtime(950ms),一个周期大小为rt_rq->tg->rt_bandwidth.rt_period(默认1s)。如果(rt_rq->rt_time > rt_rq->rt_runtime),则发生rt-throttle了。
发生rt-throttle以后,rt_rq被强行退出,rt进程被强行停止运行。如果period 1s, runtime 950ms,那么任务会被强制停止50ms。但是下一个周期到来以后,任务需要退出rt-throttle状态。系统把周期计时和退出rt-throttle状态的工作放在hrtimer do_sched_rt_period_timer()中完成。
每个rt进程组task_group公用一个hrtimer sched_rt_period_timer(),在rt task_group创建时分配,在有进程入tg任何一个rt_rq时启动,在没有任务运行时hrtimer会停止运行。
1 | void init_rt_bandwidth(struct rt_bandwidth *rt_b, u64 period, u64 runtime) |
我们看看timer时间到期后的操作:
1 | static enum hrtimer_restart sched_rt_period_timer(struct hrtimer *timer) |
3、负载计算
schedule里面这个负载(load average)的概念常常被理解成cpu占用率,这个有比较大的偏差。schedule不使用cpu占用率来评估负载,而是使用平均时间runnable的数量来评估负载。
shedule也分了几个层级来计算负载:
- 1、entity级负载计算:update_load_avg()
- 2、cpu级负载计算:update_cpu_load_active()
- 3、系统级负载计算:calc_global_load_tick()
计算负载的目的是为了去做负载均衡,下面我们逐个介绍各个层级负载算法和各种负载均衡算法。
3.1、PELT(Per-Entity Load Tracking)Entity级的负载计算
- Entity级的负载计算也称作PELT(Per-Entity Load Tracking)。
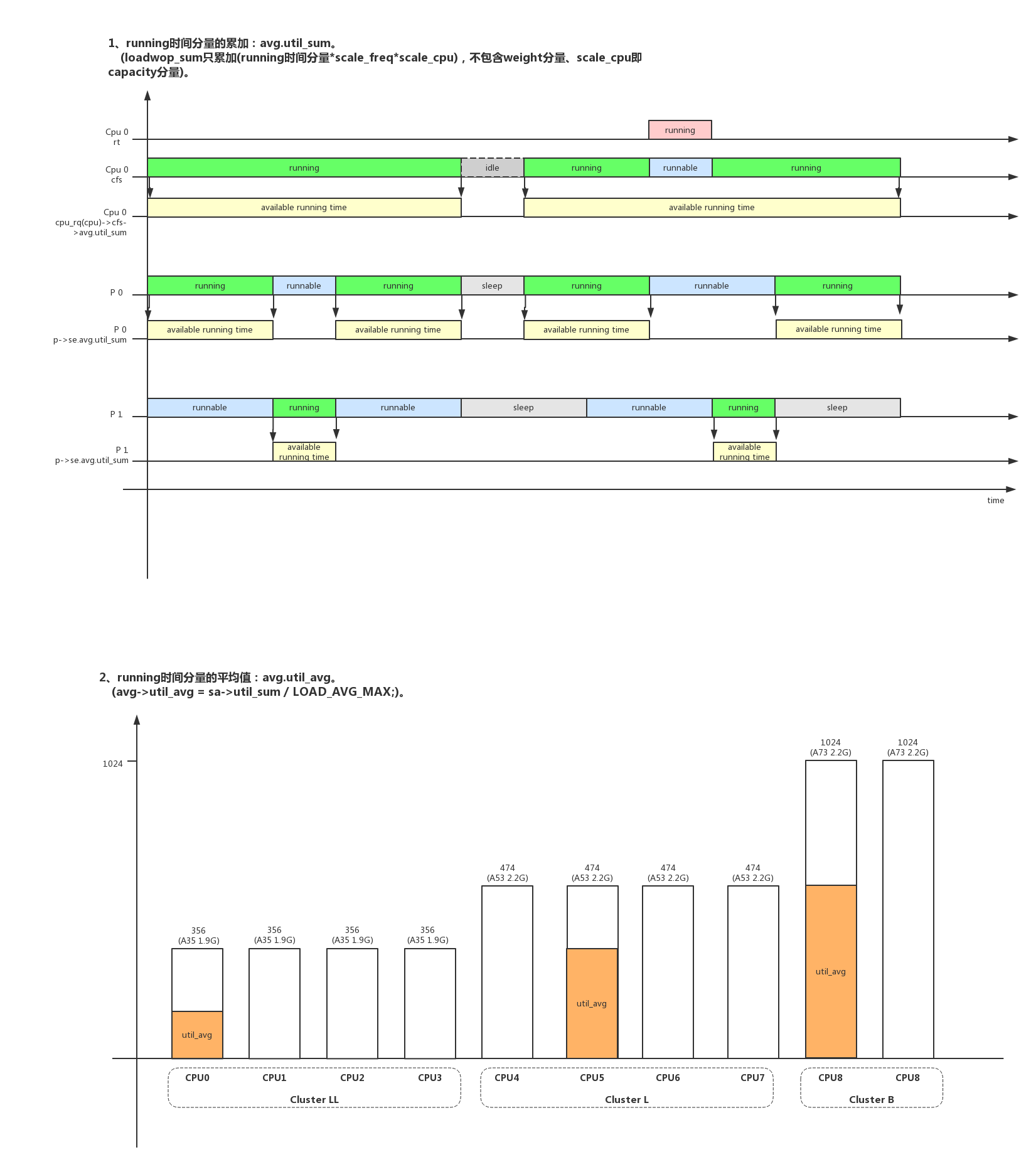
- 注意负载计算时使用的时间都是实际运行时间而不是虚拟运行时间vruntime。
1 | scheduler_tick() -> task_tick_fair() -> entity_tick() -> update_load_avg(): |
3.1.1、核心函数__update_load_avg()
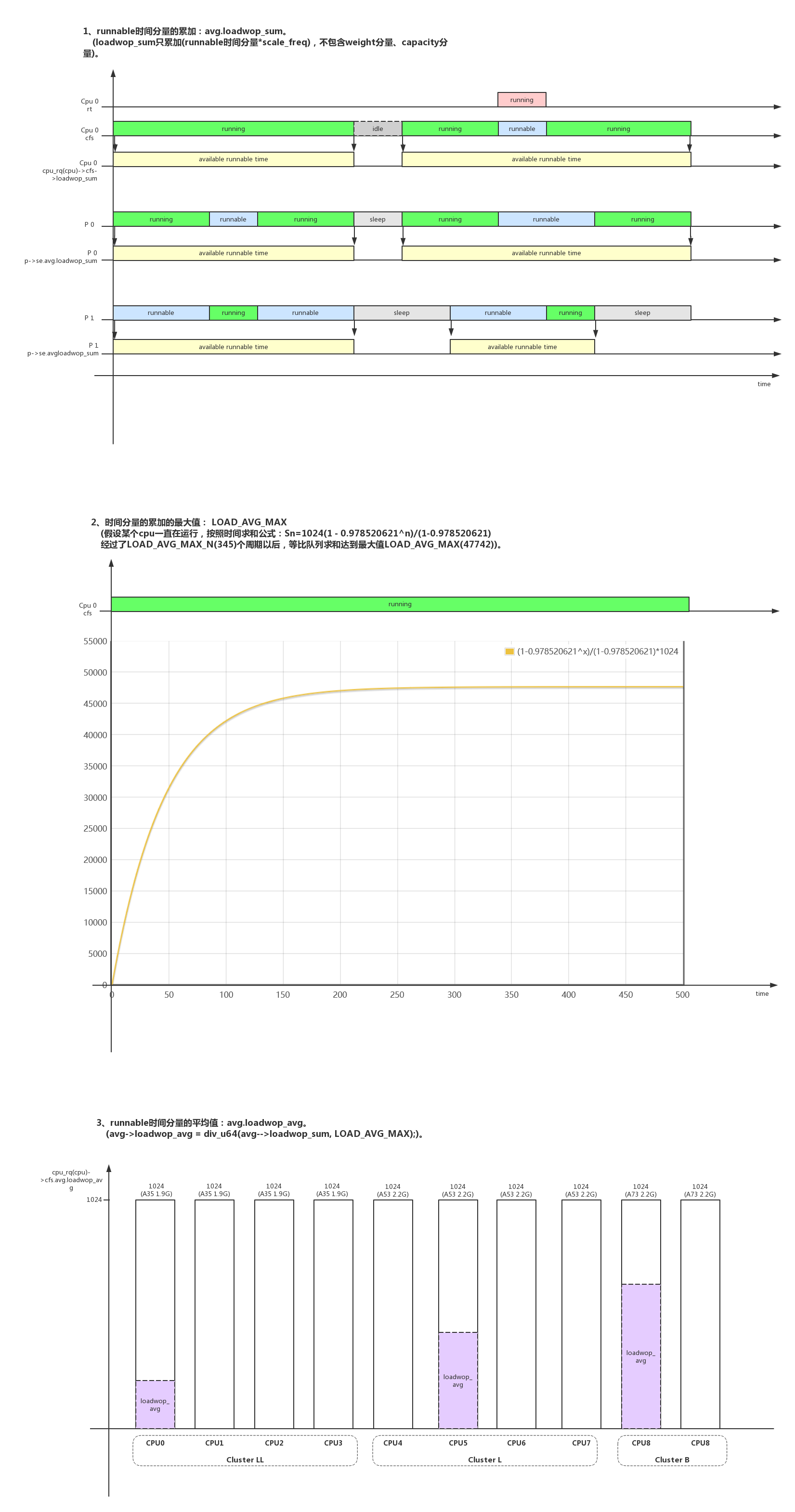
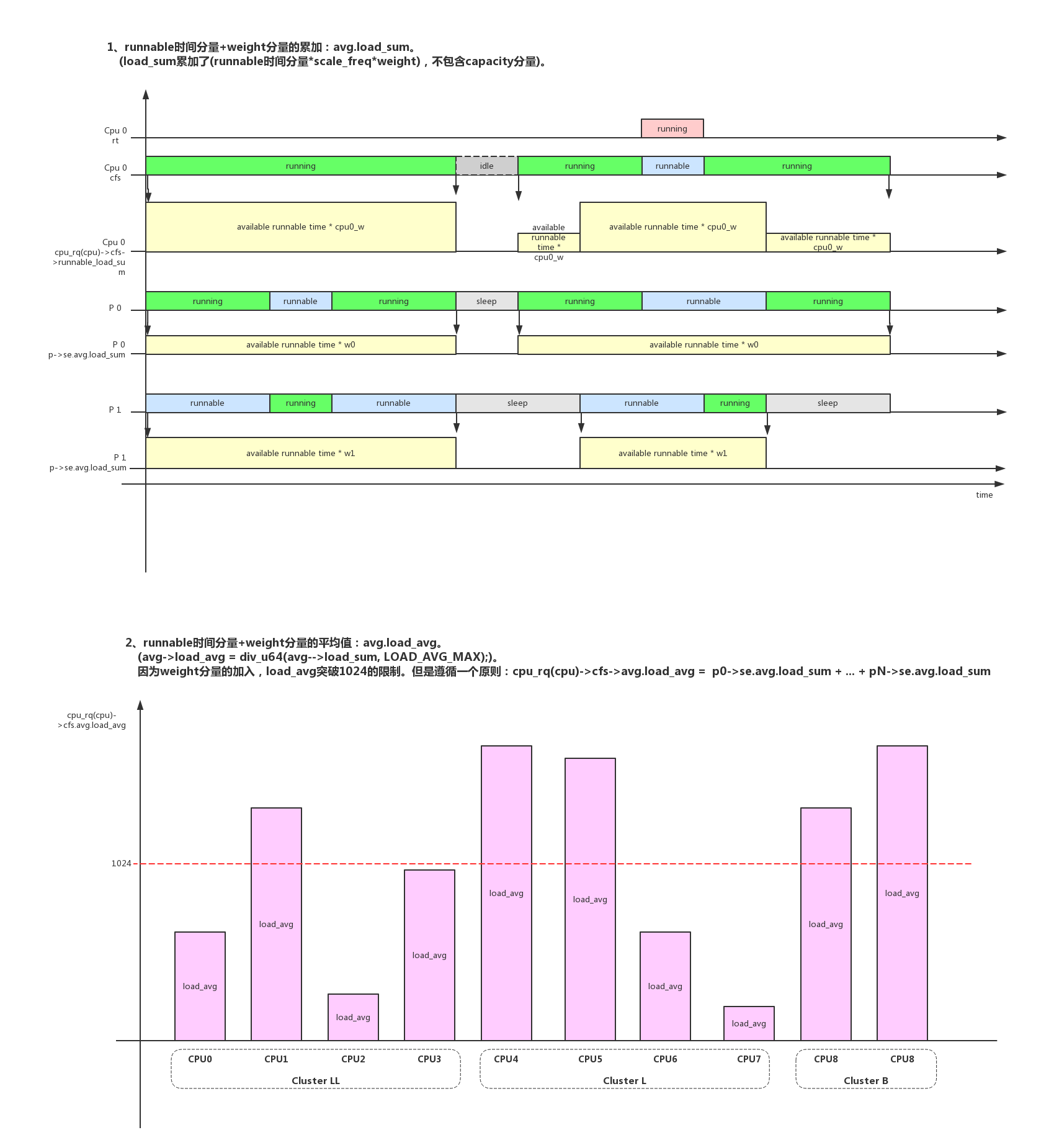
__update_load_avg()函数是计算负载的核心,他的核心思想还是求一个相对值。这时1024变量又登场了,前面说过因为内核不能表示分数,所以把1扩展成1024。和负载相关的各个变量因子都使用1024来表达相对能力:时间、weight(nice优先级)、cpufreq、cpucapacity。
- 1、等比队列(geometric series)的求和;
把时间分成1024us(1ms)的等分。除了当前等分,过去等分负载都要进行衰减,linux引入了衰减比例 y = 0.978520621,y^32 = 0.5。也就是说一个负载经过1024us(1ms)以后不能以原来的值参与计算了,要衰减到原来的0.978520621倍,衰减32个1024us(1ms)周期以后达到原来的0.5倍。
每个等分的衰减比例都是不一样的,所以最后的负载计算变成了一个等比队列(geometric series)的求和。等比队列的特性和求和公式如下(y即是公式中的等比比例q):

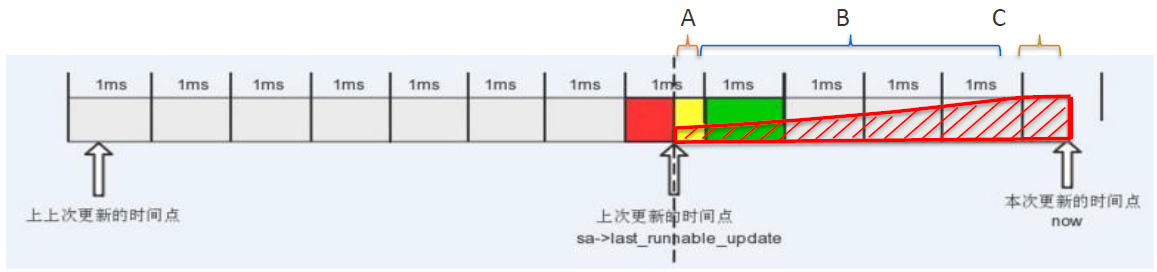
- 2、时间分段;
在计算一段超过1024us(1ms)的时间负载时,__update_load_avg()会把需要计算的时间分成3份:时间段A和之前计算的负载补齐1024us,时间段B是多个1024us的取整,时间段C是最后不能取整1024us的余数;
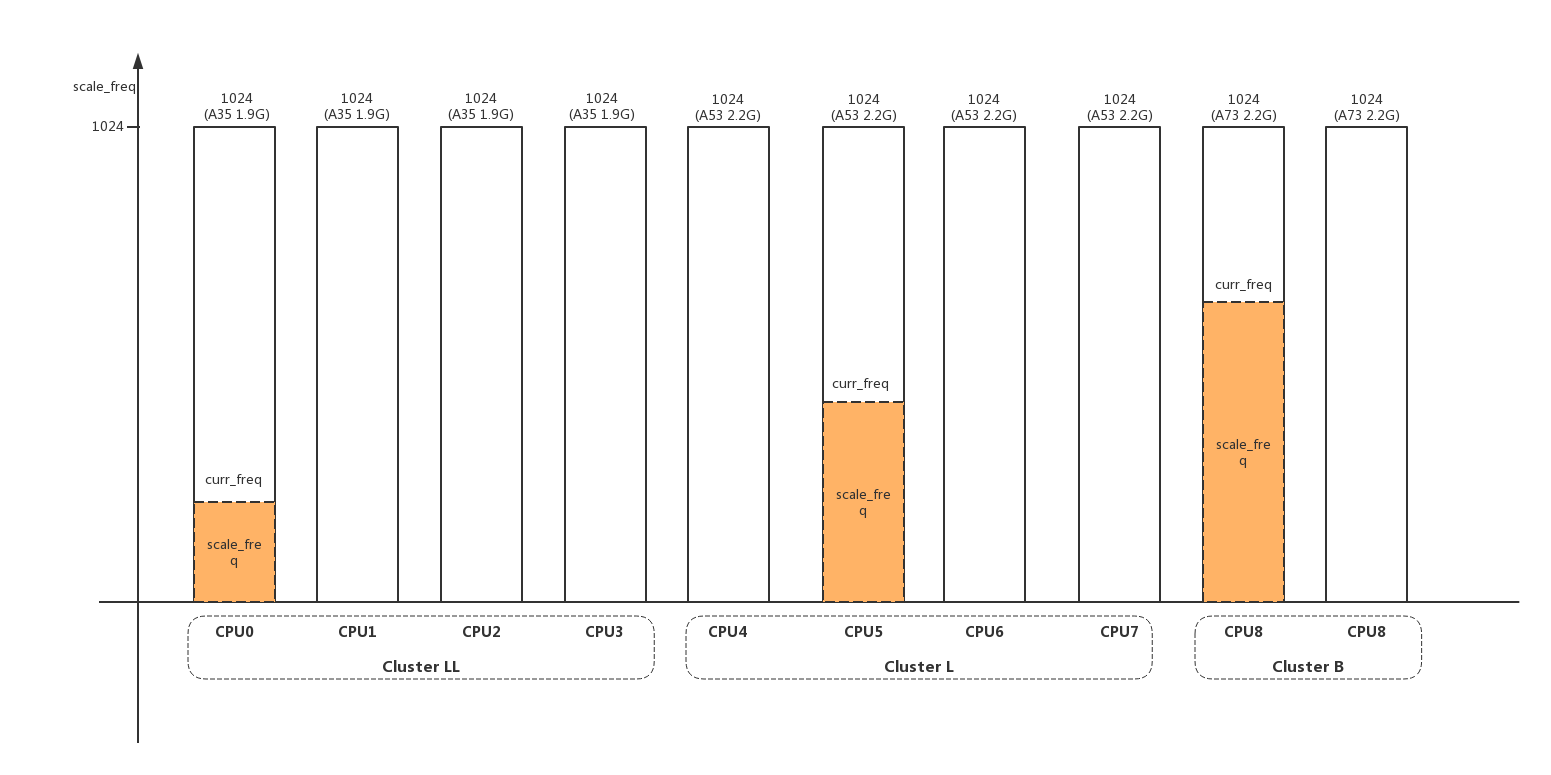
- 3、scale_freq、scale_cpu的含义;
scale_freq表示 当前freq 相对 本cpu最大freq 的比值:scale_freq = (cpu_curr_freq / cpu_max_freq) * 1024:
1 | static __always_inline int |
scale_cpu表示 (当前cpu最大运算能力 相对 所有cpu中最大的运算能力 的比值) (cpufreq_policy的最大频率 相对 本cpu最大频率 的比值),:scale_cpu = cpu_scale max_freq_scale / 1024。后续的rebalance计算中经常使用capacity的叫法,和scale_cpu是同一含义。因为max_freq_scale基本=1024,所以scale_cpu基本就是cpu_scale的值:
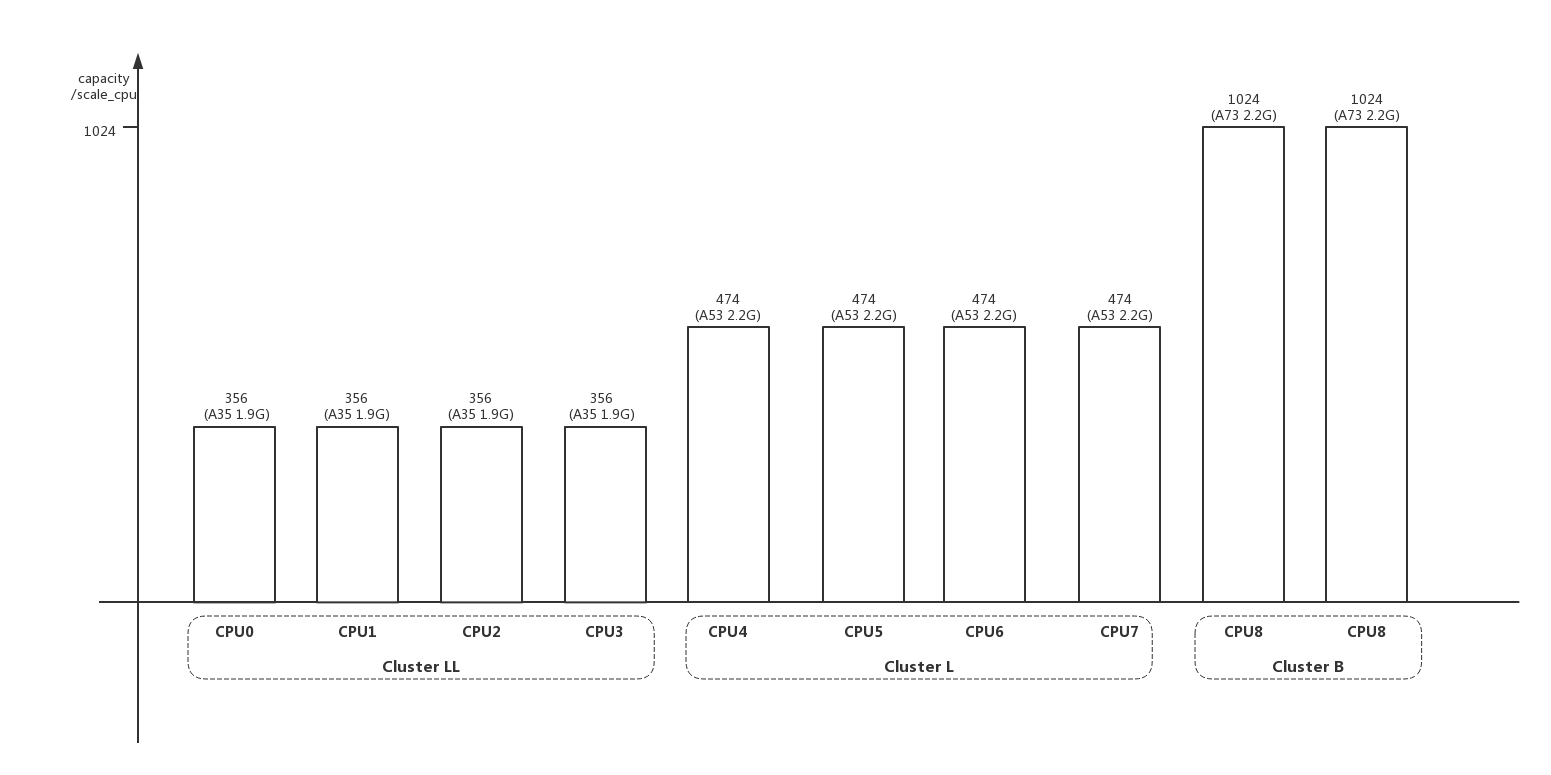
1 | unsigned long arch_scale_cpu_capacity(struct sched_domain *sd, int cpu) |
cpu_scale表示 当前cpu最大运算能力 相对 所有cpu中最大的运算能力 的比值:cpu_scale = ((cpu_max_freq efficiency) / max_cpu_perf) 1024
当前cpu的最大运算能力等于当前cpu的最大频率乘以当前cpu每clk的运算能力efficiency,efficiency相当于DMIPS,A53/A73不同架构每个clk的运算能力是不一样的:
1 | /* (1.1) 不同架构的efficiency */ |
例如mt6799一共有10个cpu,为“4 A35 + 4 A53 + 2 A73”架构。使用计算法计算的cpu_scale相关值:
1 | /* rate是从dts读取的和实际不符合,只是表达一下算法 */ |
mt6799实际是使用查表法直接得到cpu_scale的值:
1 | struct upower_tbl upower_tbl_ll_1_FY = { |
max_freq_scale表示 cpufreq_policy的最大频率 相对 本cpu最大频率 的比值:max_freq_scale = (policy->max / cpuinfo->max_freq) * 1024
1 | static void |
- 4、decay_load();
decay_load(val,n)的意思就是负载值val经过n个衰减周期(1024us)以后的值,主要用来计算时间段A即之前的值的衰减值。
1 | * Approximate: |
- 5、__compute_runnable_contrib();
decay_load()只是计算y^n,而__compute_runnable_contrib()是计算一个对比队列的和:y + y^2 + y^3 … + y^n。计算时间段B的负载。
runnable_avg_yN_sum[]数组是使用查表法来计算n=32位内的等比队列求和:
runnable_avg_yN_sum[1] = y^1 1024 = 0.978520621 1024 = 1002
runnable_avg_yN_sum[1] = (y^1 + y^2) 1024 = 1982
…
runnable_avg_yN_sum[1] = (y^1 + y^2 .. + y^32) 1024 = 23371
1 | /* |
- 6、se->on_rq;
在系统从睡眠状态被唤醒,睡眠时间会不会被统计进load_avg?答案是不会。
系统使用了一个技巧来处理这种情况,调用__update_load_avg()函数时,第三个参数weight = se->on_rq * scale_load_down(se->load.weight)。运行状态时se->on_rq=1,weight>0,老负载被老化,新负载被累加;在进程从睡眠状态被唤醒时,se->on_rq=0,weight=0,只有老负载被老化,睡眠时间不会被统计;
1 | enqueue_task_fair() |
相同的技巧是在更新cfs_rq负载时,调用__update_load_avg()函数时,第三个参数weight = scale_load_down(cfs_rq->load.weight)。如果cfs_rq没有任何进程时cfs_rq->load.weight=0,如果cfs_rq有进程时cfs_rq->load.weight=进程weight的累加值,这样在cfs没有进程idle时,就不会统计负载。但是如果被RT进程抢占,还是会统计(相当于cfs_rq的runnable状态)。
1 | static inline int update_cfs_rq_load_avg(u64 now, struct cfs_rq *cfs_rq) |
- 7、LOAD_AVG_MAX;
从上面的计算过程解析可以看到,负载计算就是一个等比队列的求和。对于负载其实我们不关心他的绝对值,而是关心他和最大负载对比的相对值。所谓最大负载就是时间轴上一直都在,且能力值也都是最大的1(1024)。
我们从上面等比队列的求和公式:Sn = a1(1-q^n)/(1-q) = 1024(1 - 0.978520621^n)/(1-0.978520621)。我们来看这个求和函数的曲线。
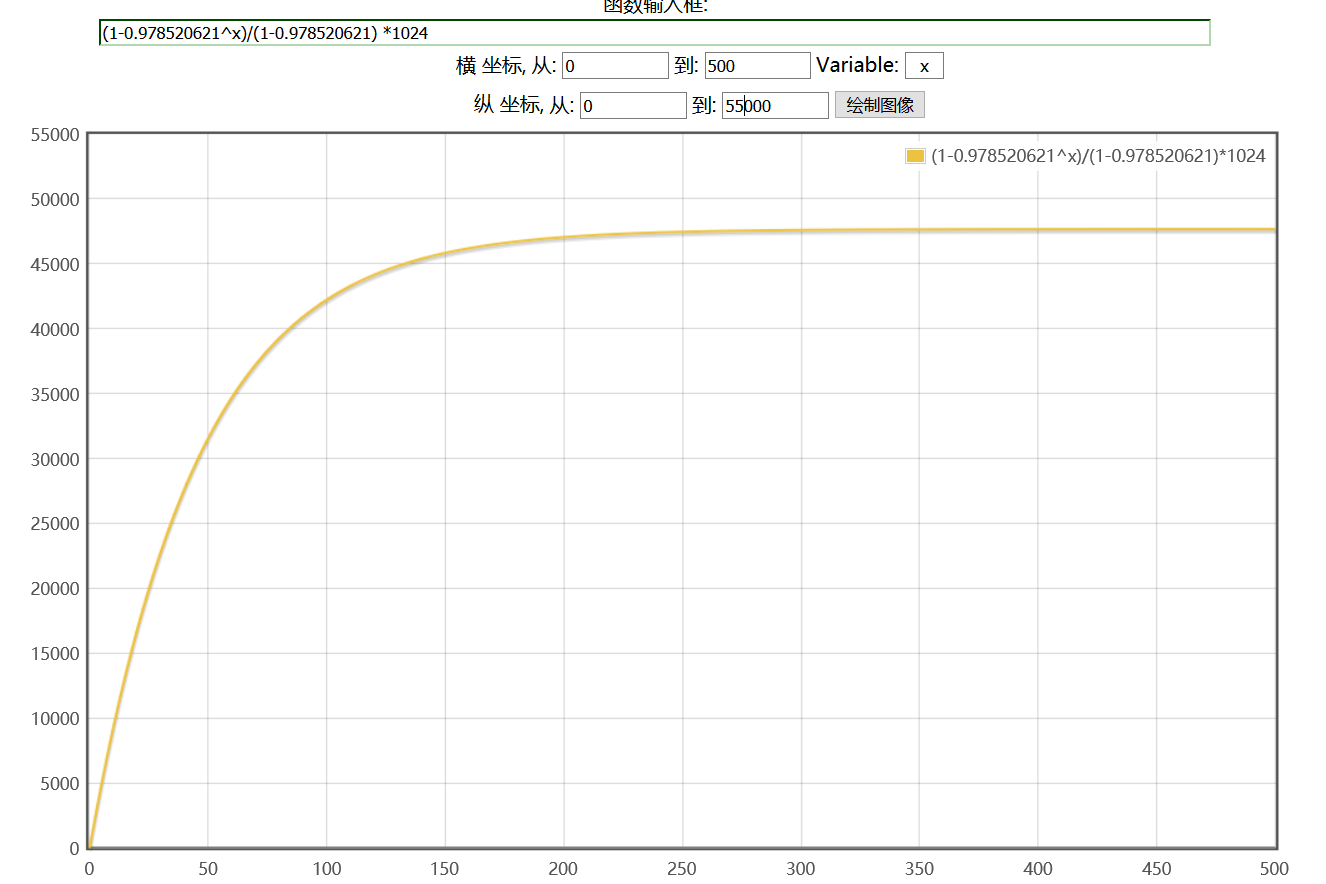
从曲线上分析,当x到达一定值后y趋于稳定,不再增长。
利用这个原理linux定义出了负载最大值LOAD_AVG_MAX。含义是经过了LOAD_AVG_MAX_N(345)个周期以后,等比队列求和达到最大值LOAD_AVG_MAX(47742):
1 | /* |
平均负载都是负载和最大负载之间的比值:
1 | static __always_inline int |
- 8、struct sched_avg数据成员的含义;
1 | struct sched_avg { |
- 8.1、loadwop_avg:
- 8.2、load_avg:
- 8.3、util_avg:
- 8.4、scale_freq:
需要特别强调的是loadwop_avg、load_avg、util_avg在他们的时间分量中都乘以了scale_freq,所以上面几图都是他们在max_freq下的表现,实际的负载还受当前freq的影响:
- 8.5、capacity/scale_cpu
capacity是在smp负载均衡时更新:
1 | run_rebalance_domains() -> rebalance_domains() -> load_balance() -> find_busiest_group() -> update_sd_lb_stats() -> update_group_capacity() -> update_cpu_capacity() |
获取capacity的函数有几种:capacity_orig_of()返回最大capacity,capacity_of()返回减去rt占用的capacity,capacity_curr_of()返回当前频率下的最大capacity。
1 | static inline unsigned long capacity_of(int cpu) |
- 9、__update_load_avg()函数完整的计算过程:
1 | /* |
3.2、cpu级的负载计算update_cpu_load_active()
__update_load_avg()是计算se/cfs_rq级别的负载,在cpu级别linux使用update_cpu_load_active()来计算整个cpu->rq负载的变化趋势。计算也是周期性的,周期为1 tick。
暂时我理解,这个rq load没有计入rt的负载。
1 | scheduler_tick() |
代码注释中详细解释了cpu_load的计算方法:
