BPF的字面上意思Berkeley Packet Filter意味着它是从包过滤而来。如果在开始前对BPF缺乏感性的认识建议先看一下参考文档:“3.1、Berkeley Packet Filter (BPF) (Kernel Document)”、“3.2、BPF and XDP Reference Guide”。
本质上它是一种内核代码注入的技术:
- 内核中实现了一个cBPF/eBPF虚拟机;
- 用户态可以用C来写运行的代码,再通过一个Clang&LLVM的编译器将C代码编译成BPF目标码;
- 用户态通过系统调用bpf()将BPF目标码注入到内核当中;
- 内核通过JIT(Just-In-Time)将BPF目编码转换成本地指令码;如果当前架构不支持JIT转换内核则会使用一个解析器(interpreter)来模拟运行,这种运行效率较低;
- 内核在packet filter和tracing等应用中提供了一系列的钩子来运行BPF代码。目前支持以下类型的BPF代码:
1 | static int __init register_kprobe_prog_ops(void) |
BPF的好处在哪里? 是因为它提供了一种在不修改内核代码的情况下,可以灵活修改内核处理策略的方法。
这在包过滤和系统tracing这种需要频繁修改规则的场合非常有用。因为如果只在用户态修改策略的话那么所有数据需要复制一份给用户态开销较大;如果在内核态修改策略的话需要修改内核代码重新编译内核,而且容易引人安全问题。BPF这种内核代码注入技术的生存空间就是它可以在这两者间取得一个平衡。
Systamp就是解决了这个问题得以发展的,它使用了ko的方式来实现内核代码注入(有点笨拙,但是也解决了实际问题)。
Systemtap工作原理:是通过将脚本语句翻译成C语句,编译成内核模块。模块加载之后,将所有探测的事件以Kprobe钩子的方式挂到内核上,当任何处理器上的某个事件发生时,相应钩子上句柄就会被执行。最后,当systemtap会话结束之后,钩子从内核上取下,移除模块。整个过程用一个命令stap就可以完成。
既然是提供向内核注入代码的技术,那么安全问题肯定是重中之重。平时防范他人通过漏洞向内核中注入代码,这下子专门开了一个口子不是大开方便之门。所以内核指定了很多的规则来限制BPF代码,确保它的错误不会影响到内核:
- 一个BPF程序的代码数量不能超过BPF_MAXINSNS (4K),它的总运行步数不能超过32K (4.9内核中这个值改成了96k);
- BPF代码中禁止循环,这也是为了保证出错时不会出现死循环来hang死内核。一个BPF程序总的可能的分支数也被限制到1K;
- 为了限制它的作用域,BPF代码不能访问全局变量,只能访问局部变量。一个BPF程序只有512字节的堆栈。在开始时会传入一个ctx指针,BPF程序的数据访问就被限制在ctx变量和堆栈局部变量中;
- 如果BPF需要访问全局变量,它只能访问BPF map对象。BPF map对象是同时能被用户态、BPF程序、内核态共同访问的,BPF对map的访问通过helper function来实现;
- 旧版本BPF代码中不支持BPF对BPF函数的调用,所以所有的BPF函数必须声明成always_inline。在Linux内核4.16和LLVM 6.0以后,才支持BPF to BPF Calls;
- BPF虽然不能函数调用,但是它可以使用Tail Call机制从一个BPF程序直接跳转到另一个BPF程序。它需要通过BPF_MAP_TYPE_PROG_ARRAY类型的map来知道另一个BPF程序的指针。这种跳转的次数也是有限制的,32次;
- BPF程序可以调用一些内核函数来辅助做一些事情(helper function);
