1、简介
ringbuffer是trace框架的一个基础,所有的trace原始数据都是通过ringbuffer记录的。ringbuffer的作用主要有几个:
- 1、存储在内存中,速度非常快,对系统性能的影响降到了最低;
- 2、ring结构,循环写。可以很安全的使用又不浪费内存,能够get到最新的trace信息;
但是,难点并不在这。真正的难点是系统会在常规上下文、中断(NMI、IRQ、SOFTIRQ)等各种场景下都会发生trace,怎么样能既不影响系统的逻辑,又能处理好相互之间的互斥把trace的架构组织好。如果对这部分非常感兴趣可以直接跳转到 第5章 ringbuffer的设计思想 进行学习。
2、ringbuffer初始化
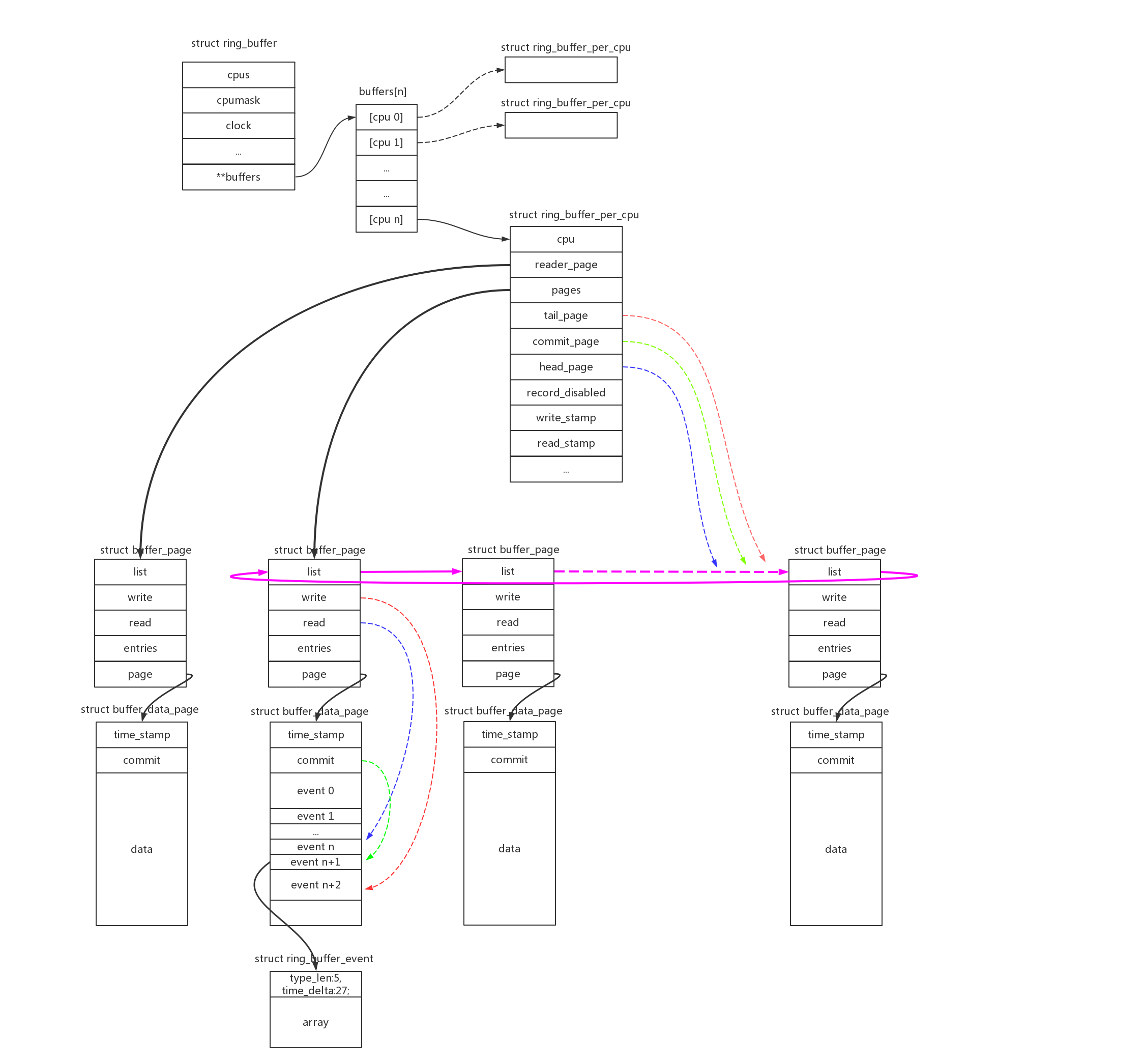
上图是ringbuffer的组织结构顶级视图,可以看到以下信息:
- 1、struct ring_buffer在每个cpu上有独立的struct ring_buffer_per_cpu数据结构;
- 2、struct ring_buffer_per_cpu根据定义size的大小,分配page空间,并把page链成环形结构,这就是“ring”的概念;
- 3、struct buffer_page是一个控制结构;struct buffer_data_page才是一个实际的page,除了开头的两个控制字段time_stamp、commit,其他空间都是用来存储数据的;数据使用struct ring_buffer_event来存储,其在包头中还存储了时间戳、长度/类型信息;
- 4、struct ring_buffer_per_cpu中使用head_page(读)、commit_page(写确认)、tail_page(写)三种指针来管理page ring;同理buffer_page->read(读)、buffer_page->write(写)、buffer_data_page->commit(写确认)用来描述page内的偏移指针;
- 5、ring_buffer_per_cpu->reader_page中还包含了一个独立的page,用来支持reader方式的读操作;
初始化的主要工作就是分配page空间,并且初始化各个控制字段。
start_kernel() -> trace_init() -> tracer_alloc_buffers() -> allocate_trace_buffers() -> allocate_trace_buffer() -> ring_buffer_alloc() -> __ring_buffer_alloc():
1 | struct ring_buffer *__ring_buffer_alloc(unsigned long size, unsigned flags, |
3、ringbuffer的写操作
从ring buffer的设计思想上看,为了支持“nested-write”嵌套写的免锁操作,引入了commit的概念。原理见commit page 一节的描述。
所以ringbuffer的写操作分成以下几步:
- 1、writer使用ring_buffer_lock_reserve()函数移动tail指针,得到需要的空间;
- 2、writer操作得到的ring buffer空间,写数据;
- 3、writer使用ring_buffer_unlock_commit()函数确认数据的写入完成,如果是高优先级抢占其他人的writer会成为pending_commit,只有优先级最低的writer完成full commit并且移动comit指针;
- 4、writer使用ring_buffer_discard_commit()函数丢弃数据。丢弃的方法有两种:1、首先尝试回滚tail指针回收空间;2、如果无法回滚则把数据类型设置为padding再正常的commit,这种空间相当于浪费掉。
这些操作当中,有两件事需要注意:一是ring_buffer_event的存储格式,二是ring_buffer_event时间戳的计算;
3.1、ring_buffer_event的存储格式
writer在ring buffer的page中分配空间,在用户数据之前加了一个ring_buffer_event来进行管理:
1 | struct ring_buffer_event { |
“type_len:5, time_delta:27”为控制结构,在最小情况下占用32bit的空间,表示type、len、time_delta三种信息。
其中前5bit type_len,在不同情况下表示type或者len:
1 | enum ring_buffer_type { |
综合不同情况的列表如下:
| type_len(5bit) | time_delta(27bit) | array0 | type | len | time_delta | 说明 |
|---|---|---|---|---|---|---|
| 0 | - | 存放len | Data record | len = sizeof(array[]),存放在array[0]中 | - | 因为type_len只有5bit,其中分配给表示数据长度的数值只有(0-28),数据默认是4byte对齐的,所以type_len能表示的最大数据长度为284=112bytes。 即:#define RB_MAX_SMALL_DATA (RB_ALIGNMENT RINGBUF_TYPE_DATA_TYPE_LEN_MAX) 在len > RB_MAX_SMALL_DATA的情况下,使用array[0]来存放长度,这种情况下type_len=0。 |
| 1 - 28 | - | - | Data record | len = sizeof(array[]),存放在type_len中,len = type_len << 2 | - | 在len <= RB_MAX_SMALL_DATA的情况下,使用type_len来存放长度。 |
| 29(RINGBUF_TYPE_PADDING) | 0 | - | Padding | len variable | - | Padding类型指的是ringbuffer数据空间分配以后,没有使用被废弃了。 If time_delta is 0: array is ignored,size is variable depending on how much padding is needed |