1、每个tick计算不同idx时间等级的load,计算公式:load = (2^idx - 1) / 2^idx load + 1 / 2^idx cur_load
2、如果cpu因为noHZ错过了(n-1)个tick的更新,那么计算load要分两步:
首先老化(decay)原有的load:load = ((2^idx - 1) / 2^idx)^(n-1) load
再按照一般公式计算load:load = (2^idx - 1) / 2^idx) load + 1 / 2^idx * cur_load3、为了decay的加速计算,设计了decay_load_missed()查表法计算:
1 | /* |
- 1、cpu_load[]含5条均线,反应不同时间窗口长度下的负载情况;主要供load_balance()在不
同场景判断是否负载平衡的比较基准,常用为cpu_load[0]和cpu_load[1]; - 2、cpu_load[index]对应的时间长度为{0, 8, 32, 64, 128},单位为tick;
- 3、移动均线的目的在于平滑样本的抖动,确定趋势的变化方向;
3.3、系统级的负载计算calc_global_load_tick()
系统级的平均负载(load average)可以通过以下命令(uptime、top、cat /proc/loadavg)查看:
1 | $ uptime |
“load average:”后面的3个数字分别表示1分钟、5分钟、15分钟的load average。可以从几方面去解析load average:
- If the averages are 0.0, then your system is idle.
- If the 1 minute average is higher than the 5 or 15 minute averages, then load is increasing.
- If the 1 minute average is lower than the 5 or 15 minute averages, then load is decreasing.
- If they are higher than your CPU count, then you might have a performance problem (it depends).
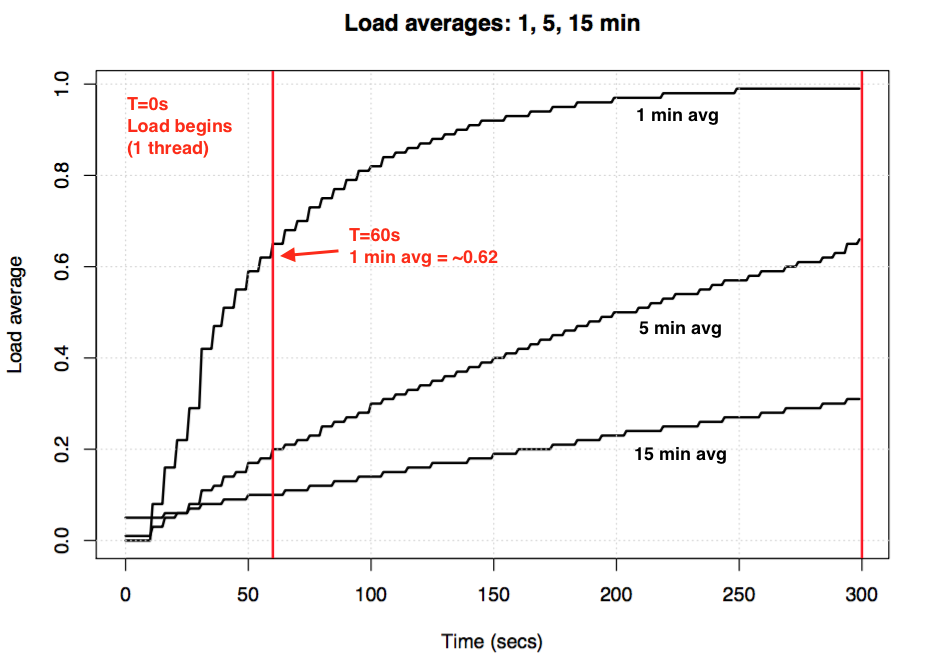
最早的系统级平均负载(load average)只会统计runnable状态。但是linux后面觉得这种统计方式代表不了系统的真实负载;举一个例子:系统换一个低速硬盘后,他的runnable负载还会小于高速硬盘时的值;linux认为睡眠状态(TASK_INTERRUPTIBLE/TASK_UNINTERRUPTIBLE)也是系统的一种负载,系统得不到服务是因为io/外设的负载过重;系统级负载统计函数calc_global_load_tick()中会把(this_rq->nr_running+this_rq->nr_uninterruptible)都计入负载;
3.3.1、calc_global_load_tick()
我们来看详细的代码解析。
- 1、每个cpu每隔5s更新本cpu rq的(nr_running+nr_uninterruptible)任务数量到系统全局变量calc_load_tasks,calc_load_tasks是整系统多个cpu(nr_running+nr_uninterruptible)任务数量的总和,多cpu在访问calc_load_tasks变量时使用原子操作来互斥。
1 | scheduler_tick() |
- 2、多个cpu更新calc_load_tasks,但是计算load只由一个cpu来完成,这个cpu就是tick_do_timer_cpu。在linux time一文中,我们看到这个cpu就是专门来更新时间戳timer的(update_wall_time())。实际上它在更新时间戳的同时也会调用do_timer() -> calc_global_load()来计算系统负载。
核心算法calc_load()的思想也是:旧的load老化系数 + 新load系数
假设单位1为FIXED_1=2^11=2028,EXP_1=1884、EXP_5=2014、EXP_15=2037,load的计算:
load = old_load(EXP_?/FIXED_1) + new_load(FIXED_1-EXP_?)/FIXED_1
1 | do_timer() -> calc_global_load() |
3、/proc/loadavg
代码实现在kernel/fs/proc/loadavg.c中:
1 | static int loadavg_proc_show(struct seq_file *m, void *v) |
3.4 占用率统计
3.4.1、cputime.c
top命令利用“/proc/stat”、“/proc/stat”来做cpu占用率统计,可以在AOSP/system/core/toolbox/top.c中查看top代码实现。
读取/proc/stat可以查看系统各种状态的时间统计,代码实现在fs/proc/stat.c show_stat()。
1 | # cat /proc/stat |
读取/proc/pid/stat可以查看进程各种状态的时间统计,代码实现在fs/proc/array.c do_task_stat()。
1 | # cat /proc/824/stat |
相关的时间统计是在cputime.c中实现的,在每个tick任务中通过采样法计算系统和进程不同状态下的时间统计,这种方法精度是不高的:
- 1、采样法只能在tick时采样,中间发生了任务调度不可统计;
- 2、系统统计了以下几种类型:
1 | enum cpu_usage_stat { |
- 3、在nohz模式时,退出nohz时会使用tick_nohz_idle_exit() -> tick_nohz_account_idle_ticks() -> account_idle_ticks()加上nohz损失的idle时间;
tick统计的代码详细解析如下:
1 | update_process_times() -> account_process_tick() |
4、负载均衡
4.1、SMP负载均衡
4.1.1、Scheduling Domains
4.1.1.1、Scheduling Domains概念
借用Linux Scheduling Domains的描述,阐述Scheduling Domains的概念。
一个复杂的高端系统由上到下可以这样构成:
- 1、它是一个 NUMA 架构的系统,系统中的每个 Node 访问系统中不同区域的内存有不同的速度。
- 2、同时它又是一个 SMP 系统。由多个物理 CPU(Physical Package) 构成。这些物理 CPU 共享系统中所有的内存。但都有自己独立的 Cache 。
- 3、每个物理 CPU 又由多个核 (Core) 构成,即 Multi-core 技术或者叫 Chip-level Multi processor(CMP) 。这些核都被集成在一块 die 里面。一般有自己独立的 L1 Cache,但可能共享 L2 Cache 。
- 4、每个核中又通过 SMT 之类的技术实现多个硬件线程,或者叫 Virtual CPU( 比如 Intel 的 Hyper-threading 技术 ) 。这些硬件线程,逻辑上看是就是一个 CPU 。它们之间几乎所有的东西都共享。包括 L1 Cache,甚至是逻辑运算单元 (ALU) 以及 Power 。
可以看到cpu是有多个层级的,cpu和越近的层级之间共享的资源越多。所以进程在cpu之间迁移是有代价的,从性能的角度看,迁移跨越的层级越大性能损失越大。另外还需要从功耗的角度来考虑进程迁移的代价,这就是EAS考虑的。
4.1.1.2、arm64 cpu_topology
arm64架构的cpu拓扑结构存储在cpu_topology[]变量当中:
1 | /* |
cpu_topology[]是parse_dt_cpu_capacity()函数解析dts中的信息建立的:
1 | kernel_init() -> kernel_init_freeable() -> smp_prepare_cpus() -> init_cpu_topology() -> parse_dt_topology() |
cpu同一层次的关系cpu_topology[cpu].core_sibling/thread_sibling会在update_siblings_masks()中更新:
1 | kernel_init() -> kernel_init_freeable() -> smp_prepare_cpus() -> store_cpu_topology() -> update_siblings_masks() |
以mt6799为例,topology为”4A35 + 4A53 + 2*A73”,dts中定义如下:
1 | mt6799.dtsi: |
- 经过parse_dt_topology()、update_siblings_masks()解析后得到cpu_topology[}的值为:
1 | cpu 0 cluster_id = 0, core_id = 0, core_sibling = 0xf |
4.1.1.3、Scheduling Domains的初始化
在kernel_init_freeable()中,调用smp_prepare_cpus()初始化完cpu的拓扑关系,再调用smp_init()唤醒cpu,紧接会调用sched_init_smp()初始化系统的Scheduling Domains。
关于拓扑的层次默认可选的有3层:SMT/MC/DIE。arm目前不支持多线程技术,所以现在只支持2层:MC/DIE。
1 | /* |
arm64使用的SDTL如下:
1 | static struct sched_domain_topology_level arm64_topology[] = { |
具体的Scheduling Domains的初始化代码分析如下:
1 | kernel_init() -> kernel_init_freeable() -> sched_init_smp() -> init_sched_domains(cpu_active_mask): |
init_sched_domains()是在系统启动时创建sched_domain,如果发生cpu hotplug系统中online的cpu发生变化时,会调用partition_sched_domains重新构造系统的sched_domain。
1 | cpu_up() -> _cpu_up() -> __raw_notifier_call_chain() -> cpuset_cpu_active() -> cpuset_update_active_cpus() -> partition_sched_domains() -> build_sched_domains(); |
4.1.1.4、mt6799的Scheduling Domains
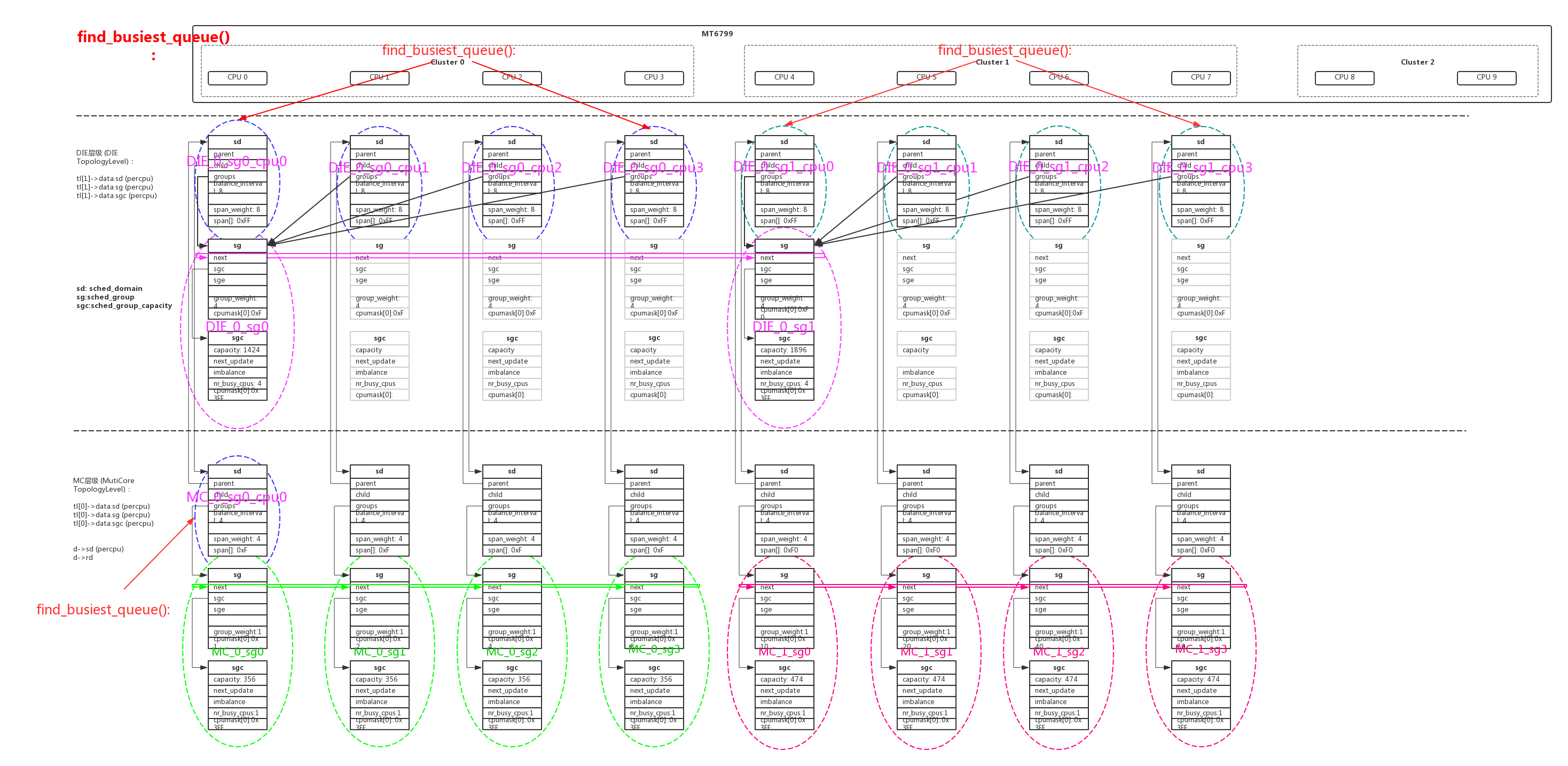
在系统初始化时,因为cmdline中传入了“maxcpus=8”所以setup_max_cpus=8,smp只是启动了8个核,mt6799的另外2个大核是在后面才启动的。我们看看在系统启动8个核的时候,Scheduling Domains是什么样的。
在启动的时候每个层次的tl对每个cpu都会分配sd、sg、sgc的内存空间,但是建立起有效链接后有些sg、sgc空间是没有用上的。没有使用的内存后面会在claim_allocations()中标识出来,build_sched_domains()函数返回之前调用__free_domain_allocs()释放掉。
1 | kernel_init() -> kernel_init_freeable() -> sched_init_smp() -> init_sched_domains() -> build_sched_domains() -> __visit_domain_allocation_hell() -> __sdt_alloc(): |