- 有些架构(64 bit x86_64, arm64, ppc64, s390x, mips64, sparc64 and 32 bit arm)已经支持BPF的JIT,它可以高效的几乎一比一的把BPF代码转换成本机代码(因为eBPF的指令集已经做了优化,非常类似最新的arm/x86架构,ABI也类似)。如果当前架构不支持JTI只能使用内核的解析器(interpreter)来模拟运行;
- 内核还可以通过一些额外的手段来加固BPF的安全性(Hardening)。主要包括:把BPF代码映像和JIT代码映像的page都锁成只读,JIT编译时把常量致盲(constant blinding),以及对bpf()系统调用的权限限制;
对BPF这些安全规则的检查主要是在BPF代码加载时,通过BPF verifier来实现的。大概分为两步:
- 第一步,通过DAG(Directed Acyclic Graph 有向无环图)的DFS(Depth-first Search)深度优先算法来遍历BPF程序的代码路径,确保没有环路发生;
- 第二步,逐条分析BPF每条指令的运行,对register和对stack的影响,最坏情况下是否有越界行为(对变量的访问是否越界,运行的指令数是否越界)。这里也有一个快速分析的优化方法:修剪(Pruning)。如果当前指令的当前分支的状态,和当前指令另一个已分析分支的状态相等或者是它的一个子集,那么当前指令的当前分支就不需要分析了,因为它肯定是符合规则的。
整个BPF的开发过程大概如下图所示:
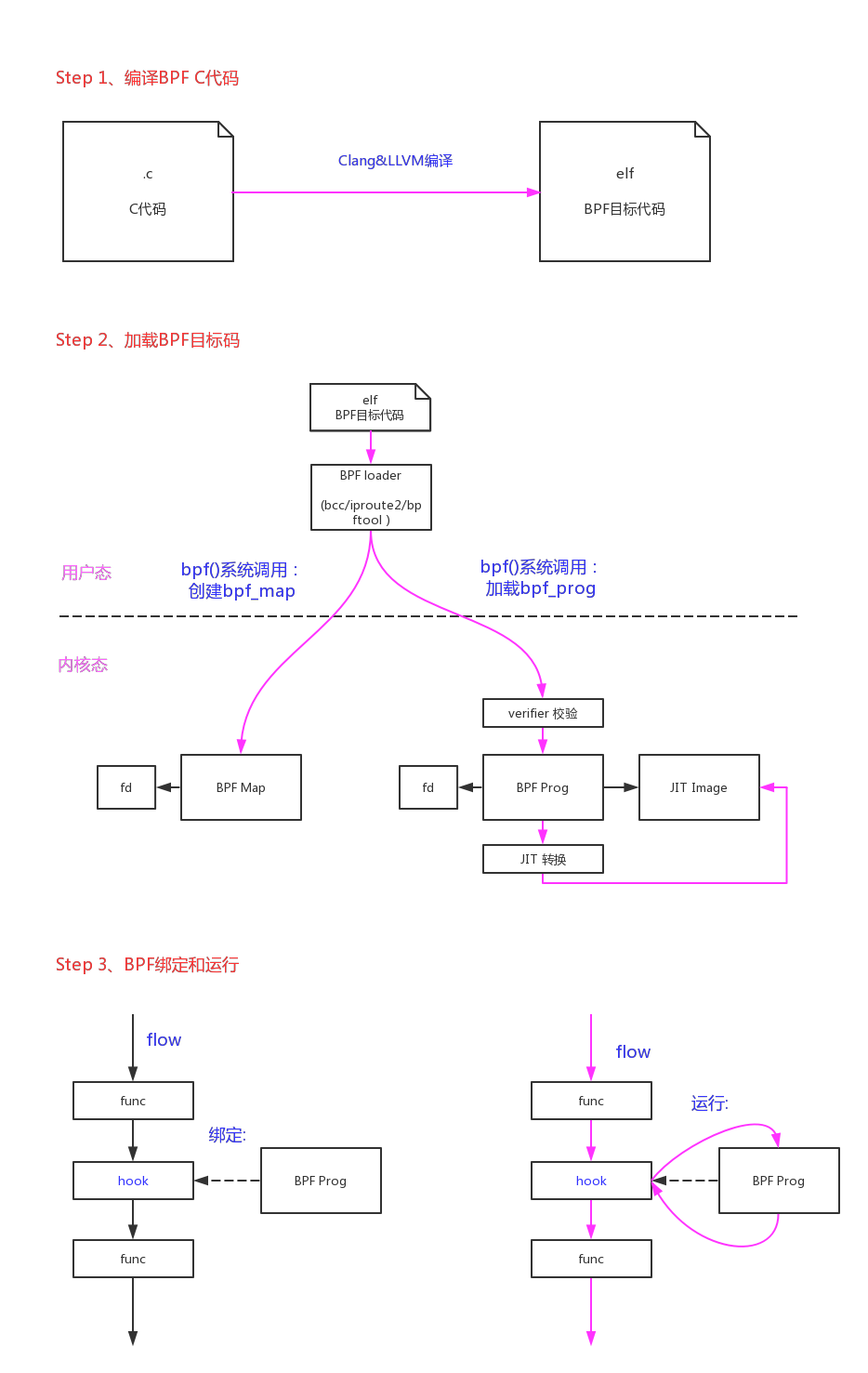
1、bpf()系统调用
核心代码在bpf()系统调用中,我们从入口开始分析。
1 | SYSCALL_DEFINE3(bpf, int, cmd, union bpf_attr __user *, uattr, unsigned int, size) |
1.1、bpf加载
BPF_PROG_LOAD命令负责加载一段BPF程序到内核当中:
- 拷贝程序到内核;
- 校验它的安全性;
- 如果可能对它进行JIT编译;
- 然后分配一个文件句柄fd给它。
完成这一切后,后续再把这段BPF程序挂载到需要运行的钩子上面。
1.1.1、bpf内存空间分配
1 | static int bpf_prog_load(union bpf_attr *attr) |
这其中对BPF来说有个重要的数据结构就是struct bpf_prog:
1 | struct bpf_prog { |
其中重要的成员如下:
- len:程序包含bpf指令的数量;
- type:当前bpf程序的类型(kprobe/tracepoint/perf_event/sk_filter/sched_cls/sched_act/xdp/cg_skb);
- aux:主要用来辅助verifier校验和转换的数据;
- orig_prog:
- bpf_func:运行时BPF程序的入口。如果JIT转换成功,这里指向的就是BPF程序JIT转换后的映像;否则这里指向内核解析器(interpreter)的通用入口__bpf_prog_run();
- insnsi[]:从用户态拷贝过来的,BPF程序原始指令的存放空间;
1.1.2、bpf verifier
关于verifier的步骤和规则,在“3.1、Berkeley Packet Filter (BPF) (Kernel Document)”一文的“eBPF verifier”一节有详细描述。
另外,在kernel/bpf/verifier.c文件的开头对eBPF verifier也有一段详细的注释:
1 |
|
原文如下:
1 | /* bpf_check() is a static code analyzer that walks eBPF program |
BPF verifier总体代码流程如下:
1 | int bpf_check(struct bpf_prog **prog, union bpf_attr *attr) |
- 1、把BPF程序中操作map的指令,从map_fd替换成实际的map指针。