| 29(RINGBUF_TYPE_PADDING) | >0 | 存放len | Padding | len = sizeof(array[]),存放在array[0]中 | - | Padding类型指的是ringbuffer数据空间分配以后,没有使用被废弃了。 If time_delta is non zero: array[0] holds the actual length |
| 30(RINGBUF_TYPE_TIME_EXTEND) | 存放time_delta的0-27bit | 存放time_delta的28-59bit | Time Extened | len = sizeof(array[])。只有一个array[0],array[]长度固定为4。 | delta = (array[0] << 28) + time_delta | 因为time_delta只有27bit,所以普通“Data record”类型event能表达的最大时间差为2^27ns。 如果时间差超过2^27ns,需要定义一个专门的“Time Extened”event来记录时间差,其利用array[0]来记录time_delta的28-59bit,总共60bit能满足用户时间差的需求。 该event固定长度为8. |
3.2、ring_buffer_event时间戳
ring buffer不但记录了event数据,默认他还给每个event记录加上了时间戳信息。同时为了节约空间,没有记录绝对时间戳,而只是记录相对上一个event的时间差。在每个struct buffer_data_page的开头,都记录了该page第一个commit的绝对时间戳。
那么计算page中event(n)的绝对时间戳 = page->time_stamp + event0->time_delta + event1->time_delta + … + event(n-1)->time_delta:
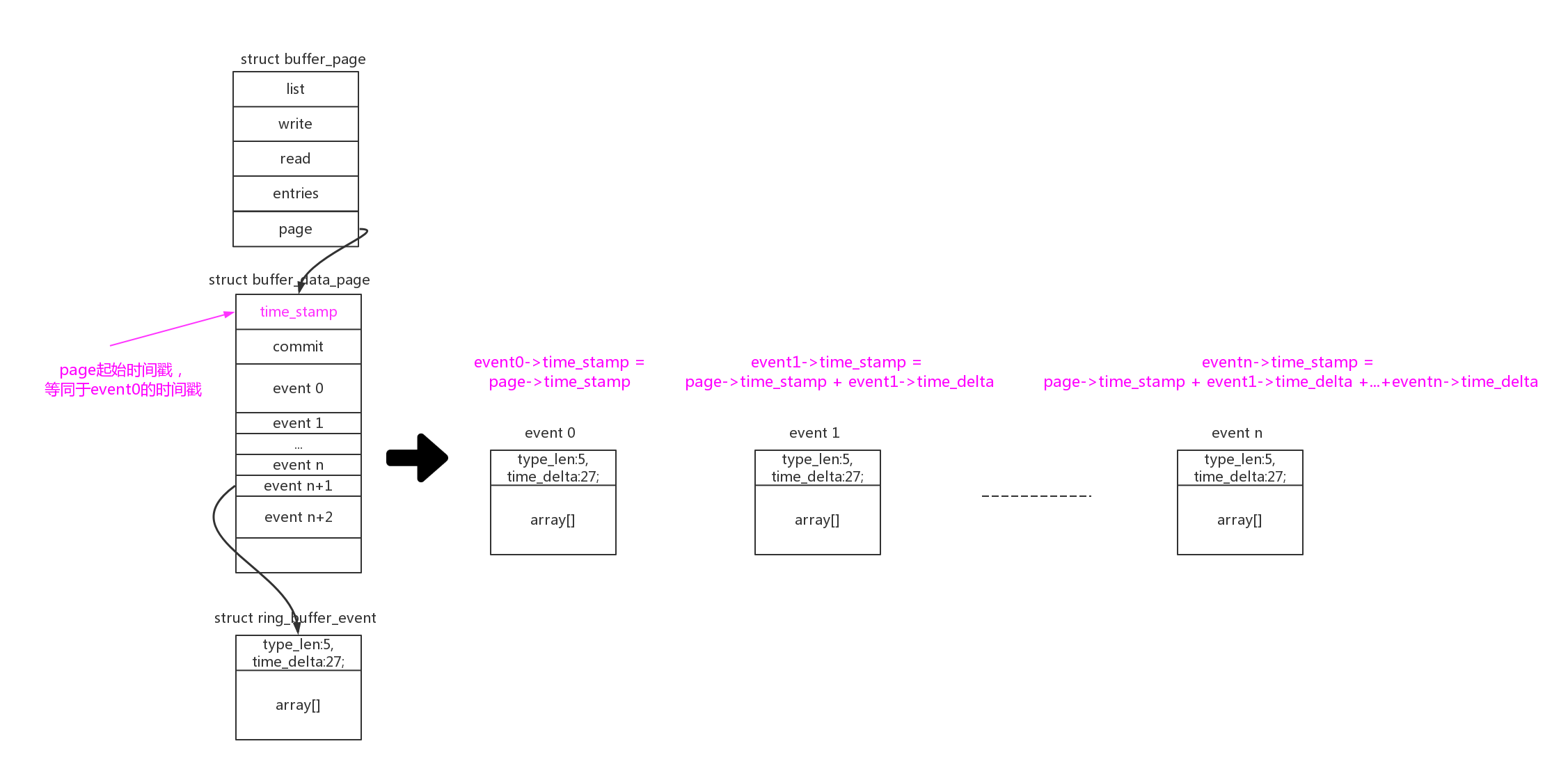
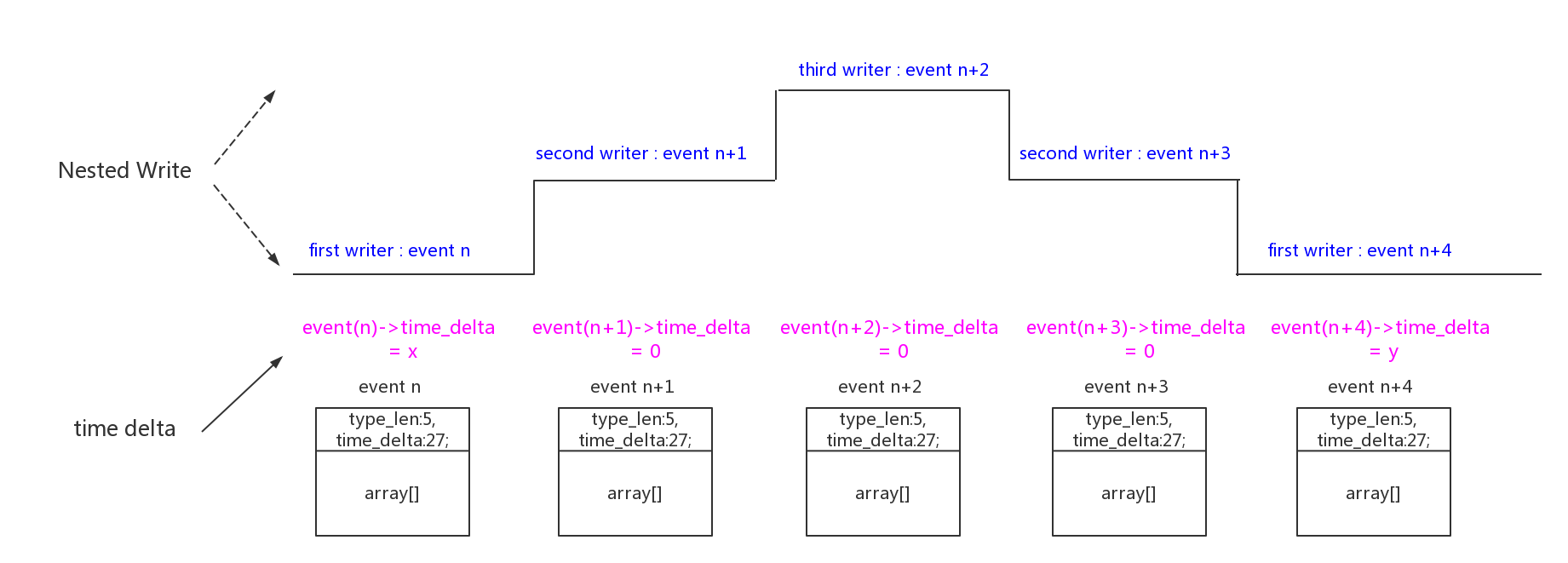
在计算event时间差时,是以一次full commit为单位的。如果发生了“nested-write”,那么这次full commit中多次write分配的event的时间差,最后都为0:
3.3、ring_buffer_event写入流程
3.3.1、ring_buffer_lock_reserve()
1 | struct ring_buffer_event * |
rb_move_tail()是理解复杂无锁指针操作的核心函数,但是已经没有兴趣和心情继续仔细分析了。大的原理上已无问题,后面有需要再仔细分析吧:
1 | static noinline struct ring_buffer_event * |
3.3.2、ring_buffer_unlock_commit()