建立链接以后每个层次tl的sd、sg之间的关系:
1 | kernel_init() -> kernel_init_freeable() -> sched_init_smp() -> init_sched_domains() -> build_sched_domains() -> build_sched_groups(): |
用图形表达的关系如下:
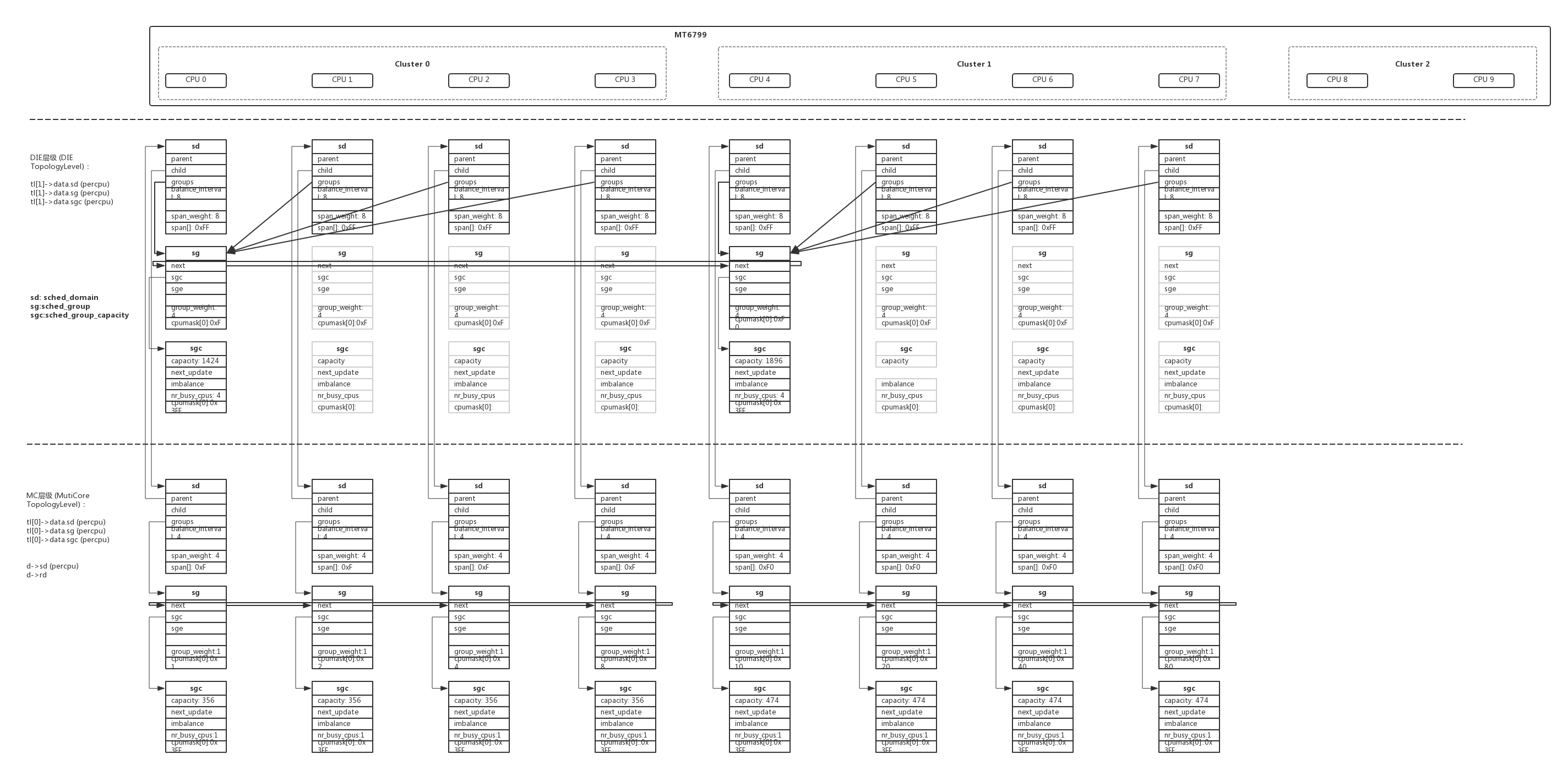
每个sched_domain中的参数也非常重要,在函数sd_init()中初始化,在smp负载均衡时会频繁的使用这些参数和标志:
| sd 参数 | tl MC 层级 | tl DIE 层级 |
| sd->min_interval | 4 | 8 |
| sd->max_interval | 8 | 16 |
| sd->busy_factor | 32 | 32 |
| sd->imbalance_pct | 117 | 125 |
| sd->cache_nice_tries | 1 | 1 |
| sd->busy_idx | 2 | 2 |
| sd->idle_idx | 0 | 1 |
| sd->newidle_idx | 0 | 0 |
| sd->wake_idx | 0 | 0 |
| sd->forkexec_idx | 0 | 0 |
| sd->span_weight | 4 | 8 |
| sd->balance_interval | 4 | 8 |
| sd->level | 0 | 1 |
| sd->flags | 0x832f: SD_LOAD_BALANCE|SD_BALANCE_NEWIDLE|SD_BALANCE_EXEC|SD_BALANCE_FORK|SD_WAKE_AFFINE|SD_SHARE_POWERDOMAIN|SD_SHARE_PKG_RESOURCES|SD_SHARE_CAP_STATES | 0x102f: SD_LOAD_BALANCE|SD_BALANCE_NEWIDLE|SD_BALANCE_EXEC|SD_BALANCE_FORK|SD_WAKE_AFFINE|SD_PREFER_SIBLING |
update_top_cache_domain()函数中还把常用的一些sd进行了cache,我们通过打印得出每个cache实际对应的层次sd:
| cache sd | 说明 | 赋值 |
| sd_busy | per_cpu(sd_busy, cpu), | 本cpu的tl DIE层级sd |
| sd_llc | per_cpu(sd_llc, cpu), | 本cpu的tl MC层级sd |
| sd_llc_size | per_cpu(sd_llc_size, cpu), | 4 |
| sd_llc_id | per_cpu(sd_llc_id, cpu), | 0/4 |
| sd_numa | per_cpu(sd_numa, cpu), | 0 |
| sd_asym | per_cpu(sd_asym, cpu), | 0 |
| sd_ea | per_cpu(sd_ea, cpu), | 本cpu的tl DIE层级sd |
| sd_scs | per_cpu(sd_scs, cpu), | 本cpu的tl MC层级sd |
1 | static void update_top_cache_domain(int cpu) |
1 | [update_top_cache_domain] cpu0, sd_busy=0xffffffc156091300, sd_llc=0xffffffc15663c600, sd_llc_size=4, sd_llc_id=0, sd_numa=0x0, sd_asym=0x0, sd_ea=0xffffffc156091300, sd_scs=0xffffffc15663c600 |
mt6799在计算功耗(energy)和运算能力(capacity)时使用的表项如下:
1 | kernel_init() -> kernel_init_freeable() -> sched_init_smp() -> init_sched_domains() -> build_sched_domains() -> init_sched_energy()/init_sched_groups_capacity(); |
4.1.2、smp负载均衡的实现
负载均衡和很多参数相关,下面列出了其中最重要的一些参数:
| 成员 | 所属结构 | 含义 | 更新/获取函数 | 计算方法 |
| rq->cpu_capacity_orig | rq | 本cpu总的计算能力 | init_sched_groups_capacity()/update_sd_lb_stats() -> update_group_capacity() -> update_cpu_capacity() | capacity = arch_scale_cpu_capacity(sd, cpu) |
| rq->cpu_capacity | rq | 本cpu cfs的计算能力 = 总capacity - rt占用的capacity | init_sched_groups_capacity()/update_sd_lb_stats() -> update_group_capacity() -> update_cpu_capacity() | capacity = scale_rt_capacity(cpu); |
| rq->rd->max_cpu_capacity | rq->rd | root_domain中最大的cpu计算能力 | init_sched_groups_capacity()/update_sd_lb_stats() -> update_group_capacity() -> update_cpu_capacity() | |
| rq->rd->overutilized | rq->rd | update_sd_lb_stats() | ||
| rq->rd->overload | rq->rd | update_sd_lb_stats() | ||
| rq->rt_avg | rq | 本cpu的rt平均负载 | weighted_cpuload() -> cfs_rq_runnable_load_avg() | |
| rq->cfs.runnable_load_avg | rq->cfs(cfs_rq) | 本cpu cfs_rq的runable平均负载 | __update_load_avg()、cfs_rq_load_avg() | (runnable时间freqweight)/LOAD_AVG_MAX |
| rq->cfs.avg.load_avg | rq->cfs.avg | 本cpu cfs_rq的runnable平均负载 | __update_load_avg() | (runnable时间freqweight)/LOAD_AVG_MAX |
| rq->cfs.avg.loadwop_avg | rq->cfs.avg | 本cpu cfs_rq的runnable平均负载,不含weight | __update_load_avg() | (runnable时间freq)/LOAD_AVG_MAX |
| rq->cfs.avg.util_avg | rq->cfs.avg | 本cpu cfs_rq的running负载 | update_load_avg()、cpu_util() -> cpu_util() | (running时间freqcapacity)/LOAD_AVG_MAX |
| cfs_rq->nr_running | cfs_rq | 本cfs_rq这个层次runnable的se的数量 | enqueue_entity()/dequeue_entity() -> account_entity_enqueue() | |
| cfs_rq->h_nr_running | cfs_rq | 本cfs_rq包含所有子cfs_rq nr_running的总和 | enqueue_task_fair()/dequeue_task_fair | |
| rq->nr_running | rq | 本cpu rq所有runnable的se的数量,包含所有子cfs_rq | enqueue_task_fair()/dequeue_task_fair -> add_nr_running() | |
4.1.2.1、rebalance_domains()
mtk对定义了3种power模式来兼容EAS的:EAS模式(energy_aware())、HMP模式(sched_feat(SCHED_HMP))、hybrid_support(EAS、HMP同时共存);
hybrid_support()模式下:一般负载均衡交给EAS;如果cpu_rq(cpu)->rd->overutilized负载已经严重不均衡,交给HMP;
系统在scheduler_tick()中会定期的检测smp负载均衡的时间是否已到,如果到时触发SCHED_SOFTIRQ软中断:
1 | void scheduler_tick(void) |
SCHED_SOFTIRQ软中断的执行主体为run_rebalance_domains:
1 | __init void init_sched_fair_class(void) |
我们分析最核心的函数rebalance_domains():
需要重点提一下的是:负载计算计算了3种负载(load_avg、loadwop_avg、util_avg),rebalance_domains主要使用其中的load_avg,乘(SCHED_CAPACITY_SCALE/capacity)加以转换。
- 1、逐级轮询本cpu的sd,判断本sd的时间间隔是否到期,如果到期做load_balance();
| tl层级 | cpu_busy? | sd->balance_interval | sd->busy_factor | sd balance interval |
|---|---|---|---|---|
MC层级 | idle | 4 |1 | 4ms
MC层级 | busy | 4 | 32 | 128ms
DIE层级 | idle | 8 |1 | 8ms
DIE层级 | busy | 8 | 32 | 256ms
| | | | | rq->next_balance = min(上述值)
2、在load_balance()中判断在本层级sd本cpu的当前情况是否适合充当dst_cpu,在should_we_balance()做各种判断,做dst_cpu的条件有:要么是本sg的第一个idle cpu,要么是本sg的第一个cpu。dst_cpu是作为目的cpu让负载高的cpu迁移进程过来,如果本cpu不符合条件中断操作;
3、继续find_busiest_group(),在sg链表中找出负载最重的sg。核心计算在update_sd_lb_stats()、update_sg_lb_stats()中。如果dst_cpu所在的local_group负载大于busiest sg,或者大于sds平均负载,中断操作;如果成功计算需要迁移的负载env->imbalance,为min((sds->avg - local), (busiest - sds->avg));
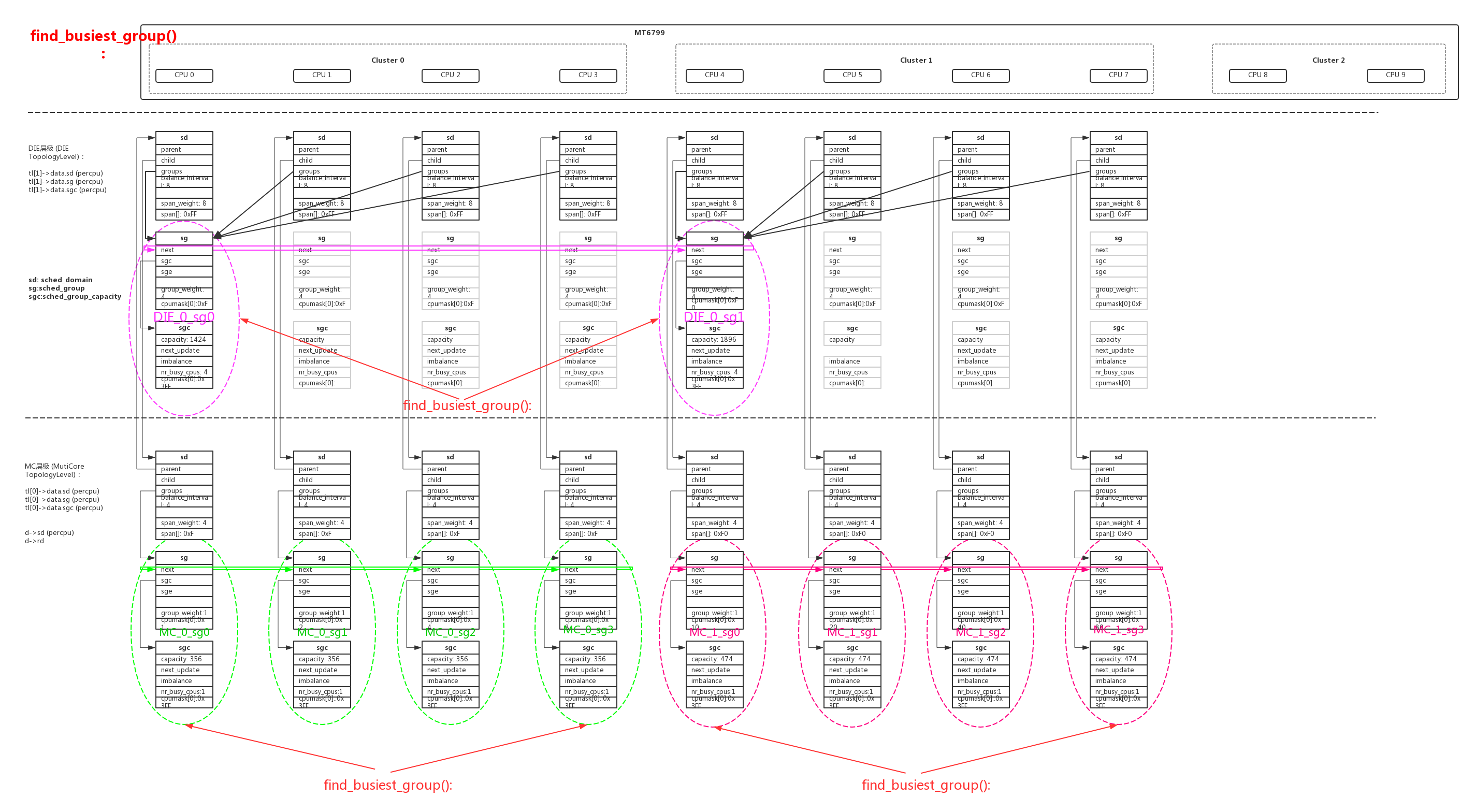
- 3.1、根据当前cpu的idle状态计算cpu load(rq->cpu_load[])时选用的index值:
| tl层级 | busy_idx | idle_idx | newidle_idx |
|---|---|---|---|
| MC层级 | 2 | 0 | 0 |
| DIE层级 | 2 | 1 | 0 |
- 3.2、计算sg负载sgs,选择sgs->avg_load最大的sg作为busiest_group。其中几个关键值的计算如下:
| 负载值 | 计算方法 | 说明 | |
|---|---|---|---|