由此可见用户态的loader程序,肯定是先根据__section(“maps”)中定义的map调用bpf()创建map,再加载其他的程序section。
符合条件:(insn[0].code == (BPF_LD | BPF_IMM | BPF_DW)) && (insn[0]->src_reg == BPF_PSEUDO_MAP_FD) 的指令为map指针加载指针。
把原始的立即数作为fd找到对应的map指针。
把64bit的map指针拆分成两个32bit的立即数,存储到insn[0].imm、insn[1].imm中。
1 | static int replace_map_fd_with_map_ptr(struct bpf_verifier_env *env) |
- 2、Step 1、通过DAG(Directed Acyclic Graph 有向无环图)的DFS(Depth-first Search)深度优先算法来遍历BPF程序的代码路径,确保没有环路发生;
DAG的DFS算法可以参考“Graph”一文。其中最重要的概念如下图:
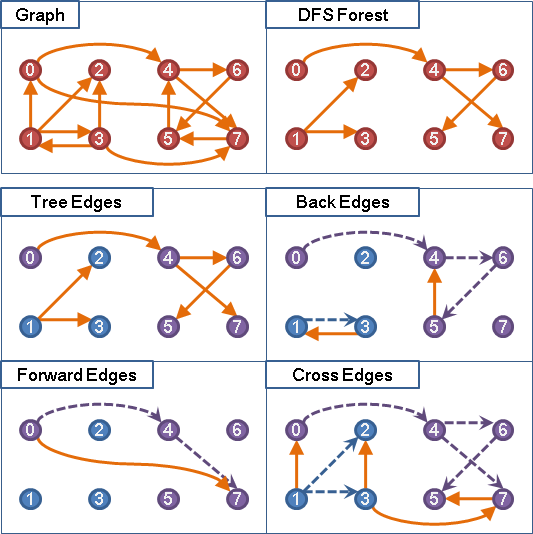
一个图形”Graph”经过DAG的DFS算法遍历后,对每一个根节点都会形成一颗树“DFS Tree”,多个根节点得到的多棵树形成一个森林”DFS Forest”。根据搜索的结构整个“Graph”的边“Edge”可以分成四类:
- Tree Edges:在DFS树上的边;
- Back Edges:从子节点连向祖先节点的边(形成环);
- Forward Edges:直接连向孙节点的边(跨子节点的连接);
- Cross Edges:叶子之间的连接,或者树之间的连接;
对BPF verifier来说,检查BPF程序的运行路径图中是否有“Back Edges”的存在,确保程序中没有环路。
具体的代码如下:
1 | static int check_cfg(struct bpf_verifier_env *env) |
- 3、step2、详细扫描BPF代码的运行过程,跟踪分析寄存器和堆栈,检查是否有不符合规则的情况出现。
这段代码的具体算法就是把step1的路径重新走一遍,并且跟踪寄存器和堆栈的变化,判断最坏情况下是否有违反规则的情况出现。
在碰到指令对应explored_states[]被设置成STATE_LIST_MARK,需要给当前指令独立分配一个bpf_verifier_state_list链表,来存储这个指令在多个分支上的不同状况。
这里也有一个快速分析的优化方法:修剪(Pruning)。如果当前指令的当前分支的状态cur_state,和当前指令另一个已分析分支的状态(当前指令explored_states[]链表中的一个bpf_verifier_state_list成员)相等或者是它的一个子集,那么当前指令的当前分支就不需要分析了,因为它肯定是符合规则的。
1 | static int do_check(struct bpf_verifier_env *env) |
- 4、修复BPF指令中对内核helper function函数的调用,把函数编号替换成实际的函数指针。
符合条件:(insn->code == (BPF_JMP | BPF_CALL)) 的指令,即是调用helper function的指令。
通用helper function的处理:根据insn->imm指定的编号找打对应的函数指针,然后再把函数指针和__bpf_call_base之间的offset,赋值到insn->imm中。
1 | static int fixup_bpf_calls(struct bpf_verifier_env *env) |
1.1.3、bpf JIT/kernel interpreter