1 | int ring_buffer_unlock_commit(struct ring_buffer *buffer, |
3.3.3、ring_buffer_discard_commit()
如果不需要分配的空间了,需要明确做丢弃操作。
1 | void ring_buffer_discard_commit(struct ring_buffer *buffer, |
4、ringbuffer的读操作
ringbuffer支持两种形式的读操作:
- iterator读。这个时候会把写入操作关闭,且iterator读不会破坏ringbuffer中原有的内容,重复多次读取内容还在。这个典型的例子就是”/sys/kernel/debug/tracing/trace”文件,我们多次“cat trace”文件来读取trace,内容保持不变。这种方式的缺点也是显而易见的,会disable写入操作,只适合trace完成后,一次性读出所有trace信息;
- reader_page swap读。在ring buffer的设计原理中,多次看到reader_page的swap操作。这个读方式本质上是为了让ring buffer的读写能够同步进行,互不阻塞,但是缺点就是读完会破坏原有buffer中的内容。这个典型的例子就是”/sys/kernel/debug/tracing/trace_pipe”,监控程序可以在抓取trace时并行的来读取ringbuffer中的数据;
关于这部分的原理也可以参考ring buffer 读 这一节。
4.1、iterator读
参考”/sys/kernel/debug/tracing/trace”文件的读操作:
1 | trace_create_file("trace", 0644, d_tracer, |
next()函数最后调用到:
1 | static const struct seq_operations tracer_seq_ops = { |
show()函数最后调用到:
1 | static int s_show(struct seq_file *m, void *v) |
4.2、reader_page swap读
参考”/sys/kernel/debug/tracing/trace_pipe”文件的读操作:
1 | trace_create_file("trace_pipe", 0444, d_tracer, |
5、ringbuffer的设计思想
面临的最大问题:
- ring buffer可能在不同上下文中执行(Normal、NMI、IRQ、SOFTIRQ),对ring buffer的访问是随时可能被打断的,所以对ring buffer的访问需要互斥保护
- ring buffer不能使用常规的lock操作,这样会使不同的上下文之间出现大量的阻塞操作,新增了相互之间的耦合、影响了程序原来的逻辑、影响了性能
最终这个设计使用了一系列的技巧解决了这个问题:原子操作、commit page、RB_PAGE_HEAD、reader_page、重试。这些才是整个ring buffer思想的精华所在。