| sgs->group_load | += cpu_rq(cpu)->cpu_load[index-1] | 累加cpu的load值,相对值(每个cpu的最大值都是1024),且带weight分量 | |
| sgs->group_util | += cpu_rq(cpu)->cfs.avg.util_avg | 累加cpu cfs running值,绝对值(不同cluster,只有最大capacity能力的cpu最大值为1024) | |
| sgs->group_capacity | += (arch_scale_cpu_capacity(sd, cpu)*(1-rt_capacity)) | 累加cpu的capacity,绝对值(不同cluster,只有最大capacity能力的cpu最大值为1024) | |
| sgs->avg_load | = (sgs->group_load*SCHED_CAPACITY_SCALE) / sgs->group_capacity | group_load做了转换,和group_capacity成反比 |
- 3.3、在计算sg负载时,几个关键状态的计算如下:
| 状态值 | 计算方法 | 说明 | |
|---|---|---|---|
| sgs->group_no_capacity | (sgs->group_capacity 100) < (sgs->group_util env->sd->imbalance_pct) | 预留一定空间(比例为imbalance_pct),sg运算能力已经不够了,sgs->group_type=group_overloaded | |
| dst_rq->rd->overutilized | (capacity_of(cpu) 1024) < (cpu_util(cpu) capacity_margin) | 预留一定空间(比例为capacity_margin),sg运算能力已经不够了 | |
| dst_rq->rd->overload | rq->nr_running > 1 | sg中任何一个cpu的runnable进程大于1 |
比例参数imbalance_pct、capacity_margin的值为:
| tl层级 | sd->imbalance_pct (/100) | capacity_margin (/1024) | |
|---|---|---|---|
| MC层级 | 117 | 1280 | |
| DIE层级 | 125 | 1280 |
- 3.4、计算env->imbalance,这个是rebalance需要迁移的负载量:
| 负载值 | 计算方法 | 说明 | |
|---|---|---|---|
| sds->total_load | += sgs->group_load | — | |
| sds->total_capacity | += sgs->group_capacity | — | |
| sds.avg_load | (SCHED_CAPACITY_SCALE * sds.total_load)/ sds.total_capacity | — | |
| env->imbalance | min((busiest->avg_load - sds->avg_load)busiest->group_capacity, (sds->avg_load - local->avg_load)local->group_capacity) / SCHED_CAPACITY_SCALE) | 感觉这里计算有bug啊,前面是1024/capcity,后面是capacity/1024,很混乱 |
- 4、继续find_busiest_queue(),查找busiest sg中负载最重的cpu。
- 4.1、找出sg中weighted_cpuload*capacity_of值最大的cpu:
| 负载值 | 计算方法 | 说明 | |
|---|---|---|---|
| weighted_cpuload(cpu) | cpu_rq(cpu)->cfs->runnable_load_avg | cpu的load值,相对值(每个cpu的最大值都是1024),且带weight分量 | |
| capacity_of(cpu) | arch_scale_cpu_capacity(sd, cpu)*(1-rt_capacity) | cpu cfs running值,绝对值(不同cluster,只有最大capacity能力的cpu最大值为1024) | |
| weighted_cpuload(cpu)*capacity_of(cpu) | — | 最大值为busiest sg中busiest cpu rq |
- 5、迁移busiest cpu的负载到本地dst cpu上,迁移的负载额度为env->imbalance:detach_tasks() -> attach_tasks();
- 6、处理几种因为进程亲和力问题,busiest cpu不能迁移走足够的进程:LBF_DST_PINNED尝试更改dst_cpu为本地cpu相同sg的其他cpu;LBF_SOME_PINNED当前不能均衡尝试让父sd均衡;LBF_ALL_PINNED一个进程都不能迁移尝试去掉dst_cpu重新进行load_balance();
- 7、如果经过各种尝试后还是没有一个进程迁移成功,最后尝试一次active_balance;
1 | /* |
4.1.2.2、nohz_idle_balance()
每个cpu的负载均衡是在本cpu的tick任务scheduler_tick()中判断执行的,如果cpu进入了nohz模式scheduler_tick()被stop,那么本cpu没有机会去做rebalance_domains()。为了解决这个问题,系统设计了nohz_idle_balance(),在运行的cpu上判断进入nohz的cpu是否需要rebalance load,如果需要选择一个idle cpu来帮所有的nohz idle cpu做负载均衡。
在rebalance_domains()函数之前有一个nohz_idle_balance(),这是系统在条件满足的情况下让一个idle cpu做idle负载均衡。主要的原理如下:
- 1、cpu在进入nohz idle状态时,设置标志:
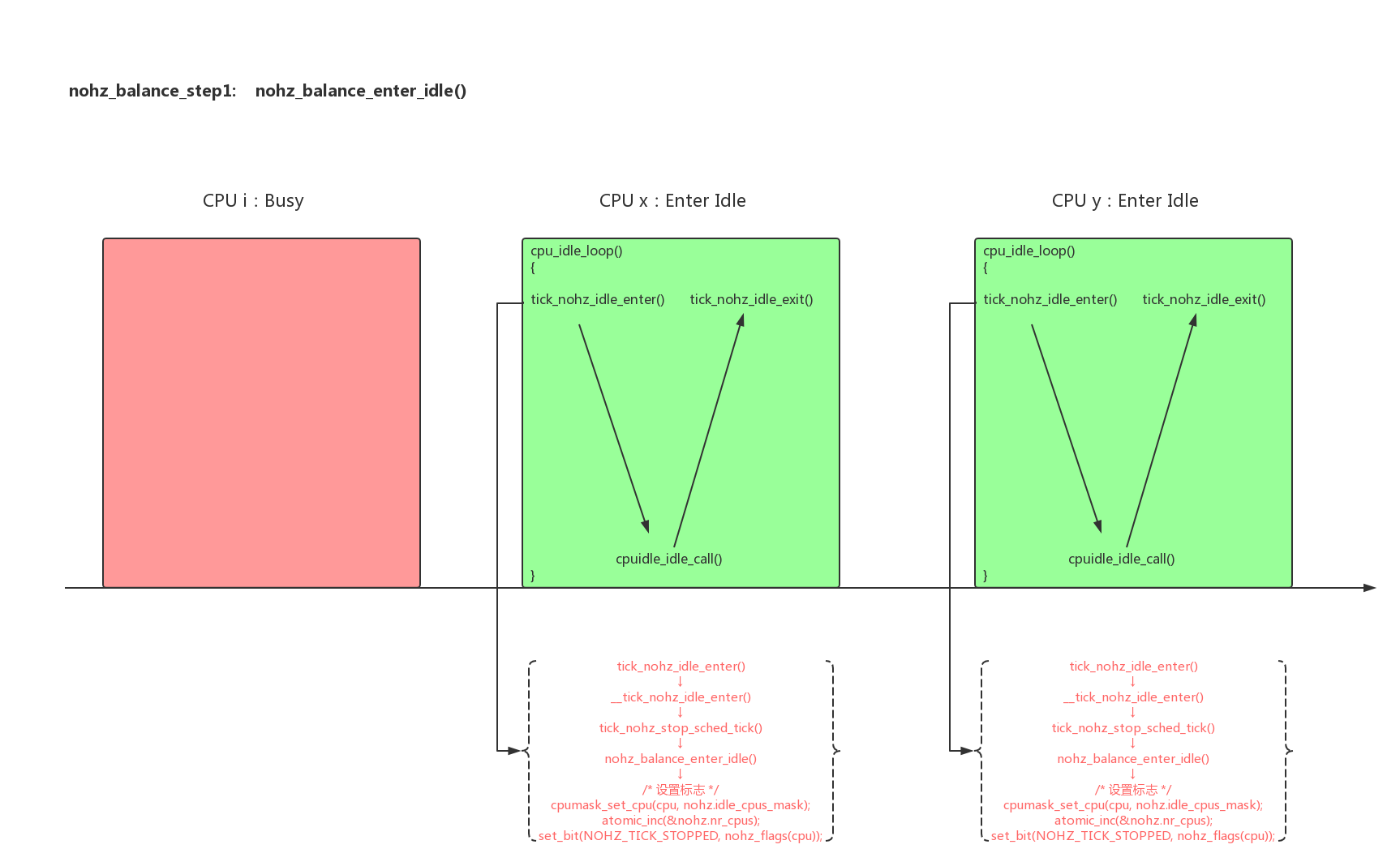
1 | tick_nohz_idle_enter() -> set_cpu_sd_state_idle(): |
- 2、在trigger_load_balance()中判断,当前是否需要触发idle load balance:
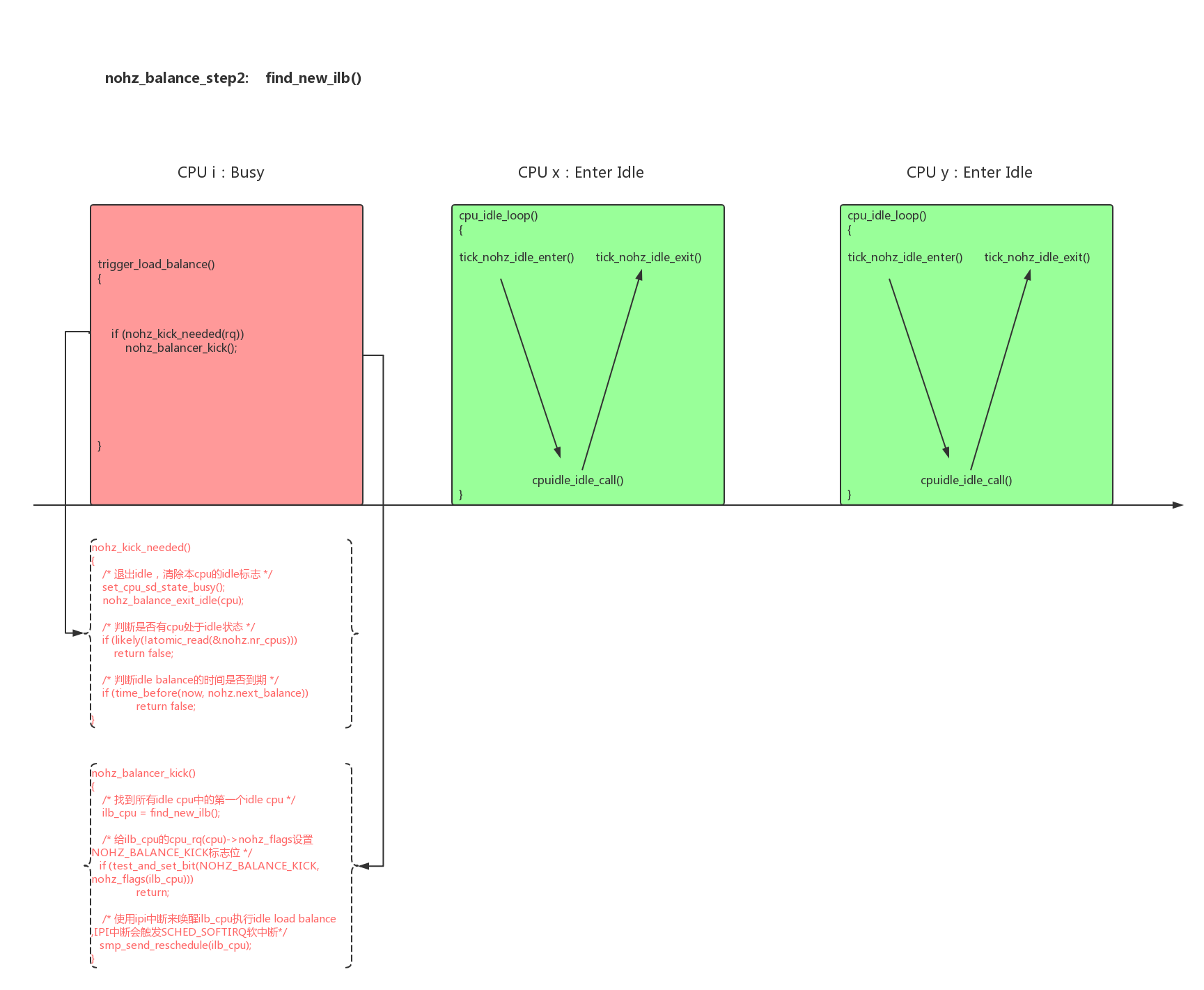
1 | void trigger_load_balance(struct rq *rq) |
- 3、被选中的ilb_cpu被唤醒后,需要帮其他所有idle cpu完成rebalance_domains()工作:
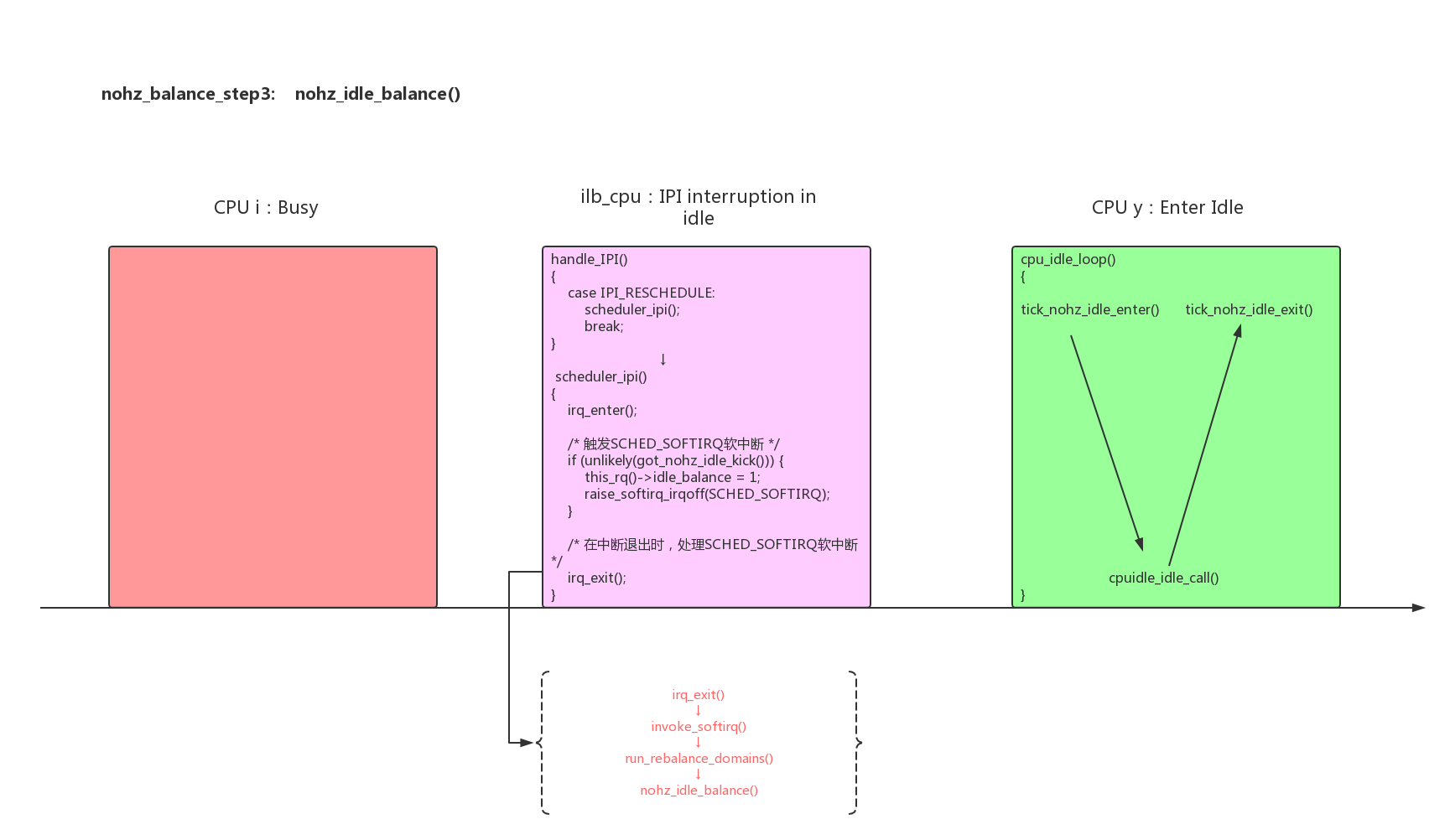
1 | static void nohz_idle_balance(struct rq *this_rq, enum cpu_idle_type idle) |
4.1.2.3、select_task_rq_fair()
除了scheduler_tick()的时候会做负载均衡,另外一个时刻也会做负载均衡。就是fork新进程、wakeup休眠进程时,系统会根据负载均衡挑选一个最合适的cpu给进程运行,其核心函数就是select_task_rq_fair():
- 1、首先是使用EAS的方法来select_cpu,在EAS使能且没有overutilized时使用EAS方法:
需要重点提一下的是:负载计算计算了3种负载(load_avg、loadwop_avg、util_avg),EAS主要使用其中的util_avg,和capacity一起计算。
- 1.1、EAS遍历cluster和cpu,找到一个既能满足进程p的affinity又能容纳下进程p的负载util,属于能用最小capacity满足的cluster其中剩余capacity最多的target_cpu;
首先找到能容纳进程p的util且capacity最小的cluster:
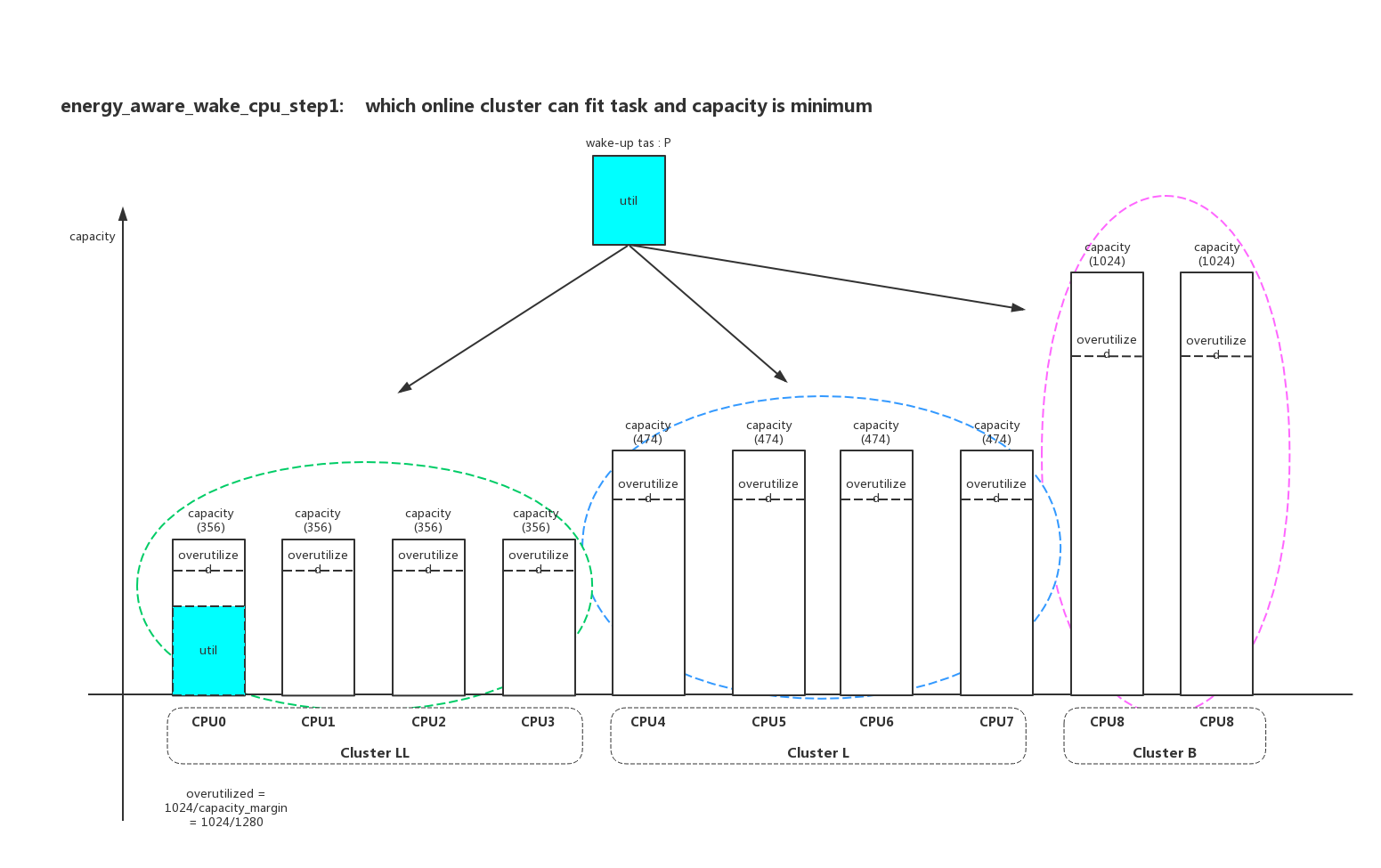
然后在目标cluster中找到加上进程p以后,剩余capacity最大的cpu:
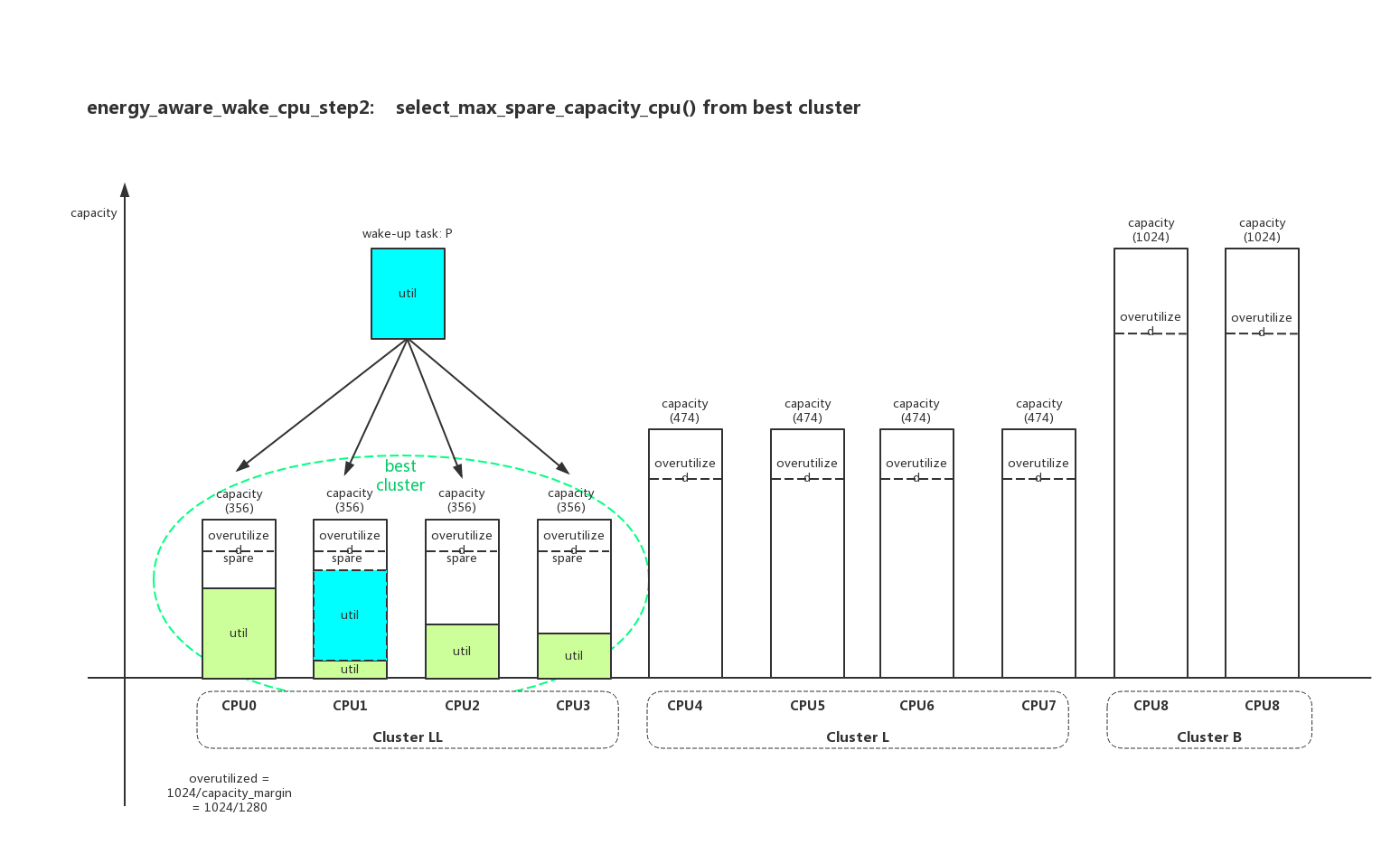
pre_cpu是进程p上一次运行的cpu作为src_cpu,上面选择的target_cpu作为dst_cpu,就是尝试计算进程p从pre_cpu迁移到target_cpu系统的功耗差异:
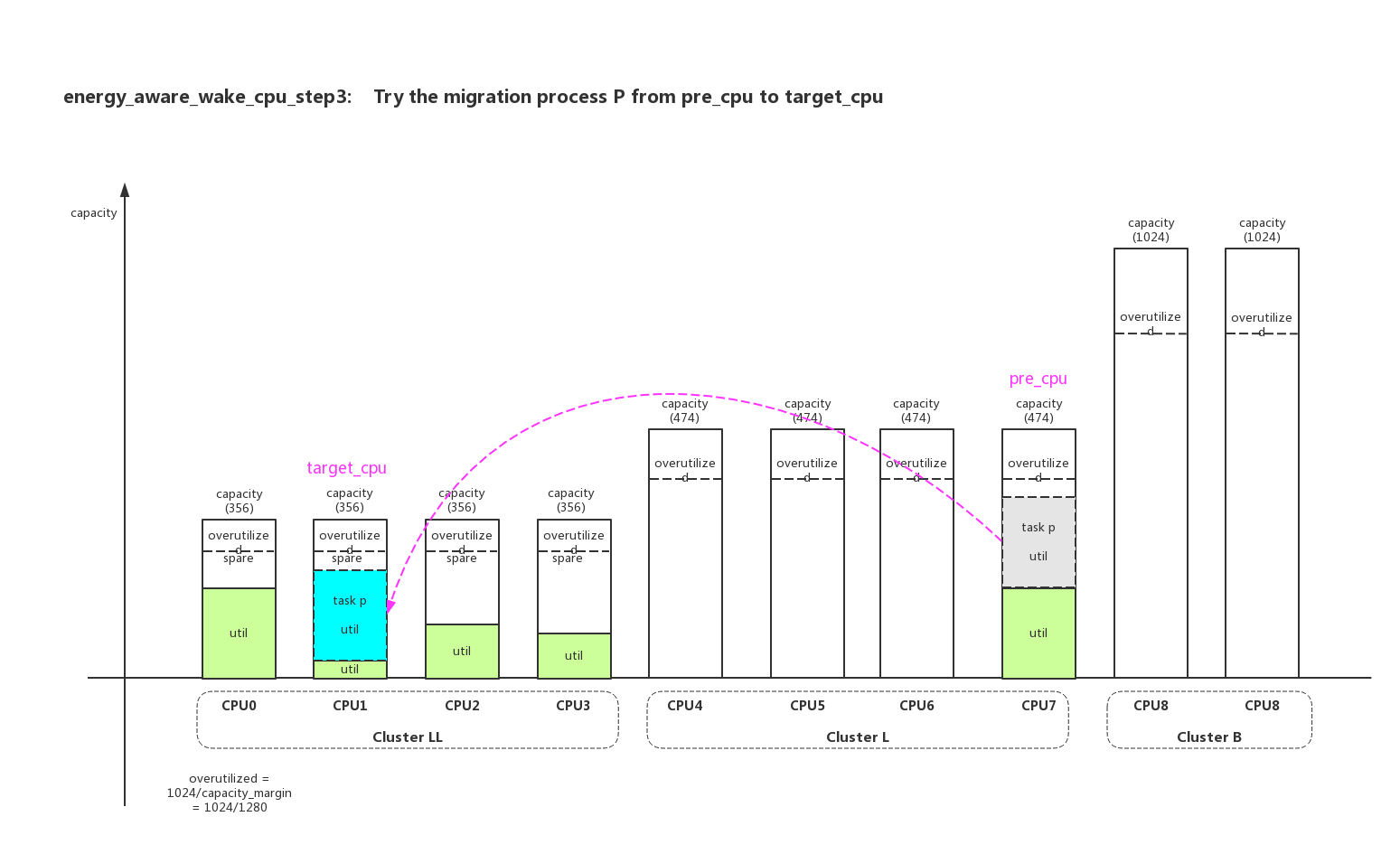
- 1.2、计算负载变化前后,target_cpu和prev_cpu带来的power变化。如果没有power增加则返回target_cpu,如果有power增加则返回prev_cpu;
计算负载变化的函数energy_diff()循环很多比较复杂,仔细分析下来就是计算target_cpu/prev_cpu在“MC层次cpu所在sg链表”+“DIE层级cpu所在sg”,这两种范围在负载变化中的功耗差异:
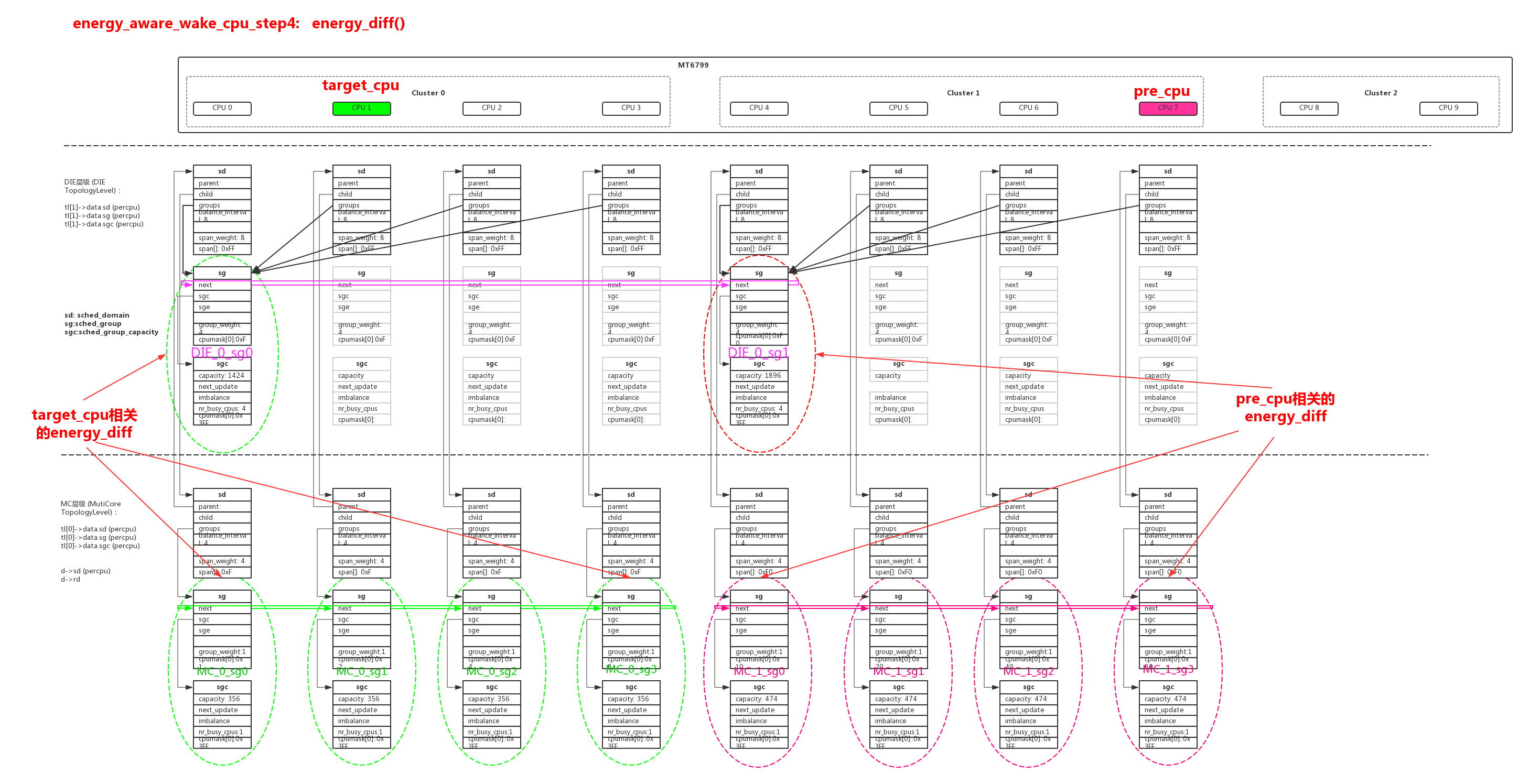
energy_diff()的计算方法如下:
| 负载值 | 计算方法 | 说明 | |
|---|---|---|---|
| idle_idx | min(rq->idle_state_idx) | sg多个cpu中,idle_state_idx最小值 | |
| eenv->cap_idx | find_new_capacity() | 在负载变化后,根据sg多个cpu中的最大util值,匹配的cpu freq档位sg->sge->cap_states[eenv->cap_idx].cap | |
| group_util | += (__cpu_util << SCHED_CAPACITY_SHIFT)/sg->sge->cap_states[eenv->cap_idx].cap | 累加sg中cpu的util值,并且把util转换成capacity的反比 | |
| sg_busy_energy | (group_util * sg->sge->busy_power(group_first_cpu(sg), eenv, (sd->child) ? 1 : 0)) >> SCHED_CAPACITY_SHIFT | 使用group_util计算busy部分消耗的功耗 | |
| sg_idle_energy | ((SCHED_LOAD_SCALE - group_util) * sg->sge->idle_power(idle_idx, group_first_cpu(sg), eenv, (sd->child) ? 1 : 0)) >> SCHED_CAPACITY_SHIFT | 使用(SCHED_LOAD_SCALE - group_util)计算idle部分计算的功耗 | |
| total_energy | sg_busy_energy + sg_idle_energy | 单个sg的功耗,累计所有相关sg的功耗,总的差异就是进程P迁移以后的功耗差异 |
- 2、如果EAS不适应,使用传统的负载均衡方法来select_cpu:
- 2.1、find_idlest_group() -> find_idlest_cpu() 找出最时候的target_cpu;
- 2.2、最差的方法使用select_idle_sibling()讲究找到一个idle cpu作为target_cpu;
- 2.3、确定target_cpu后,继续使用hmp_select_task_rq_fair()来判断是否需要进行hmp迁移;
1 | static int |
4.2、HMP负载均衡
除了SMP load_balance()负载均衡以外,我们还希望在多个SMP cluster之间能遵守一种规则:heavy任务跑在big core上,light任务跑在little core上,这样能快速的达到一个合理的负载状态。这种算法就叫做HMP负载均衡,EAS会统一的考虑负载、性能、功耗,EAS使能后HMP就被禁用了。