在verifier验证通过以后,内核通过JIT(Just-In-Time)将BPF目编码转换成本地指令码;如果当前架构不支持JIT转换内核则会使用一个解析器(interpreter)来模拟运行,这种运行效率较低;
有些架构(64 bit x86_64, arm64, ppc64, s390x, mips64, sparc64 and 32 bit arm)已经支持BPF的JIT,它可以高效的几乎一比一的把BPF代码转换成本机代码(因为eBPF的指令集已经做了优化,非常类似最新的arm/x86架构,ABI也类似)。如果当前架构不支持JTI只能使用内核的解析器(interpreter)来模拟运行;
1 | struct bpf_prog *bpf_prog_select_runtime(struct bpf_prog *fp, int *err) |
- 1、JIT
以arm64的JIT转换为例:
1 | struct bpf_prog *bpf_int_jit_compile(struct bpf_prog *prog) |
JIT的核心转换分为3部分:prologue + body + epilogue。
prologue:新增的指令,负责BPF运行堆栈的构建和运行现场的保护;
body:BPF主体部分;
epilogue:负责BPF运行完现场的恢复和清理;
- 1.1、prologue
A64_:开头的是本机的相关寄存器
BPF_:开头的是BPF虚拟机的寄存器
整个过程还是比较巧妙的:
首先将A64_FP/A64_LR保存进堆栈A64_SP,然后把当前A64_SP保存进A64_FP;
继续保存callee saved registers进堆栈A64_SP:r6, r7, r8, r9, fp, tcc,然后把当前A64_SP保存进BPF_FP;
把A64_SP减去STACK_SIZE,给BPF_FP留出512字节的堆栈空间;
这样BPF程序使用的是BPF_FP开始的512字节堆栈空间,普通kernel函数使用的是A64_SP继续向下的堆栈空间,互不干扰;
1 | static int build_prologue(struct jit_ctx *ctx) |
- 1.2、body
把BPF指令翻译成本地arm64指令:
1 | static int build_body(struct jit_ctx *ctx) |
- 1.3、epilogue
做和prologue相反的工作,恢复和清理堆栈:
1 | static void build_epilogue(struct jit_ctx *ctx) |
- 2、interpreter
对于不支持JIT的情况,内核只能使用一个解析器来解释prog->insnsi[]中BPF的指令含义,模拟BPF指令的运行:
使用“u64 stack[MAX_BPF_STACK / sizeof(u64)]”局部变量来模拟BPF堆栈空间;
使用“u64 regs[MAX_BPF_REG]”局部变量来模拟BPF寄存器;
1 | /** |
- 3、BPF_PROG_RUN()
不论是转换成JIT的映像,或者是使用interpreter解释器。最后BPF程序运行的时候都是使用BPF_PROG_RUN()这个宏来调用的:
1 | ret = BPF_PROG_RUN(prog, ctx); |
1.1.4、fd分配
对于加载到内核空间的BPF程序,最后会给它分配一个文件句柄fd,将prog存储到对应的file->private_data上。方便后续的引用。
1 | int bpf_prog_new_fd(struct bpf_prog *prog) |
1.2、bpf map操作
BPF map的应用场景有几种:
- BPF程序和用户态态的交互:BPF程序运行完,得到的结果存储到map中,供用户态访问;
- BPF程序内部交互:如果BPF程序内部需要用全局变量来交互,但是由于安全原因BPF程序不允许访问全局变量,可以使用map来充当全局变量;