5.1、术语
| 术语 | Description | 解释 |
|---|---|---|
| tail | where new writes happen in the ring buffer. | ring buffer中下一个写操作的位置 |
| head | where new reads happen in the ring buffer. | ring buffer中下一个读操作的位置 |
| producer | the task that writes into the ring buffer (same as writer) | 生产者:写入数据到ring buffer的任务 |
| writer | same as producer | 写入者,同生产者 |
| consumer | the task that reads from the buffer (same as reader) | 消费者:读出ring buffer中数据的任务 |
| reader | same as consumer. | 读取者,同消费者 |
| reader_page | A page outside the ring buffer used solely (for the most part) by the reader. | 在ring buffer外部的一个单独的page,专门给reader使用的 |
| head_page | a pointer to the page that the reader will use next | 指针,指向reader下一个将要使用的page |
| tail_page | a pointer to the page that will be written to next | 指针,指向下一个将要被写入的page |
| commit_page | a pointer to the page with the last finished non-nested write. | 指针,指向最后一个完成的非嵌套写的位置 |
| cmpxchg | hardware-assisted atomic transaction that performs the following: A = B iff previous A == C R = cmpxchg(A, C, B) is saying that we replace A with B if and only if current A is equal to C, and we put the old (current) A into R R gets the previous A regardless if A is updated with B or not. To see if the update was successful a compare of R == C may be used. | 硬件辅助的原子组合操作: R = cmpxchg(A, C, B)。如果A=C,则A=B;同时R获得A上一次的值,无关前面A=C条件是否成功。所以判断操作是否成功,需要判断(R == C)? |