HMP负载均衡的操作分两种:
- 1、heavy task从little cpu迁移到big cpu。这种叫做up操作,对应的函数hmp_force_up_migration();
- 2、light task从big cpu迁移到little cpu。这种叫做down操作,对应的函数hmp_force_down_migration();
4.2.1、hmp domain初始化
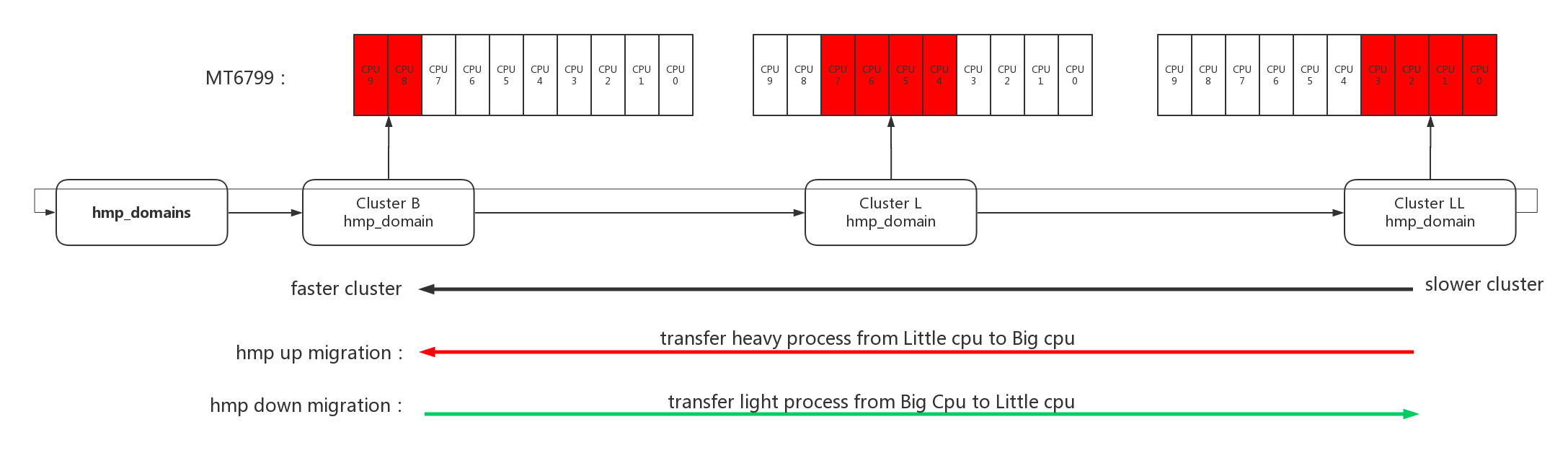
hmp在初始化的时候会每个cluster分配一个hmp_domain,把所有hmp_domain加入到全局链表hmp_domains中。hmp_domains链表构建完成以后,离链表头hmp_domains最近的hmp_domain是速度最快的cluster,离hmp_domains越远hmp_domain对应的速度越慢。因为在构造链表时是按照cluster id来加入的,速度最快cluster的hmp_domain最后加入,所以离表头最近。
1 | static int __init hmp_cpu_mask_setup(void) |
4.2.2、hmp_force_up_migration()
hmp_force_up_migration()的操作主要有以下几个步骤:
需要重点提一下的是:负载计算计算了3种负载(load_avg、loadwop_avg、util_avg),rebalance_domains主要使用其中的loadwop_avg。
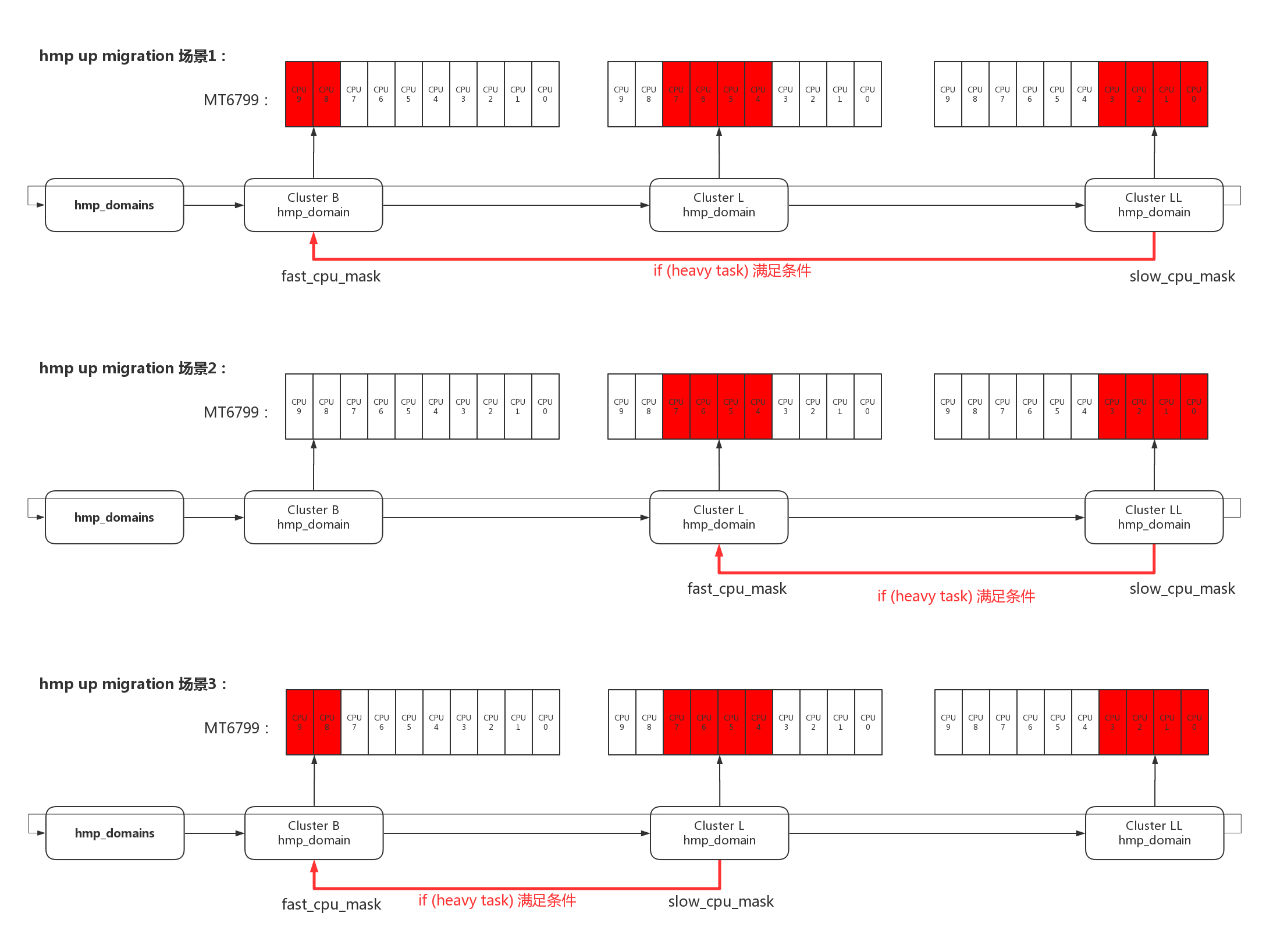
- 1、根据当前cpu,选择fast_cpu_mask、slow_cpu_mask;
hmp_force_up_migration尝试把slow cpu上的heavy进程迁移到fast cpu上,关于slow、fast的选择有以下几种场景:
2、选择当前cpu的heaviest进程作为迁移进程p;并不会遍历cpu上所有进程去选出heaviest进程,只会查询curr进程和cfs_rq中5个进程中的heaviest;
3、根据fast_cpu_mask,选择一个负载最少的target cpu;
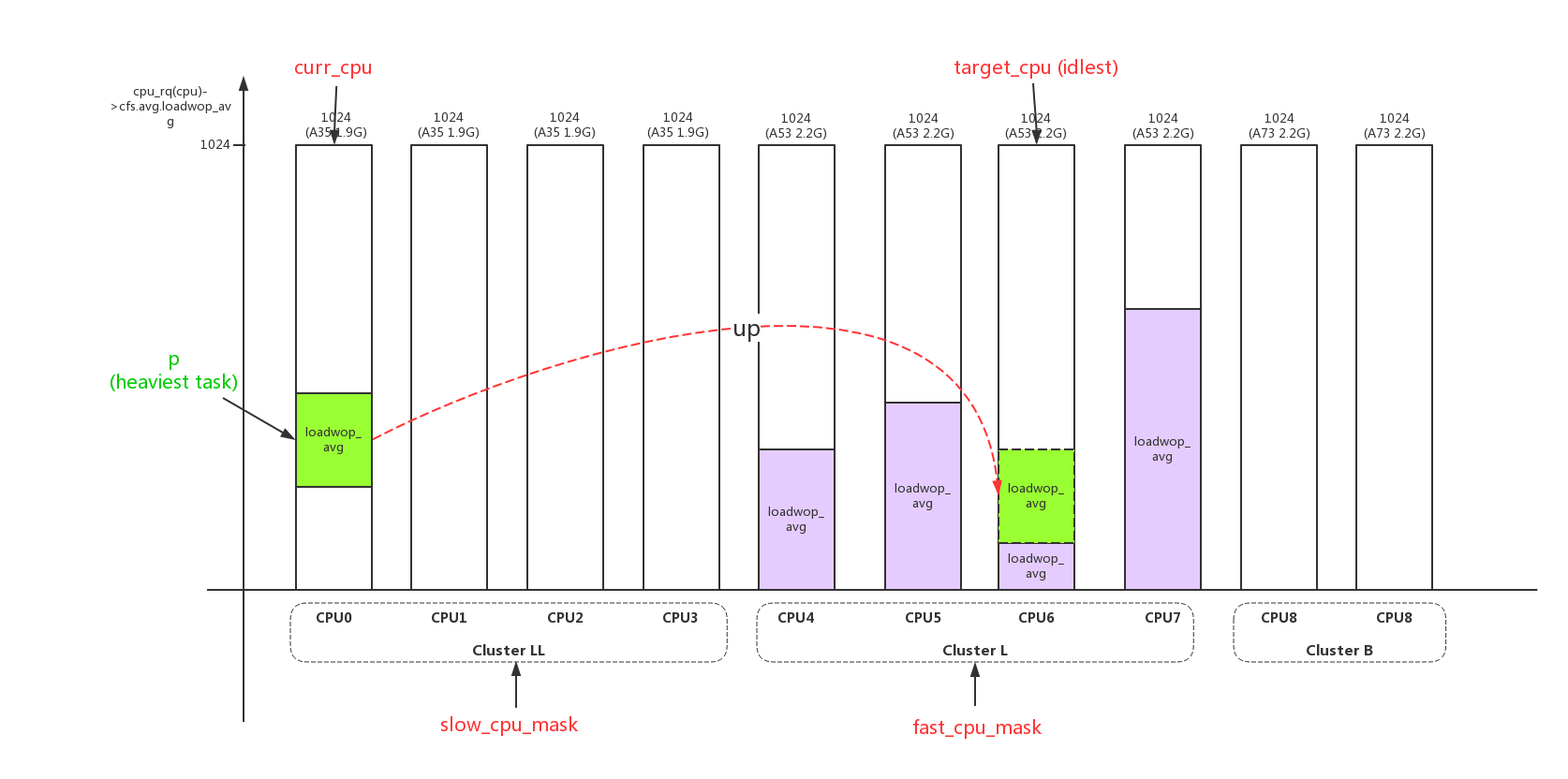
- 4、根据源cpu(curr_cpu)、目的cpu(target_cpu),计算负载;
重要的数据计算方法:
| 重要数据 | 所属结构 | 含义 | 更新/获取函数 | 计算方法 |
| clbenv->bstats.cpu_power | clbenv->bstats | B族cpu的绝对计算能力 | sched_update_clbstats() | arch_scale_cpu_capacity(NULL, clbenv->btarget) |
| clbenv->lstats.cpu_power | clbenv->lstats | L族cpu的绝对计算能力 | sched_update_clbstats() | arch_scale_cpu_capacity(NULL, clbenv->ltarget) |
| clbenv->lstats.cpu_capacity | clbenv->lstats | B族cpu的相对计算能力,大于1024 | sched_update_clbstats() | SCHED_CAPACITY_SCALE clbenv->bstats.cpu_power / (clbenv->lstats.cpu_power+1) |
| clbenv->bstats.cpu_capacity | clbenv->bstats | L族cpu的相对计算能力,等于1024 | sched_update_clbstats() | SCHED_CAPACITY_SCALE |
| clbs->ncpu | clbenv->bstats/clbenv->lstats | L族/B族online的cpu数量 | collect_cluster_stats() | if (cpu_online(cpu)) clbs->ncpu++; |
| clbs->ntask | clbenv->bstats/clbenv->lstats | L族/B族所有online cpu中所有层级se的总和 | collect_cluster_stats() | clbs->ntask += cpu_rq(cpu)->cfs.h_nr_running; |
| clbs->load_avg | clbenv->bstats/clbenv->lstats | L族/B族online cpu的平均runnable负载,不带weight | collect_cluster_stats() | sum(cpu_rq(cpu)->cfs.avg.loadwop_avg)/clbs->ncpu |
| clbs->scaled_acap | clbenv->bstats/clbenv->lstats | L族/B族target cpu计算能力的剩余值 | collect_cluster_stats() | hmp_scale_down(clbs->cpu_capacity - cpu_rq(target)->cfs.avg.loadwop_avg) |
| clbs->scaled_atask | clbenv->bstats/clbenv->lstats | L族/B族target cpu的task space的剩余值 | collect_cluster_stats() | hmp_scale_down(clbs->cpu_capacity - cpu_rq(target)->cfs.h_nr_running cpu_rq(target)->cfs.avg.loadwop_avg) |
| clbenv->bstats.threshold | clbenv->bstats | 进程要up迁移到B族的负载门限值 | adj_threshold() | HMP_MAX_LOAD - HMP_MAX_LOAD b_nacap b_natask / ((b_nacap + l_nacap) (b_natask + l_natask) + 1);b_nacap、b_natask会乘以一个放大系数(b_cpu_power/l_cpu_power),类似如cpu_capacity的计算 |
| clbenv->lstats.threshold | clbenv->lstats | 进程要down迁移到L族的负载门限值 | adj_threshold() | HMP_MAX_LOAD l_nacap l_natask / ((b_nacap + l_nacap) (b_natask + l_natask) + 1);b_nacap、b_natask会乘以一个放大系数(b_cpu_power/l_cpu_power),类似如cpu_capacity的计算 |
- 5、根据计算的负载情况,判断进程p是否符合up迁移条件((se_load(se) > B->threshold),等其他条件);
up-migration条件列表(hmp_up_migration()):
| 条件 | 含义 | 计算方法 | 计算解析 |
| [1] Migration stabilizing | 如果target cpu刚做过up迁移,不适合再进行迁移 | if (!hmp_up_stable(target_cpu)) check->result = 0; | (((now - hmp_last_up_migration(cpu)) >> 10) < hmp_next_up_threshold) //间隔时间小于hmp_next_up_threshold |
| [2] Filter low-priority task | 低优先级进程(nice>5)如果负载不够,不能进行up迁移 | if (hmp_low_prio_task_up_rejected(p, B, L)) check->result = 0; | (task_low_priority(p->prio) && (B->ntask >= B->ncpu || 0 != L->nr_normal_prio_task) && (p->se.avg.loadwop_avg < 800)) // (如果是低优先级(nice>5)进程) && (B组进程大于cpu数 || L正常优先级的进程不为0) && (进程负载<800);满足上述条件不进行up迁移 |
| [2.5]if big is idle, just go to big | 如果目标B cpu处于idle状态,不需要判断其他条件,直接满足up迁移 | if (rq_length(target_cpu) == 0) check->result = 1; | (cpu_rq(cpu)->nr_running + cfs_nr_pending(cpu)) == 0 // |
| [3] Check CPU capacity | 判断目标B cpu的capacity是否足够容纳迁移过去的进程se | if (!hmp_task_fast_cpu_afford(B, se, *target_cpu)) check->result = 0; | (se_load(se) + cfs_load(target_cpu)) < (B->cpu_capacity - (B->cpu_capacity >> 2)) // se + target_cpu的负载,需要小于3/4 cpu_capacity |
| [4] Check dynamic migration threshold | 如果进程的负载达到up迁移的门限值,则满足up迁移 | if (se_load(se) > B->threshold) check->result = 1; |
- 6、如果条件符合,进行实际的up迁移;
hmp_force_up_migration()详细的代码解析:
1 | static void run_rebalance_domains(struct softirq_action *h) |
4.2.3、hmp_force_down_migration()
hmp_force_down_migration()的操作主要有以下几个步骤:
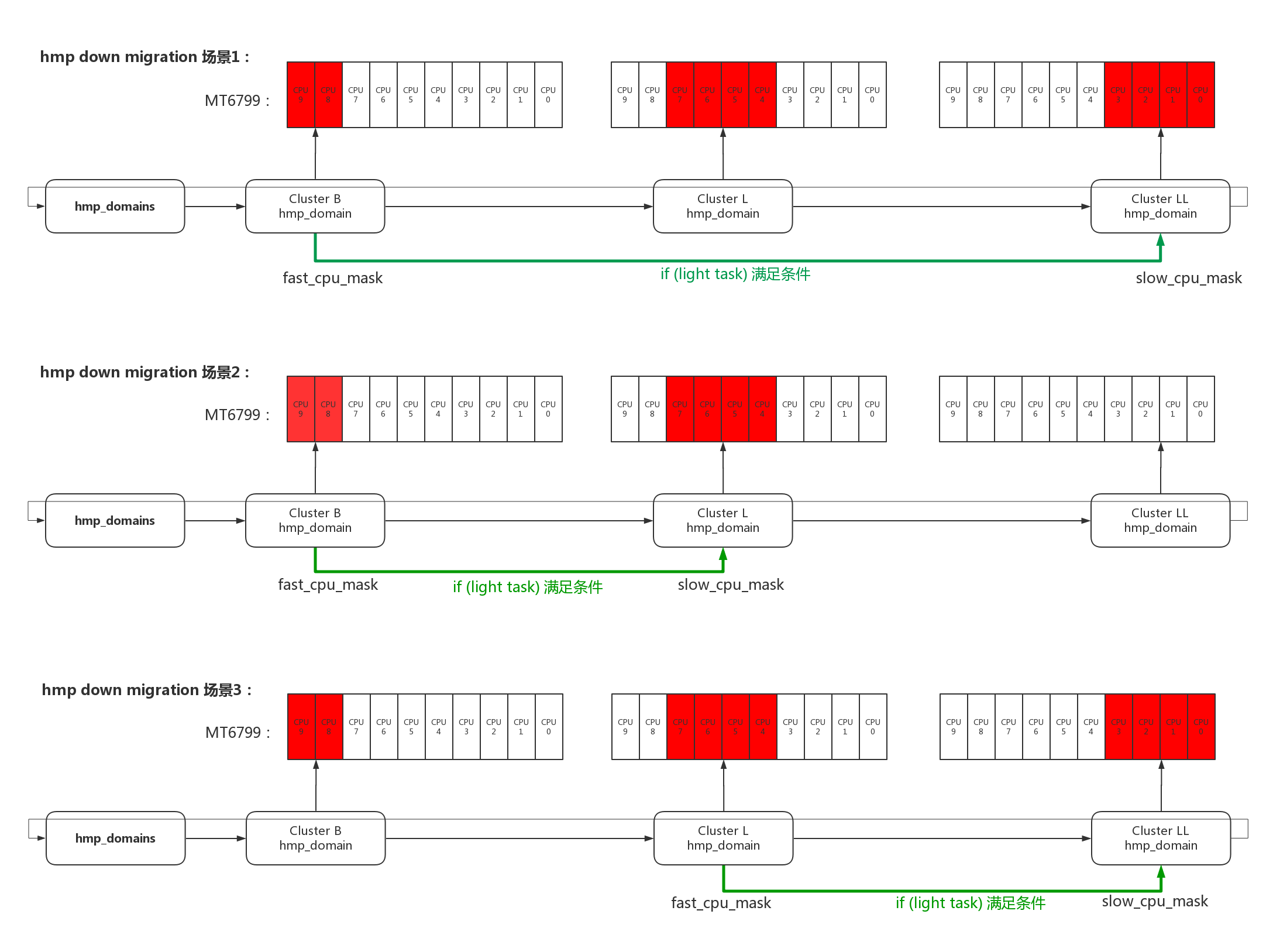
- 1、根据当前cpu,选择fast_cpu_mask、slow_cpu_mask;
hmp_force_down_migration尝试把fast cpu上的light进程迁移到slow cpu上,关于fast、slow的选择有以下几种场景:
2、选择当前cpu的lightest进程作为迁移进程p;并不会遍历cpu上所有进程去选出lightest进程,只会查询curr进程和cfs_rq中5个进程中的lightest;
3、根据slow_cpu_mask,选择一个负载最少的target cpu;
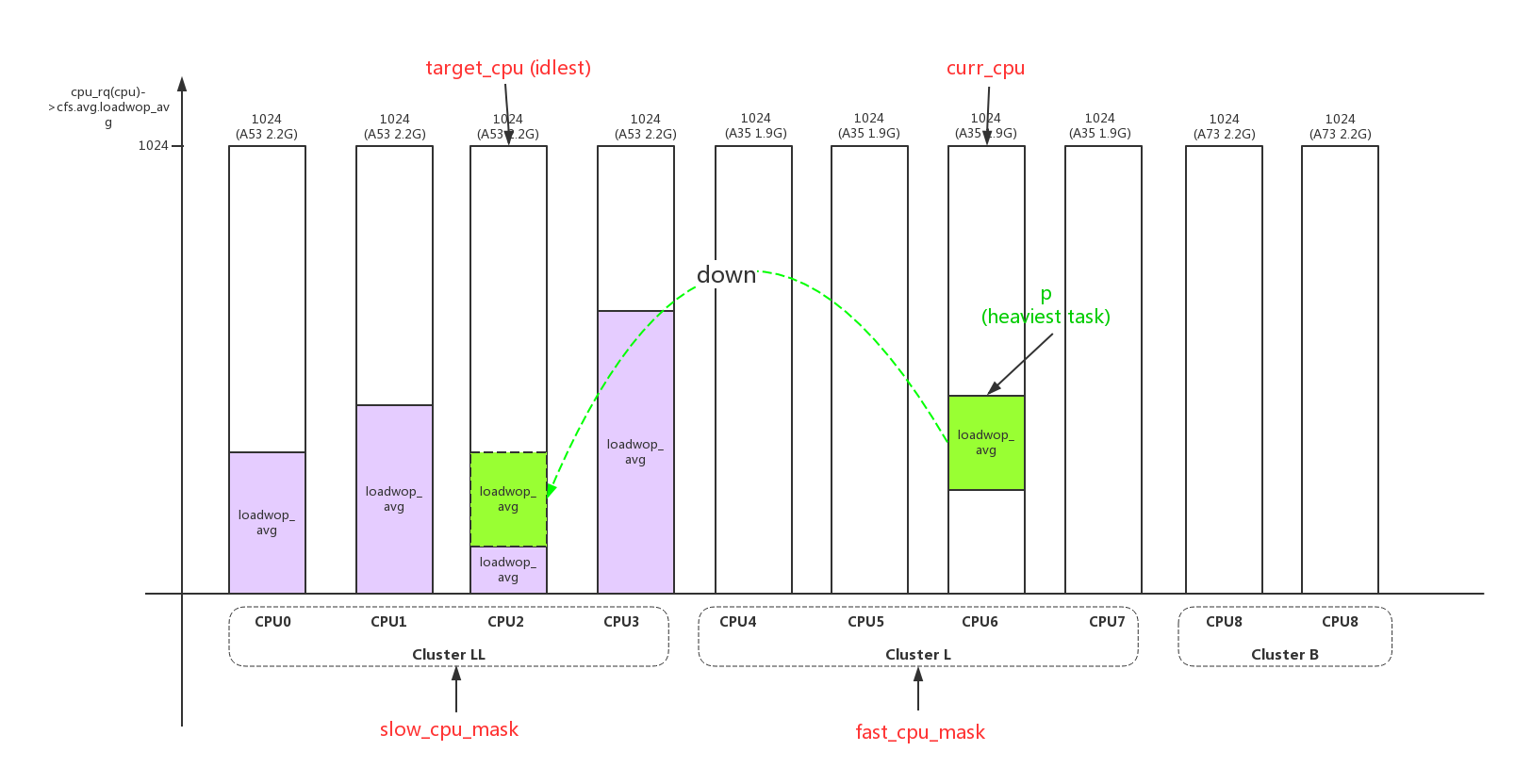
- 4、根据源cpu(curr_cpu)、目的cpu(target_cpu),计算负载;
重要的数据计算方法和hmp_force_up_migration()一致,参考上一节;
- 5、根据计算的负载情况,判断进程p是否符合down迁移条件((L->threshold >= se_load(se)),等其他条件);
down-migration条件列表(hmp_down_migration()):
| 条件 | 含义 | 计算方法 | 计算解析 |
| [1] Migration stabilizing | 如果target cpu刚做过down迁移,不适合再进行迁移 | if (!hmp_down_stable(target_cpu)) check->result = 0; | (((now - hmp_last_down_migration(cpu)) >> 10) < hmp_next_down_threshold) //间隔时间小于hmp_next_down_threshold |