- BPF Tail call:Tail call是一个BPF程序跳转到另一BPF程序,BPF程序首先通过BPF_MAP_TYPE_PROG_ARRAY类型的map来知道另一个BPF程序的指针,然后调用tail_call()的helper function来执行Tail call。
- BPF程序和内核态的交互:和BPF程序以外的内核程序交互,也可以使用map作为中介;
目前,支持的map种类:
1 | static int __init register_array_map(void) |
不论哪种map,对map的使用都是用”键-值“对(key-value)的形式来使用的。
1.2.1、map的创建
如果用户态的BPF c程序有定义map,map最后会被编译进section(“maps”)。
用户态的loader在加载BPF程序的时候,首先会根据section(“maps”)中的成员来调用bpf()系统调用来创建map对象。
1 | static int map_create(union bpf_attr *attr) |
- 1、BPF_MAP_TYPE_ARRAY
我们以BPF_MAP_TYPE_ARRAY类型的map为例,来看看map的分配过程:
从用户态传过来的attr成员意义如下:
attr->map_type:map的类型;
attr->key_size:键key成员的大小;
attr->value_size:值value成员的大小;
attr->max_entries:需要存储多少个条目(“键-值“对)
1 | static const struct bpf_map_ops array_ops = { |
- 2、BPF_MAP_TYPE_HASH
我们以BPF_MAP_TYPE_HASH类型的map为例,来看看map的分配过程:
1 | static const struct bpf_map_ops htab_ops = { |
1.2.2、map的查找
查找就是通过key来找到对应的value。
1 | static int map_lookup_elem(union bpf_attr *attr) |
- 1、BPF_MAP_TYPE_ARRAY
BPF_MAP_TYPE_ARRAY类型的map最终调用到array_map_lookup_elem():
1 | static void *array_map_lookup_elem(struct bpf_map *map, void *key) |
- 2、BPF_MAP_TYPE_HASH
BPF_MAP_TYPE_HASH类型的map最终调用到htab_map_lookup_elem():
1 | static void *htab_map_lookup_elem(struct bpf_map *map, void *key) |
1.2.3、BPF_FUNC_map_lookup_elem
除了用户态空间需要通过bpf()系统调用来查找key对应的value值。BPF程序中也需要根据key查找到value的地址,然后在BPF程序中使用。BPF程序时通过调用BPF_FUNC_map_lookup_elem helper function来实现的。
我们以perf_event为例,看看BPF_FUNC_map_lookup_elem helper function的实现:
1 | static const struct bpf_verifier_ops perf_event_prog_ops = { |
和bpf()系统调用一样,最后调用的都是map->ops->map_lookup_elem()函数,只不过BPF程序需要返回的是value的指针,而bpf()系统调用需要返回的是value的值。
关于map的helper function,还有BPF_FUNC_map_update_elem、BPF_FUNC_map_delete_elem可以使用,原理一样。