5.2 ring buffer的基本概念
1、工作模式
ring buffer可以工作在overwrite模式或者producer/consumer模式:
- Producer/consumer模式。在producer已经把ring buffer空间写满的情况下,如果没有consumer来读数据free空间,producer会停止写入丢弃新的数据;
- Overwrite模式。在producer已经把ring buffer空间写满的情况下,如果没有consumer来读数据free空间,producer会覆盖写入,最老的数据会被覆盖;
2、写操作
在同一个per-cpu buffer上,不能同时有两个写入者在进行写操作。但是允许高优先级的写入者中断低优先级的写入者,在返回低优先级之前高优先级写入者必须finish自己的写操作。类似下面例子的“stack写”、“嵌套写操作”。
在实际的环境中就是:普通写操作被IRQ写中断、IRQ写被NMI写中断。
1 | writer1 start |
- 读操作随时可以发生,但是同一时刻只有一个reader在工作,这其中使用了互斥操作。
- 读操作和写操作会同时发生:本cpu写入对应的per-cpu buffer,其他cpu可以同时读取这个cpu的bbbuffer;
- 读操作不会中断写操作,但是写操作会中断读操作;
- 支持两种模式的读操作:简易读,也叫iterator读,在读取时会关闭写入,且读完不会破坏数据可以重复读取,实例见”/sys/kernel/debug/tracing/trace”;并行读,也叫custom读,常用于监控程序实时的进行并行读,其利用了一个reader page交换出ring buffer中的head page,避免了读写的相互阻塞,实例见”/sys/kernel/debug/tracing/trace_pipe”;
3.1、reader page的swap:
为了支持并行读,需要使用reader_page交换出head_page。交换过程非常简单易懂,如下图:
1 | +------+ |
reader_page swap的一种极端情况:把commit_page和tail_page交换到了reader_page,这种情况不会出现异常,因为reader_page的next指针任然指向ring buffer中的下一个page。如下图:
1 | reader page commit page tail page |
4、ring buffer的主要指针
- reader page - The page used solely by the reader and is not part of the ring buffer (may be swapped in)
- head page - the next page in the ring buffer that will be swapped with the reader page.
- tail page - the page where the next write will take place.