| [1.5]if big is busy and little is idle, just go to little | 如果big cpu busy && little cpu idle,则不用进行其他判断,直接满足up迁移 | if ((rq_length(target_cpu) == 0 && caller == HMP_SELECT_RQ && rq_length(curr_cpu) > 0) && (!(!is_heavy_task(curr_rq->curr) && is_heavy_task(p)))) check->result = 1; | caller == HMP_SELECT_RQ // 只有select rq操作时有效; is_heavy_task() // p->se.avg.loadwop_avg >= 650 |
| [2] Filter low-priority task | 低优先级进程(nice>5)如果满足以下条件,准许迁移 | if (hmp_low_prio_task_down_allowed(p, B, L)) check->result = 1; | (task_low_priority(p->prio) && !B->nr_dequeuing_low_prio && B->ntask >= B->ncpu && 0 != L->nr_normal_prio_task && (p->se.avg.loadwop_avg < 800)) // (nice值大于5) && (B和L都不是特别空闲) && (进程负载<800) |
| [3] Check CPU capacity,1) big cpu is not oversubscribed | 如果big cpu有足够的空闲周期,不需要强制把big cpu的light任务迁移到little cpu上 | if (!hmp_fast_cpu_oversubscribed(caller, B, se, curr_cpu)) check->result = 0; | cfs_load(curr_cpu) < (B->cpu_capacity - (B->cpu_capacity >> 2)) // 当前cpu负载小于3/4 cpu_capacity |
| [3] Check CPU capacity,2) LITTLE cpu doesn’t have available capacity for this new task | 判断L族cpu的剩余capacity是否足够容纳需要迁移的进程 | if (!hmp_task_slow_cpu_afford(L, se)) check->result = 0; | (L->acap > 0 && L->acap >= se_load(se)) // L族cpu的剩余能力大于se的负载,才能继续判断 |
| [4] Check dynamic migration threshold | 如果进程的负载低于down迁移的门限值,则满足down迁移 | if (L->threshold >= se_load(se)) check->result = 1; |
- 6、如果条件符合,进行实际的down迁移;
hmp_force_down_migration()详细的代码解析:
1 | static void hmp_force_down_migration(int this_cpu) |
4.2.4、hmp_select_task_rq_fair()
4.3、cpu freq调整
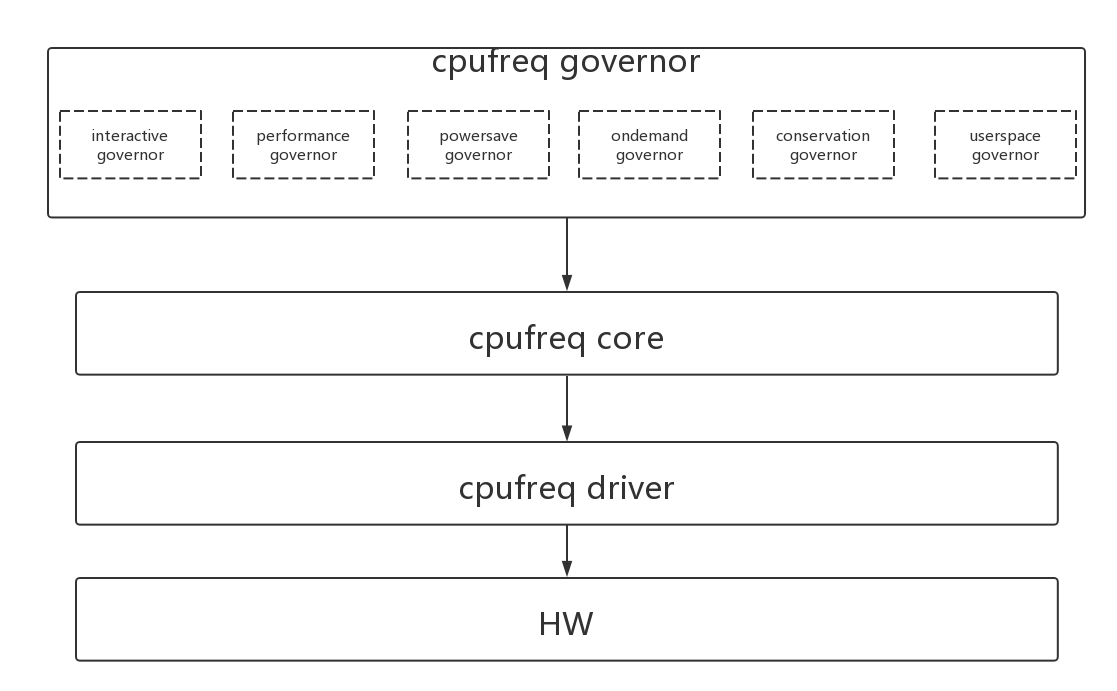
前面讲的负载均衡的手段都是负载迁移,把负载迁移到最idle或者最省power的cpu上。另外一种方式就是调整cpu的freq,从而改变cpu的curr_capacity,来满足性能和功耗的需求。
cpu的频率调整是基于3个层次的:cpufreq governor、cpufreq core、cpufreq driver。
- 1、cpufreq governor决定cpu调频的算法,计算负载、根据负载的变化来动态调整频率;
- 2、cpufreq core对通用层进行了一些封装,比如cpufreq_policy的封装;
- 3、cpufreq driver是底层操作的实现,比如freq_table的初始化、cpu target频率的配置;
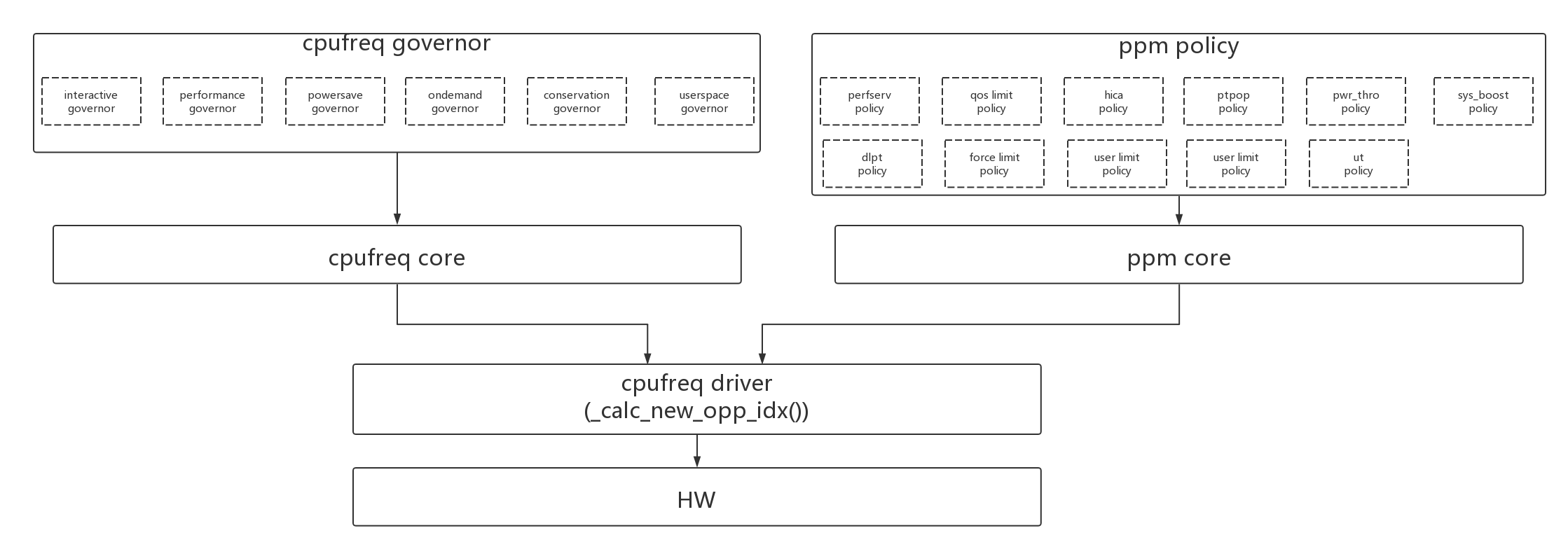
如果是MTK平台,cpufreq driver除了接受governor的频率调整还需要接受ppm的频率调整,它的框图大概如下:
4.3.1、cpufreq core & cpufreq driver
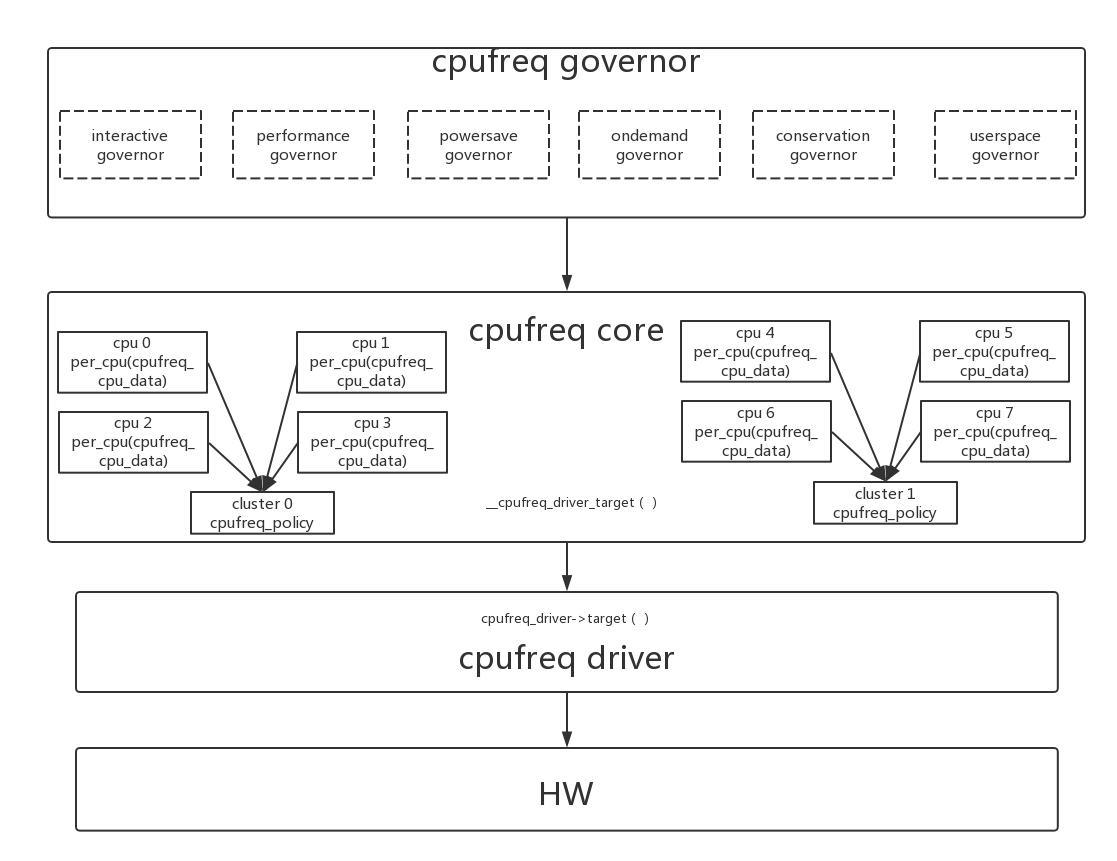
cpufreq core层次最核心的就是每个cpu有一个自己的cpufreq_policy policy,放在per_cpu(cpufreq_cpu_data, cpu)变量中。实际上cpufreq_policy是一个cluster对应一个的,因为在现有的架构中,同一个cluster cpu都是同一个频率,所以同cluster中所有cpu的per_cpu(cpufreq_cpu_data, cpu)都指向同一个cpufreq_policy。
4.3.1.1、cpufreq_policy policy初始化
1 | struct cpufreq_policy { |
在系统初始化化的时候初始化online cpu的cpufreq_policy,cpu在hotplug online的时候也会重新初始化cpufreq_policy。
- 1、在mtk的cpufreq_driver驱动初始化函数_mt_cpufreq_pdrv_probe()中注册了_mt_cpufreq_driver:
1 | static int _mt_cpufreq_pdrv_probe(struct platform_device *pdev) |
- 2、在驱动注册cpufreq_register_driver()过程中会初始化online cpu的cpufreq_policy:
1 | _mt_cpufreq_pdrv_probe() -> cpufreq_register_driver() -> subsys_interface_register() -> cpufreq_add_dev() -> cpufreq_online() |
- 3、在cpufreq_online()初始化完cpufreq_policy,最后会调用cpufreq_init_policy()继续governor的初始化:
1 | static int cpufreq_init_policy(struct cpufreq_policy *policy) |
- 4、以interactive governor为例,说明policy->governor->governor()对CPUFREQ_GOV_POLICY_INIT、CPUFREQ_GOV_START、CPUFREQ_GOV_STOP、CPUFREQ_GOV_POLICY_EXIT这几个命令的实现:
1 | struct cpufreq_governor cpufreq_gov_interactive = { |
4.3.1.2、cpufrep的频率配置
cpufreq一个重要的作用就是能把用户需要的cpu频率配置下去,这部分的代码也需要cpufreq core和cpufreq driver的配合。频率调整也叫DVFS(Dynamic Voltage and Frequency Scaling),需要按照对应关系把电压和频率一起配置下去。
具体的代码解析如下:
1 | int __cpufreq_driver_target(struct cpufreq_policy *policy, |
4.3.2、interactive governor
在所有的cpufreq governor中最有名气的就是interactive governor了,因为几乎所有的andriod系统中都在使用。
interactive的思想就是使用cpu的负载来调整cpu频率,核心就是:使用一个20ms的定时器来计算cpu占用率,根据cpu占用率的不同threshold来调整不同档位的频率。
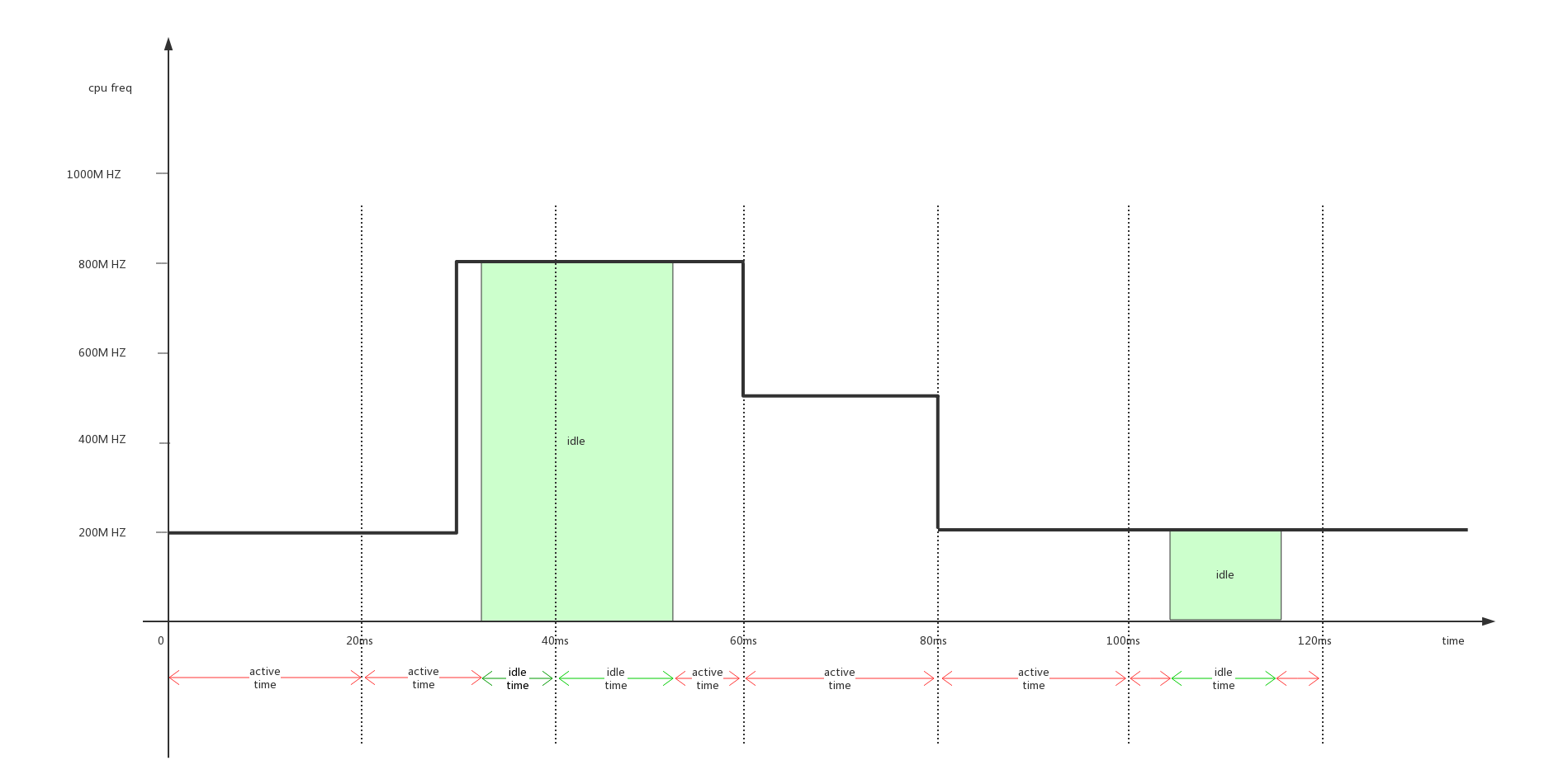
interactive的负载计算方法如上图所示。interactive的整个计算方法大概如下:
- 1、计算cpu的累加负载。每20ms采样一次,每次采样统计增加的active_time和当前频率的乘积:cputime_speedadj += active_time * cur_freq;
- 2、计算cpu的占用率。当前cpu占用率 = (累加负载100)/(累加时间当前频率),cpu_load = (loadadjfreq100)/(delta_timecur_freq);
- 3、如果cpu_load达到高门限go_hispeed_load(99%)或者发生boost,直接调节频率到hispeed_freq(最高频率);
- 4、其他情况下使用choose_freq()公式计算新频率:new_freq = cur_freq*(cpu_load/DEFAULT_TARGET_LOAD(90));new_freq = cpufreq_frequency_table_target(new_freq, CPUFREQ_RELATION_L);
- 5、如果当前频率已经达到hispeed_freq,还需要往上调整,必须在之前的频率上保持above_hispeed_delay(20ms);如果当前频率已经达到hispeed_freq,还需要往下调整,必须在之前的频率上保持min_sample_time(80ms);
interactive governor从原理上看,有以下问题:
- 1、20ms的采样时间过长,负载变化到频率调整的反应时间过长;
- 2、负载累加计算有问题,历史负载没有老化机制,历史负载的权重和当前一样,造成当前的负载变化不真实;
- 3、计算cpu占用率=总历史负载/(总时间*当前频率),算法不合理历史负载对当前影响太大。如果之前是高频率,现在变成低频率,那么cpu_load计算出来的值可能超过100%;如果之前是低频率,现在是高频率,那么cpu_load计算出来的值也会大大被拉低;
- 4、choose_freq()的计算公式有重大漏洞。比如我们cpu频率表={800M, 900M},当前cur_freq=800m cur_load=100%,那么newfreq = (cur_freq*cur_load)/90 = 889M,使用CPUFREQ_RELATION_L选择档位,选择到还是800M根本不能向高档位前进。这是算法的一个漏洞,如果cpu不同档位的频率差值大于(100/90),那么正常往上调频是调不上去的,会被CPUFREQ_RELATION_L参数拦下来。所以实际的interactive调频,都是使用go_hispeed_load(99%)调到最高值的,再使用choose_freq()来降频。
所以interactive governor会逐渐的被cpufreq gorernor所取代。
4.3.2.1、interactive governor的初始化
- 1、interactive的一部分初始化在cpufreq_interactive_init()当中:
1 | static int __init cpufreq_interactive_init(void) |
- 2、interactive另一部分初始化在cpufreq_governor_interactive()中的CPUFREQ_GOV_POLICY_INIT、CPUFREQ_GOV_START命令,在cpu online时执行:
1 |
|
4.3.2.2、interactive governor的算法
interactive governor的核心算法在20ms周期的timer interactive governor()中:
1 | static void cpufreq_interactive_timer(unsigned long data) |
4.4、cpu hotplug调整
还有一种调节负载的方式是cpu hotplug:
- 1、cpu被hotplug掉的功耗小于cpu进入idle的功耗;如果整个cluster的cpu都offline,cluster也可以poweroff;所以hotplug能够节省功耗;
- 2、但是hotplug是有开销的:hotplug动作在速度慢的时候达到了ms级别,另外进程的迁移也是有开销的;cpu的hotplug必须遵循顺序插拔的规则,如果先拔掉负载重的cpu也是不合理的;
- 3、MTK的技术限制必须使用hotplug:MTK平台只有在剩一个online cpu的情况下才能进入深度idle模式,所以MTK平台必须支持hotplug;而samsung、qualcomm在多核online的情况下可以进入深度idle,所以一般不支持cpu hotplug;
4.4.1、hotplug 底层实现
4.4.1.1、cpu_cup()/cpu_down()
kernel对hotplug的支持是很完善的,标准接口cpu_up()/cpu_down()可以进行hotplug。
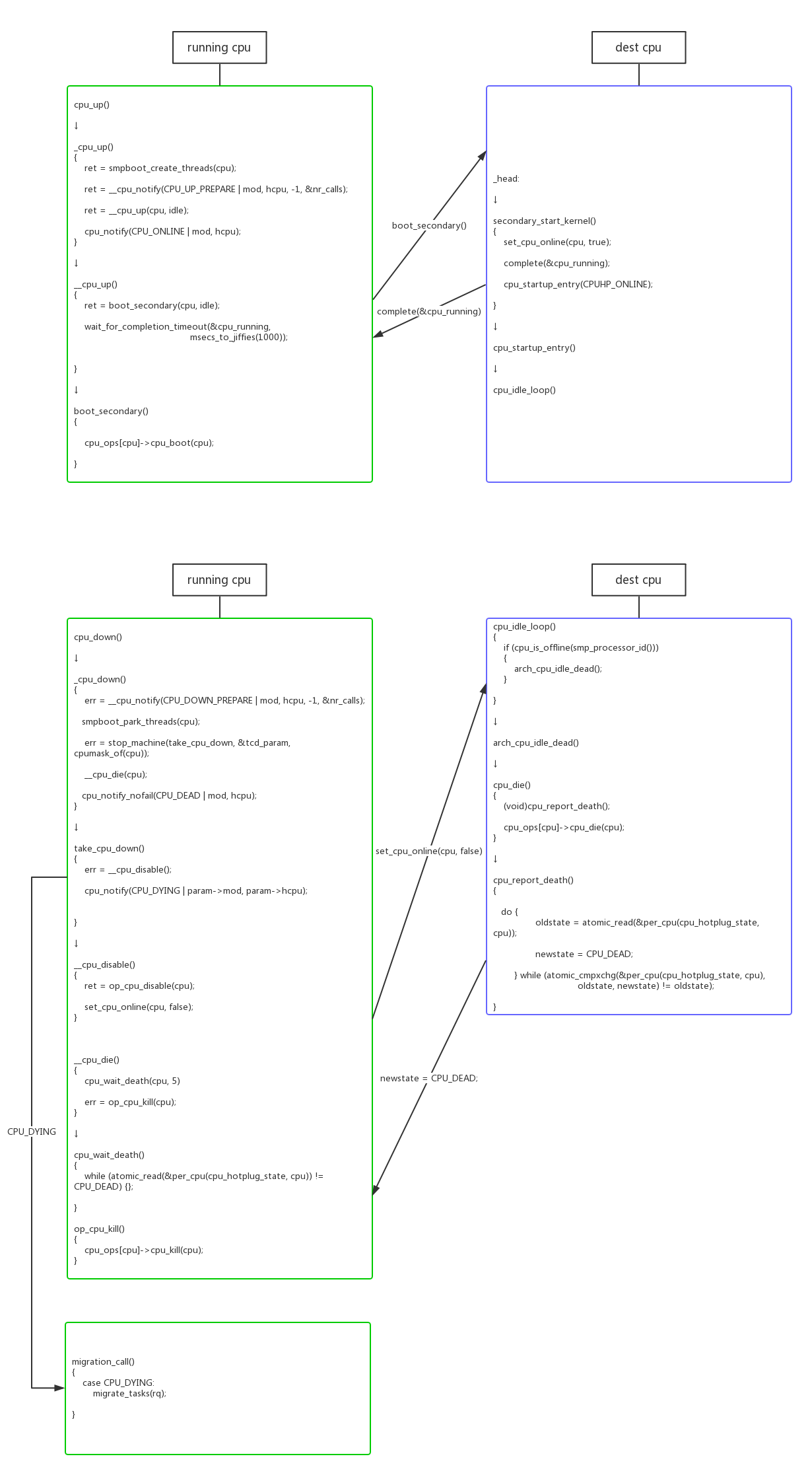
4.4.1.2、hotplug 进程迁移
在cpu_down()时,需要调用migration_call() -> migrate_tasks()把cpu上所有runnable进程迁移到其他cpu;在cpu_up()时,并不需要在函数中迁移进程,直接等待负载均衡算法的迁移。
1 | static void migrate_tasks(struct rq *dead_rq) |
4.4.2、MTK hotplug算法
在有了hotplug的底层cpu_cup()、cpu_down()的实现以后,在此之上还需要有一套算法根据cpu的负载来动态hotplug。MTK这套算法比较齐全,主要分为HICA、hps_algo_main两部分。
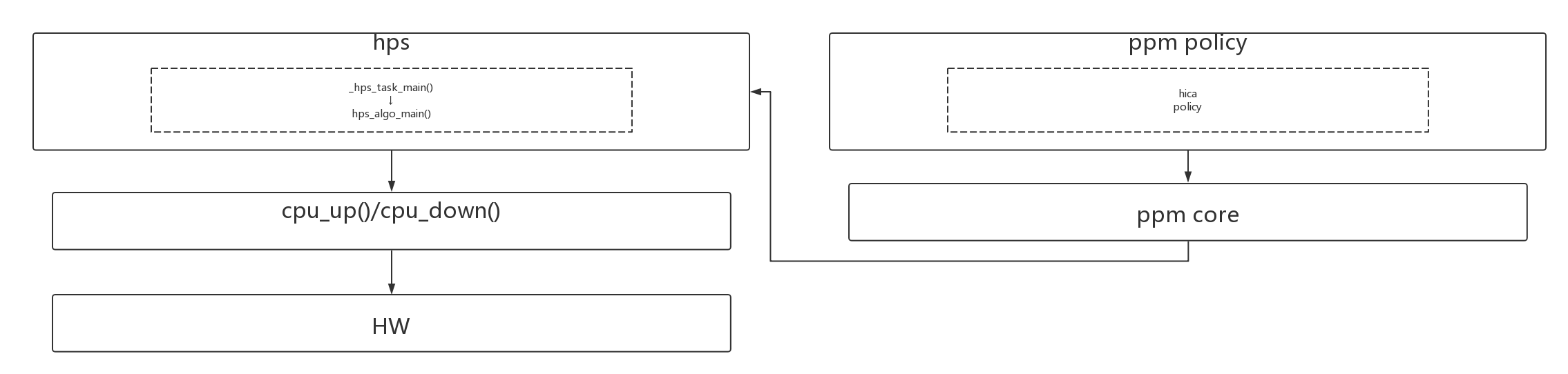
4.4.2.1、HICA/PPM
HICA和hps的关系,其实是HICA决定了一种大的mode,而hps在大的mode中实现精细化的调整。
比如对MT6799 HICA支持3种模式:
- 1、LL_ONLY。 // 只开小核
- 2、L_ONLY。 // 只开中核
- 3、ALL。 // LL、L、B10核都可以使用
HICA在mt_ppm_hica_update_algo_data()中计算负载,根据负载变化来决定mode:
1 | _hps_task_main() -> mt_ppm_hica_update_algo_data() |
关于计算state的函数和阈值定义在表中,除了heavy_task和big_task,基本是计算util/capacity的cpu占用情况:
1 | struct ppm_power_state_data pwr_state_info_SB[NR_PPM_POWER_STATE] = { |
新的state计算完成后,是通过以下通道配置下去的:
1 | _hps_task_main() -> mt_ppm_main() -> ppm_hica_update_limit_cb() -> ppm_hica_set_default_limit_by_state() |
4.4.2.2、hps_algo_main
1 | _hps_task_main() -> hps_algo_main() |
当前hps_algo_main()的算法对应有几种:
1 | static int (*hps_func[]) (void) = { |
4.5、NUMA负载均衡
NUMA arm架构没有使用,暂时不去解析。
5、EAS(Energy-Aware Scheduling)
5.1、smp rebalance
通过搜索关键字“energy_aware()”,来查看EAS对smp负载均衡的影响。
可以看到EAS对负载均衡的策略是这样的:在overutilized的情况下,使用传统的smp/hmp负载均衡方法;在非overutilized的情况下,使用eas的均衡方法。
EAS的负载均衡和原有方法的区别有几部分:
- 1、在EAS使能且没有overutilized的情况下,hmp负载均衡不工作;
- 2、在EAS使能且没有overutilized的情况下,smp负载均衡不工作;
- 3、在EAS使能且没有overutilized的情况下,EAS的主要工作集中在进程唤醒/新建时选择运行cpu上select_task_rq_fair();
5.1.1、rebalance_domains()
- 1、在EAS使能且没有overutilized的情况下,hmp负载均衡不使能;
1 | static void run_rebalance_domains(struct softirq_action *h) |
- 2、在load_balance() -> find_busiest_group()中,如果在EAS使能且没有overutilized的情况下,不进行常规的smp负载均衡;
1 | static struct sched_group *find_busiest_group(struct lb_env *env) |
5.1.2、select_task_rq_fair()
参考4.1.2.3、select_task_rq_fair()这一节的详细描述。
5.2、cpufreq_sched/schedutil governor
sched governor比较传统interactive governor有以下优点:
- 1、负载变化的时间更快。interactive是20ms统计一次负载,而sched governor是在schedule_tick()中更新负载,tick的时间更短;
- 2、interactive的负载计算有问题:历史负载没有老化;历史频率除以现在频率不合理;
interactive governor的主要思想就是综合rt、cfs的负载,判断当前freq的capacity是否满足需求,是否需要调频。
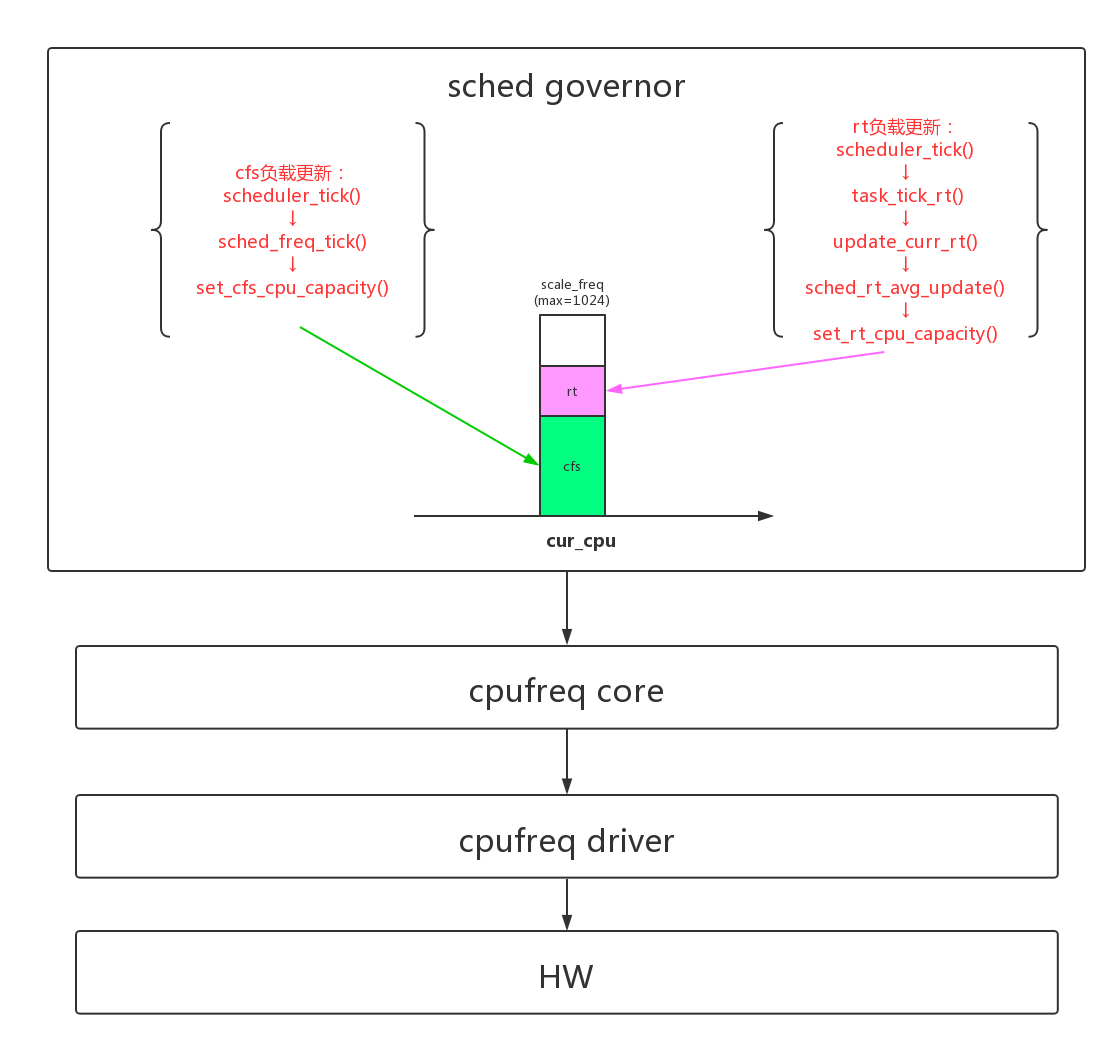
5.2.1、rt request
针对CONFIG_CPU_FREQ_GOV_SCHED,rt有3条关键计算路径:
- 1、rt负载的(rq->rt_avg)的累加:scheduler_tick() -> task_tick_rt() -> update_curr_rt() -> sched_rt_avg_update()
rq->rt_avg = 累加时间分量 * 当前frq分量(最大1024)
1 | static inline void sched_rt_avg_update(struct rq *rq, u64 rt_delta) |
- 2、rt负载的老化:scheduler_tick() -> update_cpu_load() -> update_cpu_load() -> sched_avg_update()
或者scheduler_tick() -> task_tick_rt() -> sched_rt_update_capacity_req() -> sched_avg_update()
rq->rt_avg的老化比较简单,每个period老化1/2。
1 | void sched_avg_update(struct rq *rq) |
- 3、rt request的更新:scheduler_tick() -> task_tick_rt() -> sched_rt_update_capacity_req() -> set_rt_cpu_capacity()
rt request的计算有点粗糙: request = rt_avg/(sched_avg_period() + delta),rt_avg中没有加上delta时间的负载。
1 | static void sched_rt_update_capacity_req(struct rq *rq) |
5.2.2、cfs request
同样,cfs也有3条关键计算路径:
- 1、cfs负载的(rq->rt_avg)的累加:scheduler_tick() -> task_tick_fair() -> entity_tick() -> update_load_avg()
- 2、cfs负载的老化:scheduler_tick() -> task_tick_fair() -> entity_tick() -> update_load_avg()
- 3、cfs request的更新:scheduler_tick() -> sched_freq_tick() -> set_cfs_cpu_capacity()
1 | static void sched_freq_tick(int cpu) |
5.2.3、freq target
1 | void update_cpu_capacity_request(int cpu, bool request, int type) |
5.3、WALT(Windows Assisted Load Tracking)
在qualcomm 8898中,使用了WALT作为负载计算方法,也使用了自己的负载均衡算法来使用WALT负载。代码中使用CONFIG_SCHED_HMP来标示qualcomm自己负载均衡方法。
5.3.1、WALT的负载计算
Walt的本质也是时间窗分量,结合freq分量、capacity分量等一起表达的一个负载相对值。我们首先来看看几个分量的计算方法。
- 1、cluster->efficiency计算:从dts中读取,我们可以看到,四个小核的efficiency是1024,四个大核的efficiency是1638;
1 | static struct sched_cluster *alloc_new_cluster(const struct cpumask *cpus) |
- 2、cluster->capacity:计算和最小值的正比:capacity = 1024 (cluster->efficiencycluster_max_freq(cluster)) / (min_possible_efficiency*min_max_freq)
- 3、cluster->max_possible_capacity:计算和最小值的正比:capacity = 1024 (cluster->efficiencycluster->max_possible_freq) / (min_possible_efficiency*min_max_freq)
- 4、cluster->load_scale_factor:计算和最大值的反比:lsf = 1024 (max_possible_efficiencymax_possible_freq) / (cluster->efficiency*cluster_max_freq(cluster))
- 5、cluster->exec_scale_factor:计算和最大值的正比:exec_scale_factor = 1024 * cluster->efficiency / max_possible_efficiency
1 | static void update_all_clusters_stats(void) |
- 6、cluster->max_power_cost:cluster的最大功耗 = voltage^2 * frequence
- 7、cluster->min_power_cost:cluster的最小功耗 = voltage^2 * frequence
1 | static void sort_clusters(void) |
5.3.1.1、update_task_ravg()
walt关于进程的负载计算流程如下:
- 1、把时间分成一个个window窗口,累加时间时,需要综合efficiency和freq分量(也就是capacity):delta = delta_time (curr_freq/max_possible_freq) (cluster->efficiency/max_possible_efficiency);
1 | static inline u64 scale_exec_time(u64 delta, struct rq *rq) |
- 2、统计runnable状态的时间:account_busy_for_task_demand()屏蔽掉runnable以外的其他状态的时间统计;