1.3、obj pin
系统把bpf_prog和bpf_map都和文件句柄绑定起来。有一系列的好处:比如可以在用户态使用一系列的通用文件操作;也有一系列的坏处:因为fd生存在进程空间的,其他进程不能访问,而且一旦本进程退出,这些对象都会处于失联状态无法访问。
所以系统也支持把bpf对象进行全局化的声明,具体的做法是把这些对象绑定到一个专用的文件系统当中:
1 | # ls /sys/fs/bpf/ |
具体分为pin操作和get操作。
1.3.1、bpf_obj_pin()
1 | static int bpf_obj_pin(const union bpf_attr *attr) |
1.3.2、bpf_obj_get()
1 | static int bpf_obj_get(const union bpf_attr *attr) |
2、Tracing类型的BPF程序
经过上一节的内容,bpf程序和map已经加载到内核当中了。什么时候bpf程序才能发挥它的作用呢?
这就需要bpf的应用系统把其挂载到适当的钩子上,当钩子所在点的路径被执行,钩子被触发,BPF程序得以执行。
目前应用bpf的子系统分为两大类:
- tracing:kprobe、tracepoint、perf_event
- filter:sk_filter、sched_cls、sched_act、xdp、cg_skb
我们仔细分析一下tracing类子系统应用bpf的过程,tracing类型的bpf操作都是通过perf来完成的。
2.1、bpf程序的绑定
在使用perf_event_open()系统调用创建perf_event并且返回一个文件句柄后,可以使用ioctl的PERF_EVENT_IOC_SET_BPF命令把加载好的bpf程序和当前perf_event绑定起来。
1 | static long perf_ioctl(struct file *file, unsigned int cmd, unsigned long arg) |
如上,perf_event绑定bpf_prog的规则如下:
- 对于PERF_TYPE_HARDWARE、PERF_TYPE_SOFTWARE类型的perf_event,需要绑定BPF_PROG_TYPE_PERF_EVENT类型的BPF prog。event->prog = prog;
- 对于TRACE_EVENT_FL_TRACEPOINT实现的PERF_TYPE_TRACEPOINT类型的perf_event,需要绑定BPF_PROG_TYPE_TRACEPOINT类型的BPF prog。event->tp_event->prog = prog;
- 对于TRACE_EVENT_FL_UKPROBE实现的PERF_TYPE_TRACEPOINT类型的perf_event,需要绑定BPF_PROG_TYPE_KPROBE类型的BPF prog。event->tp_event->prog = prog;
2.2、bpf程序的执行
因为几种perf_event的执行路径不一样,我们分开描述。
- 1、PERF_TYPE_HARDWARE、PERF_TYPE_SOFTWARE类型的perf_event。
1 | static void bpf_overflow_handler(struct perf_event *event, |
- 2、TRACE_EVENT_FL_TRACEPOINT实现的PERF_TYPE_TRACEPOINT类型的perf_event。
1 | static notrace void \ |
- 3、TRACE_EVENT_FL_UKPROBE实现的PERF_TYPE_TRACEPOINT类型的perf_event。
kprobe类型的实现:
1 | static void |
kretprobe类型的实现:
1 | static void |
3、Filter类型的BPF程序
暂不分析