- commit page - the page that last finished a write.
commit page指针只能被“stack写”/“嵌套写”最外层的写入者更新,抢占其他人的写入者不能移动commit page指针。
这个机制也是ringbuffer的核心机制,实现了写入的免锁:
- 在writer需要分配空间的时候,迅速的用原子操作移动tail指针,迅速的保留出空间。这样就算被高优先级的writer抢占,在操作这块空间的时候也不需要持锁,因为writer的空间都是独立的;
- 使用最外层的writer来commit空间,如果最外层的writer都已经得到操作权限,说明所有高优先级的writer都已经操作完成。commit完成后,这部分空间就可以给reader读取了;
- 如果需要丢弃空间,可以设置相应的标志,还是同样的commit,在读取过程中判断有丢弃标志则进行丢弃;
普通的写操作:
1 | Write reserve: |
被抢占的读操作:
抢占者的commit会成为pending commit,只有所有writer数据都写完的commit才是last full commit。
1 | If a write happens after the first reserve: |
4.2、指针的顺序
通常情况下,几种指针的顺序如下:head page、commit page、tail page。如下图:
1 | tail page |
tail page一直前于等于commit page,如果tail page环绕快赶上了commit page,ring buffer不能再写入任何数据了,因为没有commit的数据在任何模式下都不能overwrite,这样会引起write的逻辑混乱。
有一种特殊的情况会打断这种顺序,head page会跑到commit page、tail page之后。如下图:
1 | reader page commit page tail page |
这是并行读时,使用reader page交换出了commit page、tail page。在这种情况下,head page指针不能移动,直到commit page、tail page指针移动回到ring buffer的page当中。同样如果commit指针在reader page中,不能swap出当前reader_page到ring buffer中。
4.3、overwrite时的指针操作
- tail指针不能overwrite commit指针,因为commit处在写入的中间状态,强行overwrite会发生不可预料的结果;
- 但是tail指针可以overwrite head指针,因为是已经写入完成的数据,只是丢弃掉一些不被读取;
- tail指针会push head指针指向下一个page,然后再移动tail指针;
overwrite的过程如下:
1 | tail page |
5.3 ring buffer无锁机制的实现
任何读操作都会get一系列的锁,确保操作串行;写操作都是无锁操作,写入ring buffer。所有我们在设计机制的时候,只需要考虑“单个读取者”+“多个嵌套写入者”的场景。
在这种设定下,无锁互斥机制包含几部分:
- “嵌套write”时的无锁机制。这个在上节中已经介绍,使用commit指针来解决;(writer)
- reader_page swap时的无锁机制。基本概念在上一节介绍,本节再详细介绍一下过程;(reader)
- overwrite操作时的无锁机制。上节已经介绍,如果tail指针要赶上head指针了将要进行overwrite,写入者push head指针向前操作;(writer)
1、overwrite操作的无锁
为了支持这个机制,设计者特意制定了两个标志位:
- HEADER - the page being pointed to is a head page
- UPDATE - the page being pointed to is being updated by a writer and was or is about to be a head page.
这两个标志,使用指向head page的上一个page的->next指针的低两bit来存放。“H”和“U”标志是互斥的不会同时置位。
普通overwrite操作时,是这样来操作“H”和“U”标志的:
1 | // step 1: writer判断tail指针已经接近head指针,首先使用原子操作将“H”标志变成“U”标志。 |
1.1 commit禁止overwrite
如果某个抢占式writer的优先级过高,一直写入,造成了tail指针赶上了commit指针。如下图:
1 | reader page commit page |
这个时候唯一要做的就是:等待。不能overwrite,只能丢弃掉最新的write数据。
同理,如果reader_page中包含commit page,也不能swap出去,只能等待。
1.2、“overwrite” + “2 Nested write”
处理的过程如下:
1 | // step 1: (first writer)改动标志“H”成“U” |
1.3、“overwrite” + “3 Nested write”
处理的过程如下:
1 | // step 1: (first writer)改动标志“H”成“U” |
2、reader_page swap时的无锁
综合“H”、“U”标志,来看看swap时的无锁是怎么实现的。如下图:
1 | // step 1: 初始状态 |
2.1、判断page是否为reader page的方法
因为reader page被swap出来以后,本身的next、pre指针还指向原ring buffer中的page,但是这些page的指针已经不指向reader page了。
判断page->pre ->next是否还等于自己,如果不等于page为reader page。
1 | +--------+ |