1 | static int account_busy_for_task_demand(struct task_struct *p, int event) |
- 3、在统计时间时,可能碰到的3种组合情况:
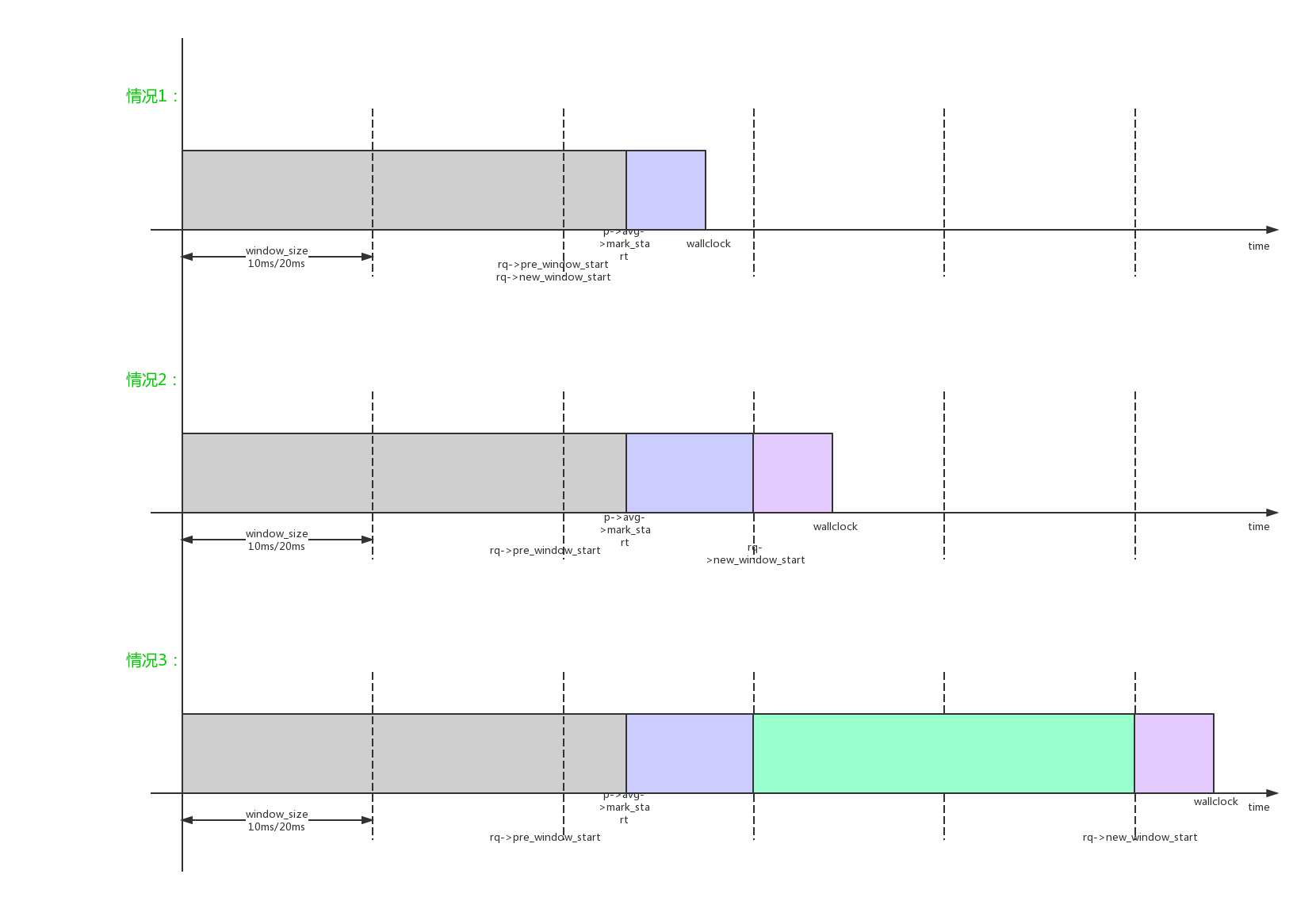
- 4、如果一个window还没有完成,会逐步累加时间到p->ravg.sum;如果一个window完成,存储最新window负载到p->ravg.sum_history[RAVG_HIST_SIZE_MAX]中,sum_history[]一共有5个槽位;系统根据sched_window_stats_policy选择策略(RECENT、MAX、AVG、MAX_RECENT_AVG),根据sum_history[]计算选择一个合适的值作为进程负载p->ravg.demand;同时根据sum_history[]的计算进程的负载预测p->ravg.pred_demand;

5、walt的task级别的负载是p->ravg.demand,cpu级别负载是rq->hmp_stats.cumulative_runnable_avg;
6、
具体的update_task_ravg()代码解析如下:
1 | scheduler_tick() -> update_task_ravg() |
我们再来详细看看cpu级别的busy time计算:
1 | static void update_cpu_busy_time(struct task_struct *p, struct rq *rq, |
5.3.2、基于WALT的负载均衡
5.3.2.1、load_balance()
其他部分和主干内核算法一致,这里只标识出qualcom的HMP算法特有的部分。在负载均衡部分,walt用来找出cpu;但是在负载迁移时,计算负载还是使用pelt?
- 在find_busiest_queue()中:原本是找出cfs_rq->runnable_load_avg * capacity负载最大的cpu,qualcom HMP改为找出walt runnable负载(rq->hmp_stats.cumulative_runnable_avg)最重的cpu。
1 | run_rebalance_domains() -> rebalance_domains() -> load_balance() -> find_busiest_queue() -> find_busiest_queue_hmp() |
5.3.2.2、nohz_idle_balance()
- _nohz_kick_needed():
1 | scheduler_tick() -> trigger_load_balance() -> nohz_kick_needed() -> _nohz_kick_needed() -> nohz_kick_needed_hmp() |
- find_new_hmp_ilb():原本是找出nohz.idle_cpus_mask中的第一个cpu作为ilb cpu,qualcom HMP改为尝试在nohz.idle_cpus_mask中找到一个max power小于当前cpu的作为ilb cpu。
1 | scheduler_tick() -> trigger_load_balance() -> nohz_balancer_kick() -> find_new_ilb() |
5.3.2.3、select_task_rq_fair()
- select_task_rq_fair():使用qualcom自己的算法,综合capacity、power、idle给出一个best cpu。
1 | select_task_rq_fair() -> select_best_cpu() |
5.3.2.4、Interaction Governor & sched_load
qualcom对interactive governor进行了改造,打造成了可以使用sched_load的interactive governor。

- 1、interactive governor注册回调函数,接收sched_load变化事件;
1 | static ssize_t store_use_sched_load( |
- 2、sched_load的变化通过回调函数通知给Interaction Governor;
1 | check_for_freq_change() -> load_alert_notifier_head -> load_change_callback() |
- 3、除了事件通知,interactive governor还会在20ms timer中轮询sched_load的变化来决定是否需要调频。
1 | static void cpufreq_interactive_timer(unsigned long data) |
6、Cgoup
6.1、cgroup概念
cgroup最基本的操作时我们可以使用以下命令创建一个cgroup文件夹:
1 | mount -t cgroup -o cpu,cpuset cpu&cpuset /dev/cpu_cpuset_test |
那么/dev/cpu_cpuset_test文件夹下就有一系列的cpu、cpuset cgroup相关的控制节点,tasks文件中默认加入了所有进程到这个cgroup中。可以继续创建子文件夹,子文件夹继承了父文件夹的结构形式,我们可以给子文件夹配置不同的参数,把一部分进程加入到子文件夹中的tasks文件当中,久可以实现分开的cgroup控制了。
一个简单明了的例子如下图所示:
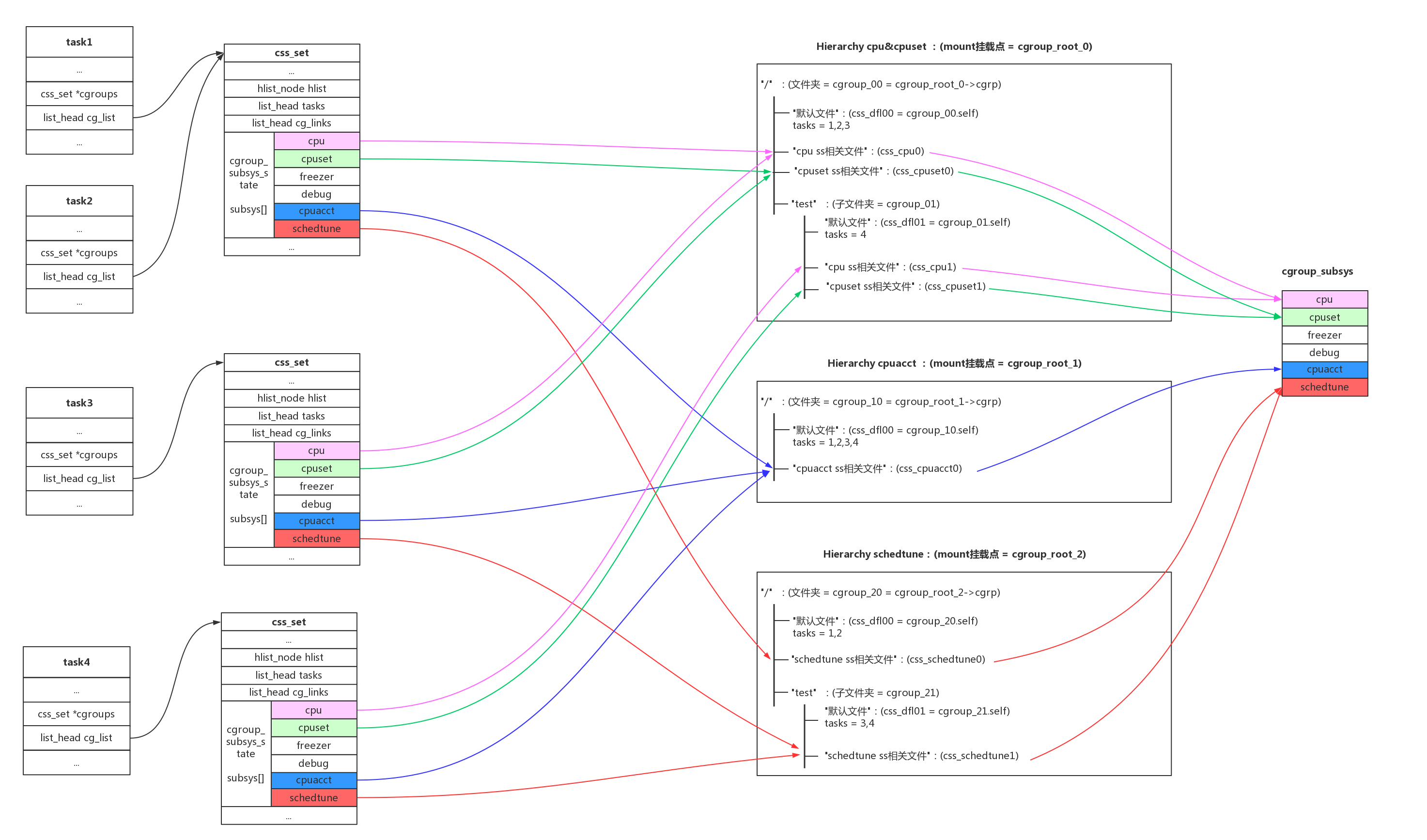
关于cgroup的结构有以下规则和规律:
- 1、cgroup有很多subsys,我们平时接触到的cpu、cpuset、cpuacct、memory、blkio都是cgroup_subsys;
- 2、一个cgroup hierarchy,就是使用mount命令挂载的一个cgroup文件系统,hierarchy对应mount的根cgroup_root;
- 3、一个hierarchy可以制定一个subsys,也可以制定多个subsys。可以是一个subsys,也可以是一个subsys组合;
- 4、一个subsys只能被一个hierarchy引用一次,如果subsys已经被hierarchy引用,新hierarchy创建时不能引用这个subsys;唯一例外的是,我们可以创建和旧的hierarchy相同的subsys组合,这其实没有创建新的hierarchy,只是简单的符号链接;
- 5、hierarchy对应一个文件系统,cgroup对应这个文件系统中的文件夹;subsys是基类,而css(cgroup_subsys_state)是cgroup引用subsys的实例;比如父目录和子目录分别是两个cgroup,他们都要引用相同的subsys,但是他们需要不同的配置,所以会创建不同的css供cgroup->subsys[]来引用;
- 6、一个任务对系统中不同的subsys一定会有引用,但是会引用到不同的hierarchy不同的cgroup即不同css当中;所以系统使用css_set结构来管理任务对css的引。如果任务引用的css组合相同,那他们开源使用相同的css_set;
- 7、还有cgroup到task的反向引用,系统引入了cg_group_link结构。这部分可以参考Docker背后的内核知识——cgroups资源限制一文的描述,如下图的结构关系:
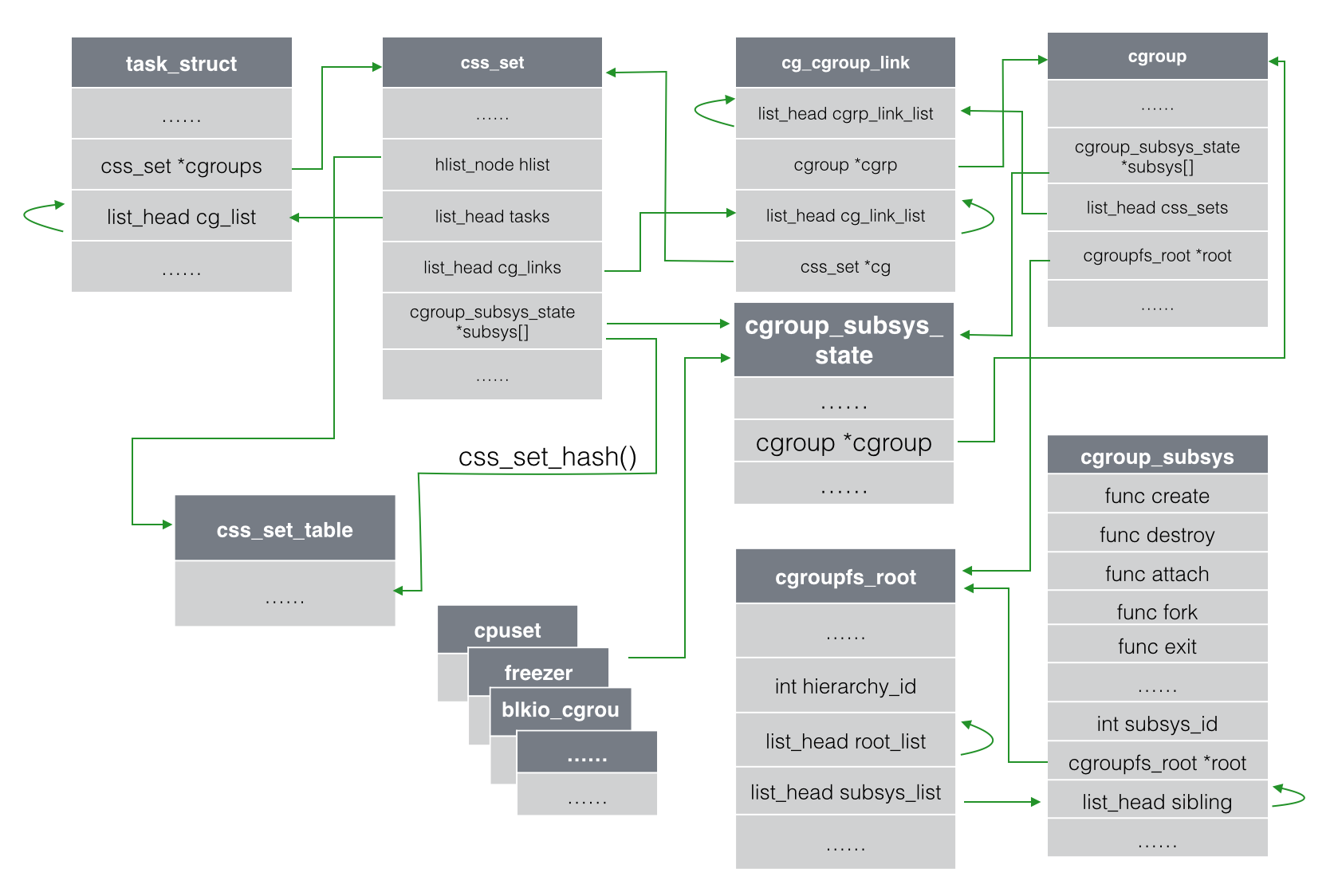
6.2、代码分析
1、”/proc/cgroups”
- subsys的链表:for_each_subsys(ss, i)
- 一个susbsys对应一个hierarchy:ss->root
- 一个hierarchy有多少个cgroup:ss->root->nr_cgrps
1 | # ount -t cgroup -o freezer,debug bbb freezer_test/ |
1 | static int proc_cgroupstats_show(struct seq_file *m, void *v) |
2、”/proc/pid/cgroup”
- 每种subsys组合组成一个新的hierarchy,每个hierarchy在for_each_root(root)中创建一个root树;
- 每个hierarchy顶层目录和子目录都是一个cgroup,一个hierarchy可以有多个cgroup,对应的subsys组合一样,但是参数不一样
- cgroup_root自带一个cgroup即root->cgrp,作为hierarchy的顶级目录
- 一个cgroup对应多个subsys,使用cgroup_subsys_state类型(css)的cgroup->subsys[CGROUP_SUBSYS_COUNT]数组去和多个subsys链接;
- 一个cgroup自带一个cgroup_subsys_state即cgrp->self,这个css的作用是css->parent指针,建立起cgroup之间的父子关系;
- css一个公用结构,每个subsys使用自己的函数ss->css_alloc()分配自己的css结构,这个结构包含公用css + subsys私有数据;
- 每个subsys只能存在于一个组合(hierarchy)当中,如果一个subsys已经被一个组合引用,其他组合不能再引用这个subsys。唯一例外的是,我们可以重复mount相同的组合,但是这样并没有创建新组合,只是创建了一个链接指向旧组合;
- 进程对应每一种hierarchy,一定有一个cgroup对应。
1 | # cat /proc/832/cgroup |
1 | int proc_cgroup_show(struct seq_file *m, struct pid_namespace *ns, |
3、初始化
1 | int __init cgroup_init_early(void) |
4、mount操作
创建新的root,因为ss默认都和默认root(cgrp_dfl_root)建立了关系,所以ss需要先解除旧的root链接,再和新root建立起链接。
1 | static struct dentry *cgroup_mount(struct file_system_type *fs_type, |
5、文件操作
创建一个新文件夹,相当于创建一个新的cgroup。我们重点来看看新建文件夹的操作:
1 | static struct kernfs_syscall_ops cgroup_kf_syscall_ops = { |
cgroup默认文件,有一些重要的文件比如“tasks”,我们来看看具体的操作。
1 | static struct cftype cgroup_legacy_base_files[] = { |
6.3、cgroup subsystem
我们关注cgroup子系统具体能提供的功能。
6.3.1、cpu
kernel/sched/core.c。会创建新的task_group,可以对cgroup对应的task_group进行cfs/rt类型的带宽控制。
1 | static struct cftype cpu_files[] = { |
6.3.2、cpuset
kernel/cpusec.c。给cgroup分配不同的cpu和mem node节点,还可以配置一些flag。
1 | static struct cftype files[] = { |
6.3.3、schedtune
kernel/sched/tune.c,可以进行schedle boost操作。
1 | static struct cftype files[] = { |
6.3.4、cpuacct
kernel/sched/cpuacct.c,可以按照cgroup的分组来统计cpu占用率。
1 | static struct cftype files[] = { |
参考资料
7、系统级负载的计算:Linux Load Averages: Solving the Mystery
10、[MTK文档:CPU Utilization-scheduler(V1.1)]